Hogar > La Rana Gritona > Extracciones personalizadas de Screaming Frog: Guía para la extracción de datos de rastreo
Extracciones personalizadas de Screaming Frog: Guía para la extracción de datos de rastreo
Screaming Frog (screamingfrog.co.uk) es una potente herramienta SEO con muchas características de optimización de motores de búsqueda, incluyendo extracciones personalizadas, que le permiten extraer datos de sus rastreos fácilmente. Esta entrada de blog discutirá cómo funciona Screaming Frog Custom Extraction y por qué puede ayudar a mejorar sus esfuerzos de SEO, marketing digital de comercio electrónico y estrategias de indexación.
Los sitios web tienen una tonelada de información útil - la mayoría de las veces, es demasiado laborioso o complicado visitar cada página de un sitio web para copiar los datos del producto, metadatos, etiquetas de título y texto de anclaje en una hoja de cálculo. Aquí es donde Screaming Frog viene al rescate con extracciones de datos de búsqueda personalizadas, utilizando API y expresiones regulares para automatizar el proceso. Las extracciones personalizadas son una forma de raspado web, recolección web o extracción de datos web que se utiliza para raspar y extraer datos de sitios web, lo que le permite almacenarlos localmente en su ordenador.
Para los principiantes, algunas preguntas que pueden tener:
El software Screaming Frog SEO Spider es un rastreador de sitios web que mejora el SEO in situ extrayendo y analizando los datos estructurados de su sitio web mediante una interfaz gráfica de usuario (GUI), manejando eficazmente el contenido XML y JavaScript.
¿Cuáles son extracciones personalizadas?
Las extracciones personalizadas son funciones de la araña SEO de Screaming Frog para extraer información explícita de las páginas web. Estas extracciones ayudan a optimizar su sitio para una auditoría SEO Técnica, incluyendo resultados de búsqueda, recopilando datos esenciales sobre su copia, y ayudando a localizar y corregir errores en encabezados y otros elementos.
¿Cómo se hace la extracción de datos?
Utilice Screaming Frog si desea procesar la extracción de datos, que consiste en extraer los datos necesarios de su sitio web. La información se guarda dentro de la memoria de Screaming Frog, dándole la opción de exportar los resultados escaneados a Excel o Google Sheets para su posterior revisión. Esto puede incluir datos de menús desplegables y estructuras de enlaces internos.
¿Por qué es fundamental la extracción de datos?
La extracción de datos le permite recoger grandes cantidades de datos de forma rápida y eficaz. Esta automatización le proporciona resultados inmediatos de arquitectura web. Este proceso le ahorra tiempo y recursos mientras que le da los datos valiosos que necesitará para planificar y elaborar estrategias de optimización de motores de búsqueda. Screaming Frog es el go-to Web Scraper Tool para SEOs y un extractor de datos. Las opciones son infinitas; aquí hay un montón de sintaxis personalizadas de web-scraping. Echa un vistazo al tutorial a continuación.
Cómo extraer datos personalizados con Screaming Frog
Utilice Screaming Frog si desea procesar la extracción de datos, que consiste en extraer los datos necesarios de su sitio web. La información se guarda en la memoria de Screaming Frog, dándole la opción de exportar los resultados escaneados a Excel o Google Sheets para su posterior revisión. Para necesidades más avanzadas, puede incorporar expresiones regulares para apuntar con precisión y extraer patrones específicos de su contenido HTML o JavaScript renderizado, incluyendo nodos y fragmentos.
Al integrar estas técnicas, puede optimizar su estrategia SEO de forma eficaz, aprovechando la potencia de herramientas como Screaming Frog e incluso utilizando tecnologías de IA como ChatGPT para obtener información más profunda.
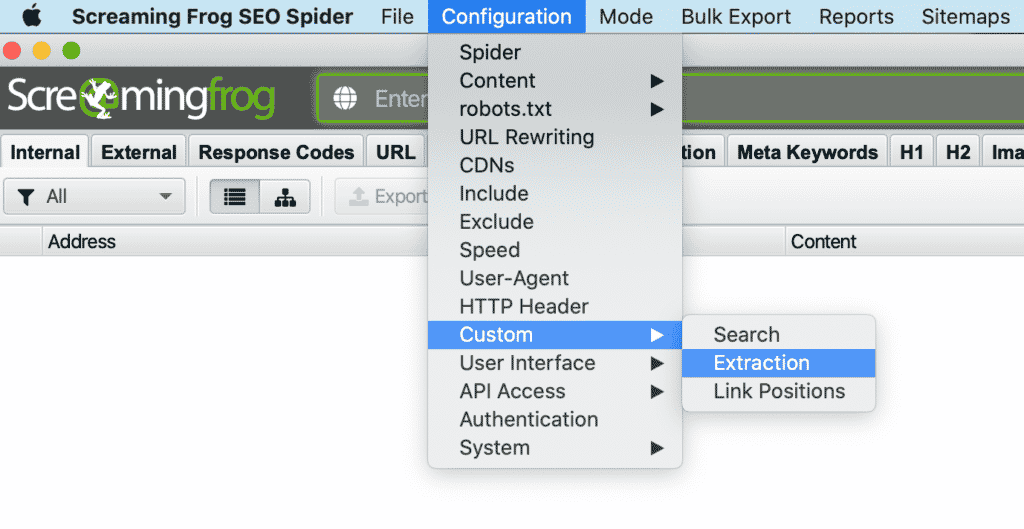
1. En ScreamingFrog, vaya a Configuración > Personalizada > Extracción.
Extracción personalizada de Screaming Frog
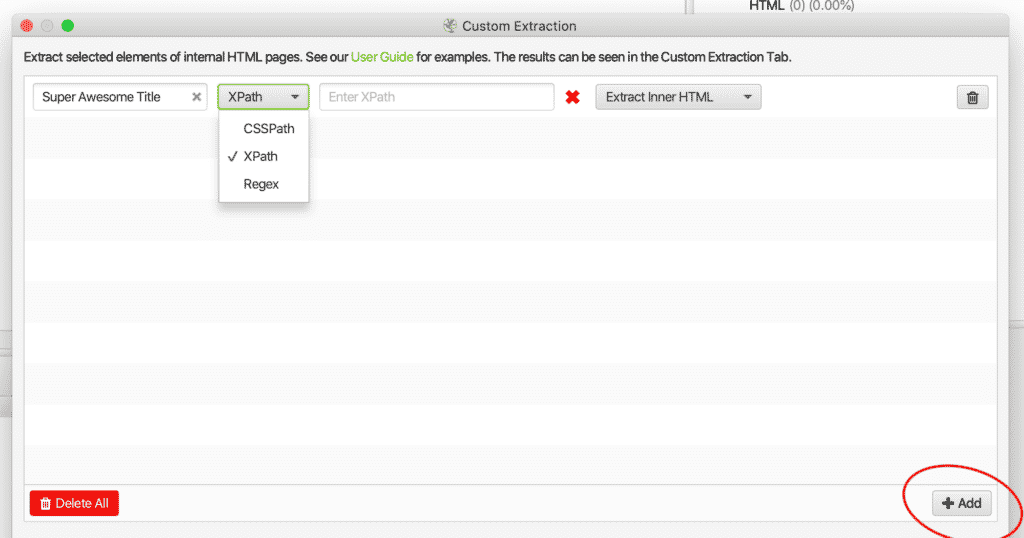
2. A continuación, deberá +Añadir y configure sus reglas de extracción.
Seleccionar elementos de HTML interno mediante la pestaña de Extracción Personalizada
3. Añade un Título, 4. Seleccione si necesita CSSPath, XPatho Regex, 5. Añade tu función de búsqueda.
Si no está seguro de qué selector o función necesita, consulte los ejemplos siguientes o utilice la función de inspección de elementos en Herramientas de desarrollo de Google Chrome. Puede abrir Dev Tools haciendo "clic con el botón derecho" en el navegador Google Chrome.
Ejemplo:
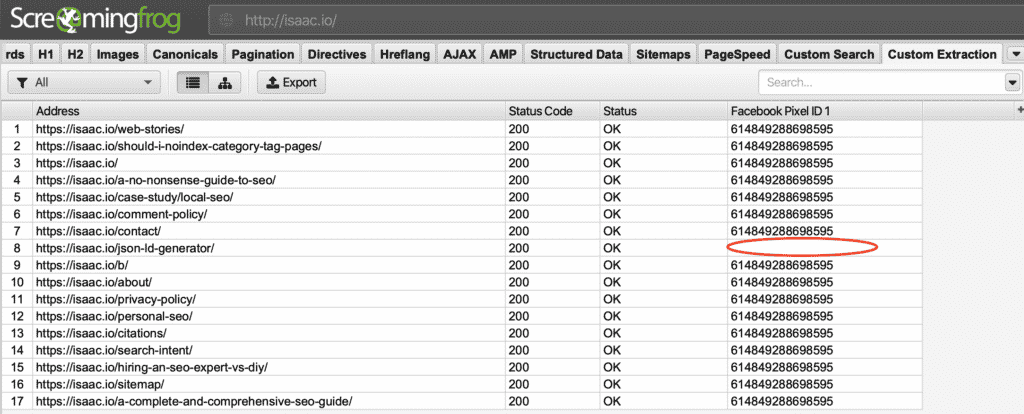
He aquí un ejemplo raspar para un ID de píxel de Facebook
Extracción del ID del píxel de Facebook
En el ResultadosComo puedes ver, a una de mis páginas le falta un píxel de Facebook:
Falta el ID de Facebook
A continuación encontrará conjuntos de datos de extracción personalizados predefinidos para que pueda empezar.
Isaac Adams-Hands es el director de SEO en SEO North, una empresa que ofrece servicios de optimización de motores de búsqueda. Como profesional de SEO, Isaac tiene una considerable experiencia en SEO On-page, SEO Off-page y SEO Técnico, lo que le da una ventaja frente a la competencia.