Accueil > Grenouille hurlante > Screaming Frog Custom Extractions : Un guide pour l'extraction des données de crawl
Screaming Frog Custom Extractions : Un guide pour l'extraction des données de crawl
Screaming Frog (screamingfrog.co.uk) est un outil de référencement puissant qui offre de nombreuses fonctionnalités d'optimisation pour les moteurs de recherche, notamment les extractions personnalisées, qui vous permettent d'extraire facilement des données de vos crawls. Cet article de blog explique comment fonctionne l'extraction personnalisée de Screaming Frog et pourquoi elle peut vous aider à améliorer vos efforts de référencement, votre marketing numérique de commerce électronique et vos stratégies d'indexation.
Les sites Web contiennent une tonne d'informations utiles. La plupart du temps, il est trop laborieux ou compliqué de visiter chaque page d'un site Web pour copier les données produit, les métadonnées, les balises de titre et le texte d'ancrage dans une feuille de calcul. C'est là que Screaming Frog vient à la rescousse avec des extractions de données de recherche personnalisées, en utilisant des API et des expressions régulières pour automatiser le processus. Les extractions personnalisées sont une forme de web scraping, de web harvesting ou d'extraction de données web utilisée pour récupérer et extraire des données de sites web, ce qui vous permet de les stocker localement sur votre ordinateur.
Pour les débutants, quelques questions que vous pourriez vous poser :
Le logiciel Screaming Frog SEO Spider est un robot d'exploration de sites web qui améliore le référencement sur site en extrayant et en analysant les données structurées de votre site web à l'aide d'une interface utilisateur graphique (GUI), en gérant efficacement les contenus XML et JavaScript.
Quels sont les extractions sur mesure?
Les extractions personnalisées sont des fonctions de l'araignée SEO de Screaming Frog qui permettent d'extraire des informations explicites des pages Web. Ces extractions aident à optimiser votre site pour un audit SEO technique, y compris les résultats de recherche, en recueillant des données essentielles sur votre copie, et en aidant à localiser et à corriger les erreurs dans les en-têtes et d'autres éléments.
Comment se fait l'extraction des données ?
Utilisez Screaming Frog si vous souhaitez procéder à l'extraction de données, qui consiste à extraire les données requises de votre site web. Les informations sont enregistrées dans la mémoire de Screaming Frog, ce qui vous permet d'exporter les résultats de l'analyse vers Excel ou Google Sheets pour un examen plus approfondi. Il peut s'agir de données provenant de menus déroulants et de structures de liens internes.
Pourquoi l'extraction de données est-elle essentielle ?
L'extraction de données vous permet de récolter de grandes quantités de données rapidement et efficacement. Cette automatisation vous donne des résultats immédiats sur l'architecture web. Ce processus vous permet d'économiser du temps et des ressources tout en vous fournissant les données précieuses dont vous avez besoin pour planifier et élaborer des stratégies d'optimisation pour les moteurs de recherche. Screaming Frog est l'outil de scraper Web le plus utilisé par les référenceurs et un extracteur de données. Les options sont infinies ; il y a une tonne de syntaxes de web-scraping personnalisées. Consultez le tutoriel ci-dessous.
Comment extraire des données personnalisées avec Screaming Frog ?
Utilisez Screaming Frog si vous souhaitez procéder à l'extraction de données, qui consiste à extraire les données requises de votre site web. Les informations sont enregistrées dans la mémoire de Screaming Frog, ce qui vous permet d'exporter les résultats de l'analyse vers Excel ou Google Sheets pour un examen plus approfondi. Pour des besoins plus avancés, vous pouvez incorporer des expressions régulières afin de cibler et d'extraire avec précision des modèles spécifiques à partir de votre contenu HTML ou JavaScript, y compris les nœuds et les snippets.
En intégrant ces techniques, vous pouvez optimiser votre stratégie de référencement de manière efficace, en tirant parti de la puissance d'outils tels que Screaming Frog et même en utilisant des technologies d'IA telles que ChatGPT pour obtenir des informations plus approfondies.
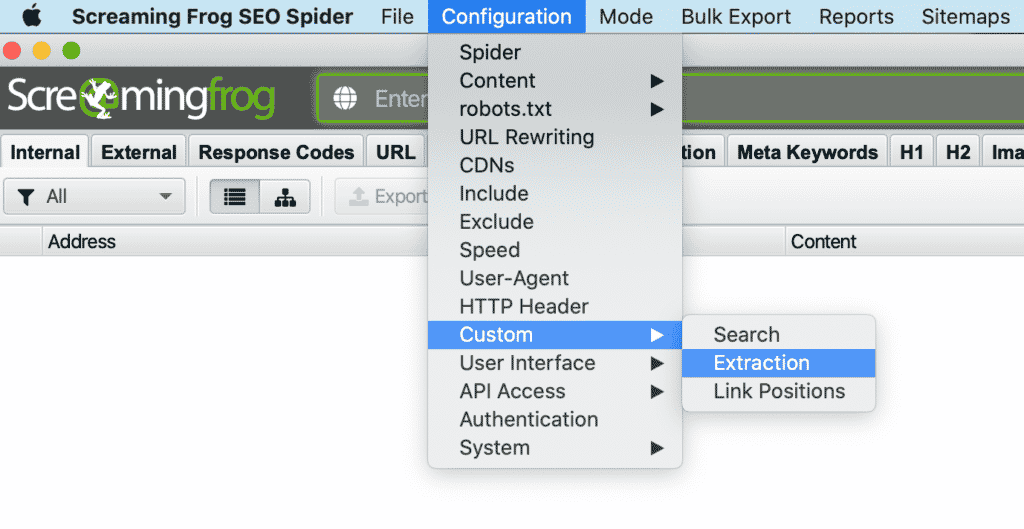
1. Dans ScreamingFrog, allez dans Configuration > Personnalisée > Extraction.
Extraction personnalisée Screaming Frog
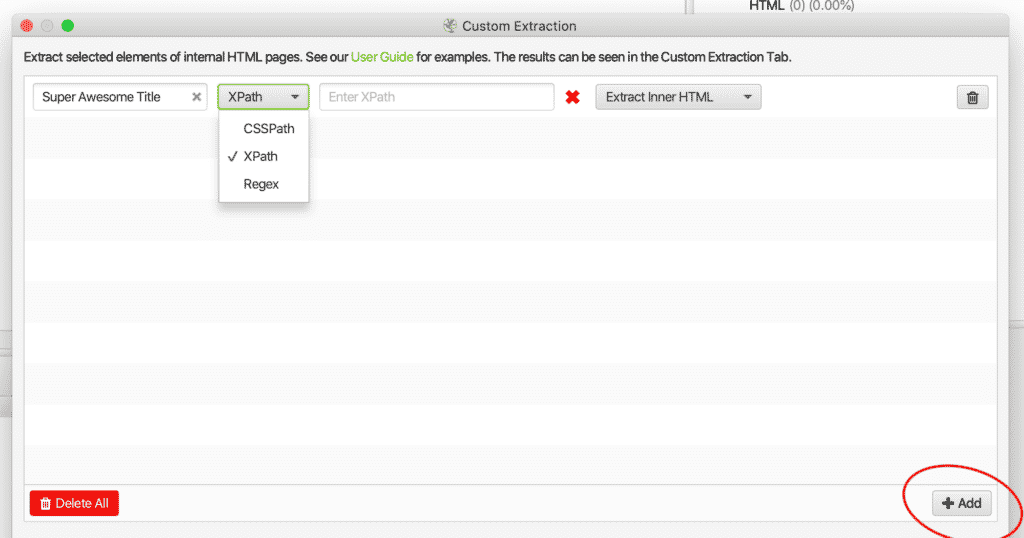
2. Ensuite, vous devrez +Ajouter et configurez vos règles d'extraction.
Sélectionner des éléments du HTML interne à l'aide de l'onglet Extraction personnalisée
3. Ajoutez un Titre, 4. Sélectionnez si vous avez besoin de CSSPath, XPathou Regex, 5. Ajoutez votre fonction de recherche.
Si vous n'êtes pas sûr du sélecteur ou de la fonction dont vous avez besoin, regardez les exemples ci-dessous ou utilisez la fonction inspecter l'élément dans la rubrique Outils de développement Google Chrome. Vous pouvez ouvrir les outils de développement en cliquant avec le bouton droit de la souris dans le navigateur Google Chrome.
Exemple :
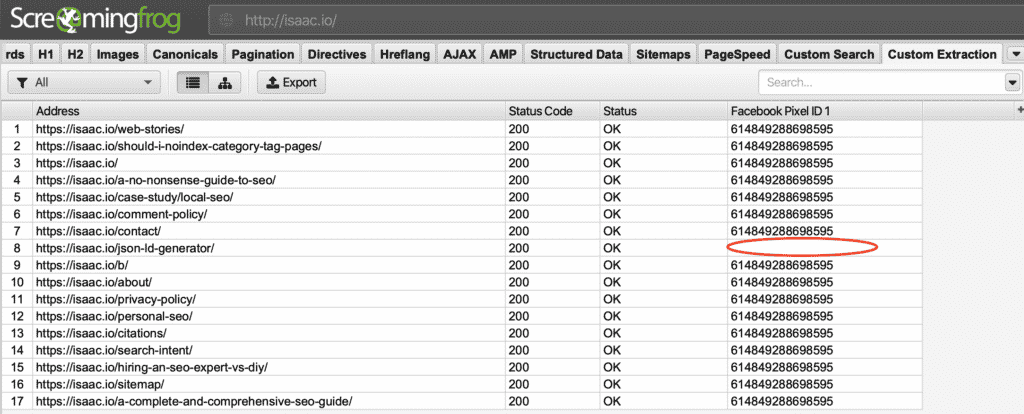
Voici un exemple de la façon de procéder gratter pour un identifiant de pixel Facebook
Extraction de l'ID du pixel Facebook
Dans le RésultatsComme vous pouvez le constater, il manque un pixel Facebook sur l'une de mes pages :
Identifiant Facebook manquant
Vous trouverez ci-dessous des ensembles de données d'extraction personnalisés prédéfinis pour vous aider à démarrer.
Syntaxe de base pour l'utilisation de XPath Web Scraping
Isaac Adams-Hands est le directeur du référencement chez SEO North, une entreprise qui fournit des services d'optimisation des moteurs de recherche. En tant que professionnel du référencement, Isaac possède une expertise considérable en matière de référencement sur page, de référencement hors page et de référencement technique, ce qui lui donne une longueur d'avance sur la concurrence.