The rise of artificial intelligence (AI) has led to an increase in web scraping using AI crawlers, where bots automatically extract data from websites. While web scraping can have legitimate uses, it can also be used to steal content and data without permission. As a website owner, it is important to protect your content and privacy by blocking AI from scraping your website.

One way to block AI bots from scraping your website is using the robots.txt file. This file tells search engines and other bots which pages they are allowed to access on your website. By adding specific instructions to the file, you can block AI bots from accessing your website and scraping your content. However, it is important to note that not all AI bots will follow the instructions in the robots.txt file.
Table of Contents
Creating Effective robots.txt Directives
To create effective robots.txt directives, webmasters should understand the syntax of the file. The directives are composed of two main parts: the user-agent and the disallow directive. The user-agent specifies which bot the directive applies to, while the disallow directive specifies which pages or sections of the website should not be crawled or indexed.
For instance, in the first example below, to block Common Crawl’s bot, which is called CCBot, the following code can be added to the robots.txt file:
# Common Crawl's bot - Common Crawl is one of the largest public datasets used by AI for training, with ChatGPT, Bard and other large language models.
User-agent: CCBot
Disallow: /
# ChatGPT Bot - bot used when a ChatGPT user instructs it to reference your website.
User-agent: ChatGPT-User
Disallow: /
# OpenAI API - bot that OpenAI specifically uses to collect bulk training data from your website for ChatGPT.
User-agent: GPTBot
Disallow: /
# Google Bard and VertexAI. This will not have an impact on Google Search indexing. This will not affect GoogleBot crawling.
User-agent: Google-Extended
Disallow: /
# Anthropic AI Bot
User-agent: anthropic-ai
Disallow: /
# Claude Bot run by Anthropic
User-agent: Claude-Web
Disallow: /
# Cohere AI Bot - unconfirmed bot believed to be associated with Cohere’s chatbot.
User-agent: cohere-ai
Disallow: /
# OMGilibot - They sell data for training LLMs (large language models)
User-agent: omgilibot
Disallow: /
# Omgili (Oh My God I Love It)
User-agent: omgili
Disallow: /
# Perplexity AI
User-agent: PerplexityBot
Disallow: /
# KUKA's youBot
User-agent: YouBot
Disallow: /
# Diffbot - somewhat dishonest scraping bot used to collect data to train LLMs.
User-agent: Diffbot
Disallow: /
# Bytespider is a web crawler operated by ByteDance, the Chinese owner of TikTok
User-agent: Bytespider
Disallow: /
# ImagesiftBot is billed as a reverse image search tool, but it's associated with The Hive, a company that produces models for image generation.
User-agent: ImagesiftBot
Disallow: /
## Social Media Bots
# Amazon Bot - enabling Alexa to answer even more questions for customers.
User-agent: Amazonbot
Disallow: /
# Apple Bot - collects website data for its Siri and Spotlight services.
User-agent: Applebot
Disallow: /
# Meta’s bot that crawls public web pages to improve language models for their speech recognition technology.
User-agent: FacebookBot
Disallow: /
These will instruct the bots not to crawl or index any page on the website.
However, not all bots follow the directives specified in the robots.txt file. Some bots may ignore the file altogether and crawl the website anyway. Therefore, webmasters should not solely rely on robots.txt to block bots from scraping their content.
Limitations of robots.txt Protocol
While the robots.txt protocol is effective in blocking bots from crawling and indexing specific pages or sections of a website, it has its limitations.

Firstly, the protocol only applies to legitimate bots that follow the rules specified in the file. Malicious bots that ignore the file can still scrape the website’s content.
Secondly, the protocol does not provide any security measures to prevent bots from accessing the website’s content. In other words, bots can still access the website’s content, but they will not be able to crawl or index it.
Advanced Strategies for Protecting Content
There are several advanced strategies available for protecting your content from being scraped by AI. In this section, we will discuss some of the most effective methods for safeguarding your website content.
Implementing Advanced Meta Tags
Meta tags are a powerful tool for controlling how search engines and other bots interact with your website. By adding specific meta tags to your site’s HTML code, you can limit access to certain pages or sections of your site, block bots from indexing your site altogether, or even specify which bots are allowed to access your content.
<meta name="robots" content="noai, noimageai">One particularly effective meta tag for blocking AI bots is the “noai” tag. This tag tells search engines not to index a particular page or section of your site, which can help prevent bots from scraping your content. Another useful tag is the “noimageai” tag, which prevents search engines from using your images to generate ai images.

Leveraging CDN Bot Detection (CloudFlare)
Content Delivery Networks (CDNs) are a popular tool for speeding up website loading times by caching content on servers located around the world. Many CDNs, like Cloudflare also include bot detection features, which can help identify and block malicious bots from accessing your site.
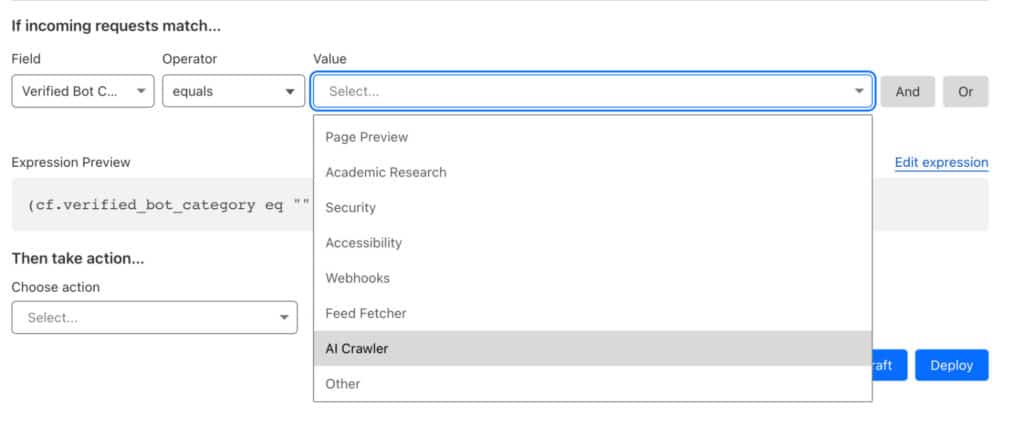
To enable this, log in to the Cloudflare dash, go to the WAF tab, create a rule, and choose one of the Verified Bot sub categories as the Field.
By leveraging CDN bot detection, you can block bots from scraping your content before they even reach your server. This can help reduce server load and protect your content from being stolen.
Utilizing .htaccess for Enhanced Control
The .htaccess file is a powerful configuration file used by Apache web servers to control various aspects of website behavior. By editing your site’s .htaccess file, you can implement a wide range of advanced security measures, including blocking specific IP addresses or user agents.

For example, you can use .htaccess to block access to your site from known AI bots like ChatGPT and Google Bard. You can also use .htaccess to restrict access to certain pages or sections of your site based on user agent or IP address.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (CCBot|ChatGPT|GPTBot|anthropic-ai|Omgilibot|Omgili|FacebookBot|Diffbot|Bytespider|ImagesiftBot|cohere-ai) [NC]
RewriteRule ^ – [F]Conclusion
Protecting your website’s content from AI-driven web scraping is essential in the digital age, where data and content theft are rampant. Utilizing the robots.txt file to specify access restrictions is a fundamental step, but it’s not foolproof, as not all bots comply with these directives. Therefore, webmasters must adopt a multi-layered defense strategy. This includes leveraging advanced meta tags, employing CDN bot detection mechanisms like Cloudflare, and configuring server-level restrictions using the .htaccess file. By combining these methods, website owners can better safeguard their content from unauthorized scraping, ensuring that their digital assets remain protected and their website’s integrity is maintained. Ultimately, the goal is to create a secure online environment that respects the boundaries of content ownership and promotes fair use of digital resources.
FAQ
How to Block AI from Scraping Your Content
Does blocking AI from Scraping your website improve SEO?
Published on: 2024-04-05
Updated on: 2026-02-05