Screaming Frog(screamingfrog.co.uk)是一款功能强大的搜索引擎优化工具,具有许多搜索引擎优化功能,其中包括自定义提取功能,可以让您轻松地从抓取中提取数据。本博文将讨论 Screaming Frog 自定义提取功能的工作原理,以及为什么它可以帮助改进搜索引擎优化工作、电子商务数字营销和索引策略。
网站上有大量有用的信息--大多数情况下,要访问网站上的每个页面,将产品数据、元数据、标题标签和锚文本复制到电子表格中,既费力又复杂。在这种情况下,Screaming Frog 使用 API 和正则表达式来自动完成自定义搜索数据提取。自定义提取是一种网络搜刮、网络采集或网络数据提取形式,用于从网站上搜刮和提取数据,使您可以将数据存储在本地计算机上。
对于初学者,你可能有一些问题。
什么是 尖叫蛙SEO蜘蛛 ? Screaming Frog SEO Spider 软件是一款网站爬虫,可通过图形用户界面(GUI)提取和分析网站的结构化数据,有效处理 XML 和 JavaScript 渲染的内容,从而提高网站的搜索引擎优化水平。
自定义提取是 Screaming Frog 的 SEO 蜘蛛从网页中提取明确信息的功能。这些提取信息有助于优化您的网站,以便进行技术性搜索引擎优化审核,包括搜索结果、收集有关副本的重要数据,以及帮助定位和修复标题和其他元素中的错误。
如果您想进行数据提取,即从您的网站上提取所需的数据,请使用 Screaming Frog。这些信息保存在 Screaming Frog 的内存中,您可以选择将扫描结果导出到 Excel 或 Google Sheets,以便进一步审查。这可能包括下拉菜单和内部链接结构中的数据。
数据提取可让您快速高效地获取大量数据。这种自动化可为您提供网络架构的即时结果。这一过程可节省您的时间和资源,同时为您提供规划和制定搜索引擎优化战略所需的宝贵数据。Screaming Frog 是搜索引擎优化人员的首选网络抓取工具和数据提取工具。它有无穷无尽的选项;这里有大量自定义网络抓取语法。请查看下面的教程。
如果您想进行数据提取,即从您的网站上提取所需的数据,请使用 Screaming Frog。这些信息保存在 Screaming Frog 的内存中,您可以选择将扫描结果导出到 Excel 或 Google Sheets 中,以便进一步查看。对于更高级的需求,您可以使用正则表达式从 HTML 或 JavaScript 渲染的内容(包括节点和片段)中精确定位和提取特定模式。
通过整合这些技术,您可以有效优化搜索引擎优化策略,利用 Screaming Frog 等工具的强大功能,甚至利用 ChatGPT 等人工智能技术获得更深入的见解。
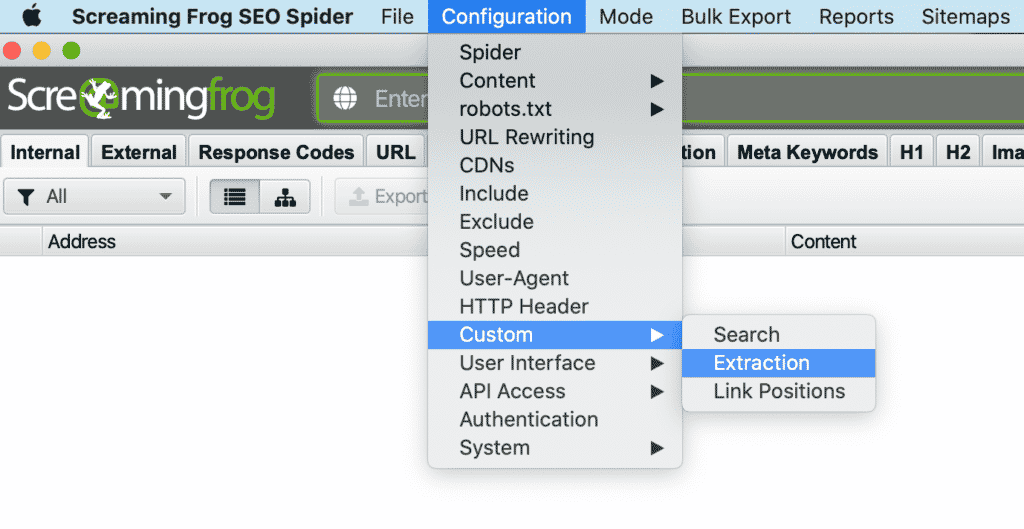
1.在ScreamingFrog中,转到 配置>自定义>提取。
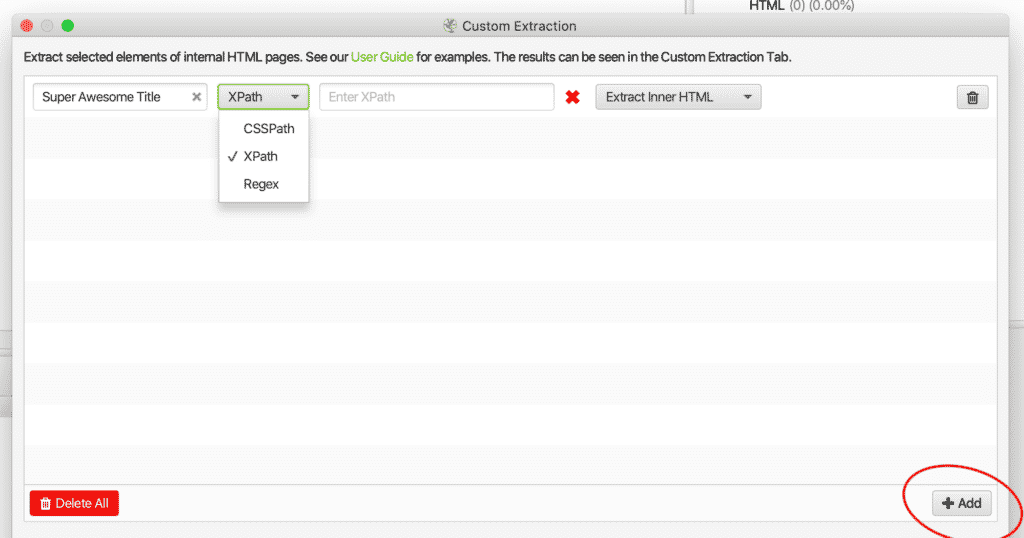
尖叫蛙定制提取 2.接下来,你将需要 +添加 并设置你的提取规则。
使用自定义提取标签选择内部HTML的元素 3.加入一个 标题 , CSSPath。 XPath
,或 Regex , 搜索功能 .
如果您不确定需要哪种选择器或函数,请查看下面的示例,或使用下列文件中的检查元素函数 谷歌浏览器开发工具 .您可以在 Google Chrome 浏览器中使用 "右键单击 "打开 "开发工具"。
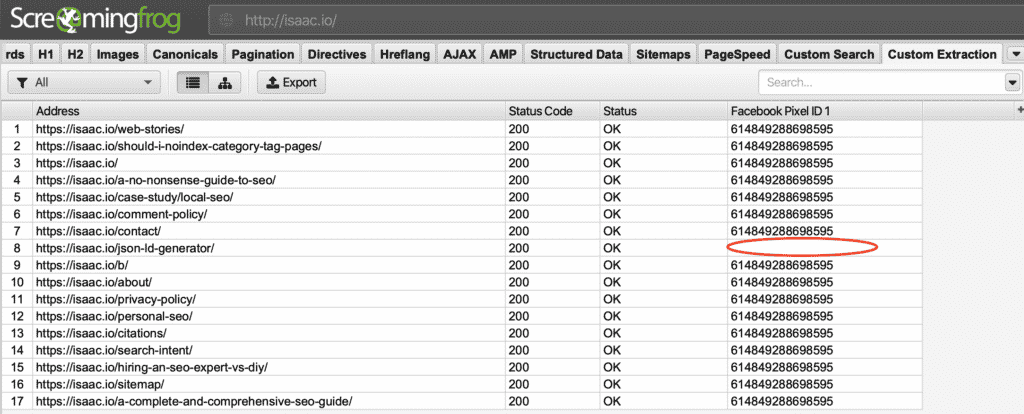
例子。 下面举例说明 刮削 获取 Facebook 像素 ID
Facebook像素ID提取 在 结果 你可以看到,我的一个页面缺少一个Facebook Pixel。
丢失的Facebook ID 下面是预定义的自定义提取数据集,可以让你开始。
使用XPath网络刮削的基本语法 SYNTAX 功能介绍 //在文件的任何地方进行搜索 /的根部内搜索。 网站 @选择一个元素的特定属性 *通配符用于选择任何元素 [ ]找到一个特定的元素 .指定当前元素 ..指定父元素
XPath 职能XPATH 输出 //h1提取所有H1标签 //h2[1]提取第一个H2标签 //h2[2]提取第二个H2标签 //div/p提取任何 <p> 包含在一个 <div> //div[@class='author']提取任何 <div> 与类 "作者" //p[@class='content']提取任何 <p> 与 "内容 "类 //*[@class='content']提取任何具有 "content "类的元素 //ul/li[last()]提取 //ol[@class='cat']/li[1]。提取类为 "cat "的中的第一个。 count(//h2)计算H2的数量(设置提取过滤器为 "函数值")。 /a[包含(.,'了解更多')]提取任何含有 "了解更多 "锚文本的链接 /a[以@title,'written by'开头]提取任何标题以 "撰写者 "开头的链接。
XPATH 输出 //@href提取所有链接 //a[starts-with(@href,'mailto')]/@href提取以 "mailto:"(电子邮件地址)开头的链接。 //a[starts-with(@href,'tel')]/@href提取以 "tel:"(电话号码)开头的链接 //img/@src提取所有图像源URL //img[包含(@class,'aligncenter')]/@src提取包含类名 "aligncenter "的图像的所有图像源URL。 //link[@rel='alternate']提取rel属性设置为 "alternate "的元素。 //@hreflang提取所有hreflang值
XPATH 输出 //meta[@property='article:published_time']/@content提取文章发布日期(WordPress网站上常见的元标签)。
XPATH 输出 //meta[@property='og:type']/@content提取Open Graph类型的对象 //meta[@property='og:image']/@content提取Open Graph特色图片的URL //meta[@property='og:uped_time']/@content提取Open Graph的更新时间
XPATH 输出 //meta[@name='twitter:card']/@content提取Twitter卡的类型 //meta[@name='twitter:title']/@content提取Twitter卡片的标题 //meta[@name='twitter:site']/@content提取Twitter卡片站点对象(Twitter手柄)。
XPATH 输出 //*[@itemtype]/@itemtype提取一个页面上所有类型的模式标记
这里是你用来检查面包屑的自定义提取,在 尖叫的青蛙 .
XPATH 输出 //*[包含(@itemtype,'BreadcrumbList')]/*[@itemprop]/a/@href提取所有面包屑链接 //*[包含(@itemtype,'BreadcrumbList')]/*[@itemprop][1]/a/@href提取第一个面包屑链接 //*[包含(@itemtype,'BreadcrumbList')]/*[@itemprop]提取面包屑名称(设置提取过滤器为 "提取文本")。 count(//*[包含(@itemtype,'BreadcrumbList')]/*[@itemprop])计算面包屑列表项目的数量(设置提取过滤器为 "功能值")。
XPATH 输出 //*[@itemprop='name']/@content提取产品名称 //*[@itemprop='description']/@content提取产品描述 //*[@itemprop='price']/@content提取产品价格 //*[@itemprop='priceCurrency']/@content提取产品货币 //*[@itemprop='可用性']/@href提取产品的可用性 //*[@itemprop='sku']/@content提取产品SKU
XPATH 输出 //*[@itemprop='reviewCount']提取审查数 //*[@itemprop='ratingValue']提取评级值 //*[@itemprop='bestRating']提取最佳评论评级 //*[@itemprop='回顾']/*[@itemprop='名称']提取审查名称 //*[@itemprop='评论']/*[@itemprop='作者']摘录评论作者 //*[@itemprop='review']/*[@itemprop='datePublished']/@content提取评论的发布日期 //*[@itemprop='review']/*[@itemprop='reviewBody']提取评论的正文内容
XPATH 输出 //*[包含(@itemtype,'Organization')]/*[@itemprop='name']提取该组织的名称 //*[@itemprop='地址']/*[@itemprop='街道地址']提取街道地址 //*[@itemprop='address']/*[@itemprop='addressLocality']提取地址位置 //*[@itemprop='地址']/*[@itemprop='地址区域']提取地址区域 //*[@itemprop='电话']提取 电话号码 //*[@itemprop='sameAs']/@href提取 "同为 "链接
提取文章模式 XPATH 输出 //*[包含(@itemtype,'Article')]/*[@itemprop='headline']提取文章的标题 //*[@itemprop='author']/*[@itemprop='name']/@content提取作者姓名 //*[@itemprop='出版商']/*[@itemprop='姓名']/@内容提取出版商名称 //*[@itemprop='datePublished']/@content摘录出版日期 //*[@itemprop='dateModified']/@content提取修改日期
野生动物 SYNTAX 功能介绍 .匹配任何1个字符 *匹配前面的字符0次或更多次 ?匹配前面的字符0或1次 +匹配前面的字符1次或更多次 |或
锚点 SYNTAX 功能介绍 ^字符串从后续的字符开始。 $该字符串以前面的字符结束。
群体 SYNTAX 功能介绍 ( )按照准确的顺序匹配所附的字符 [ ]以任何顺序匹配所包围的字符 -匹配指定范围内的任何字符
逃离 SYNTAX 功能介绍 \按字面意思处理字符,而不是作为regex。
REGEX 输出 ["'](ua-.*?) ["']提取谷歌分析的跟踪ID ["'](G-.*?)["']提取谷歌分析4(GA4)的跟踪ID ["'](aw-.*?) ["']提取谷歌广告转换ID和/或再营销标签 ["'](gtm-.*?)["']提取谷歌标签管理器和/或谷歌优化的ID fbq\(["']init["'], ["'](.*?)["']提取Facebook Pixel ID \{ti:["'](.*?)["']}提取Bing Ads的UET标签 adroll_adv_id = ["'](.*?) ["']提取AdRoll广告商ID adroll_pix_id = ["'](.*?) ["']提取AdRoll Pixel ID
提取所有模式标记和模式类型 REGEX 输出 ["']application/ld/+json["']>(.*?)/script>提取所有的JSON-LD模式标记 ["']@type["']。*["'](.*?)["']提取一个页面上所有类型的JSON-LD模式标记
REGEX 输出 ["']项目["']。*{["']@id["']。*["'](.*?)["']提取面包屑链接 ["']项目["']。*{["']@id["']。*["'].*?["'], *["']name["']。*["'](.*?)["']提取面包屑名称
REGEX 输出 ["']@type["']。*["']Product["'].*?["']name["']:*["'](.*?)["']提取产品名称 ["']@type["']。*["']Product["'].*?["']description["']:*["'](.*?)["']提取产品描述 ["']@type["']。*["']Product["'].*?["']price["']:*["'](.*?)["']提取产品价格 ["']@type["']。*["']Product["'].*?["']priceCurrency["']:*["'](.*?)["']提取产品货币 ["']@type["']。*["']Product["'].*?["']availability["']:*["'](.*?)["']提取产品的可用性 ["']@type["']。*["']Product["'].*?["']sku["']:*["'](.*?)["']提取产品SKU
REGEX 输出 ["']reviewCount["']。*["'](.*?)["']提取审查数 ["']ratingValue["']。*["'](.*?)["']提取评级值 ["']bestRating["']。*["'](.*?)["']提取最佳评级
REGEX 输出 ["']@类型["']。*["']Organization["'].*?["']name["']:*["'](.*?)["']提取组织名称 ["']streetAddress["']。*["'](.*?)["']提取街道地址 ["']addressLocality["']。*["'](.*?)["']提取地址位置 ["']addressRegion["']。*["'](.*?)["']提取地址区域 ["']电话["']。*["'](.*?)["']提取电话号码 ["']sameAs["']。*\[(.*?)\]提取 "同为 "链接
提取文章或BlogPosting模式 REGEX 输出 ["']头条["']。*["'](.*?)["']摘录文章标题 ["']author["'].*?["']name["']:*["'](.*?)["']提取作者姓名 ["']publisher["'].*?["']name["']:*["'](.*?)["']提取出版商名称 ["']datePublished["']。*["'](.*?)["']摘录出版日期 ["']dateModified["']。*["'](.*?)["']提取修改日期
这种可能性是无穷无尽的;如果你想在这个列表中加入任何提取物,请让我知道。
发表于:2021-03-10
Isaac Adams-Hands是SEO North公司的SEO总监,该公司提供搜索引擎优化服务。作为一名搜索引擎优化专家,Isaac在网页搜索引擎优化、非网页搜索引擎优化和技术性搜索引擎优化方面拥有相当丰富的专业知识,这使他在竞争中占据了优势。