Screaming Frog(screamingfrog.co.jp)は、クロールから簡単にデータを抽出できるカスタム抽出を含む、多くの検索エンジン最適化機能を備えた強力なSEOツールです。このブログ記事では、Screaming Frogのカスタム抽出がどのように機能するのか、そしてなぜSEOの取り組み、eコマースのデジタルマーケティング、インデックス戦略を改善するのに役立つのかについて説明します。

ほとんどの場合、製品データ、メタデータ、タイトルタグ、アンカーテキストをスプレッドシートにコピーするためにウェブサイトのすべてのページを訪問するのは、手間がかかりすぎたり、複雑すぎたりします。そこでScreaming Frogは、APIと正規表現を使ってプロセスを自動化し、カスタム検索データ抽出を提供します。カスタム抽出は、ウェブスクレイピング、ウェブハーベスティング、ウェブデータ抽出の一種で、ウェブサイトからデータをスクレイピングして抽出し、コンピュータにローカルに保存するために使用されます。
初心者の方へ、疑問に思うことを。
とは何ですか? Screaming Frog SEO Spider?
Screaming Frog SEO Spiderソフトウェアは、グラフィカルユーザーインターフェース(GUI)を使ってウェブサイトの構造化データを抽出・分析し、XMLやJavaScriptでレンダリングされたコンテンツを効果的に処理することで、オンサイトSEOを改善するウェブサイトクローラーです。
カスタム抽出は、ウェブページから明確な情報を抽出するScreaming FrogのSEOスパイダー機能です。これらの抽出は、検索結果を含むテクニカルSEO監査のためにサイトを最適化し、コピーに関する重要なデータを収集し、ヘッダーやその他の要素のエラーを見つけ修正するのに役立ちます。
ウェブサイトから必要なデータを引き出すデータ抽出処理を行いたい場合は、Screaming Frogをご利用ください。情報はScreaming Frogのメモリ内に保存され、さらに検討するためにスキャンした結果をExcelやGoogle Sheetsにエクスポートするオプションがあります。これには、ドロップダウンメニューや内部リンク構造からのデータも含まれます。
データ抽出により、大量のデータを迅速かつ効率的に採取することができます。この自動化により、ウェブ・アーキテクチャの結果を即座に得ることができます。このプロセスは、検索エンジン最適化戦略を計画し戦略を立てるために必要な貴重なデータを提供しながら、時間とリソースを節約します。Screaming Frogは、SEO担当者のためのウェブスクレイパーツールであり、データ抽出ツールです。オプションは無限大で、ここには大量のカスタムウェブスクレイピング構文があります。以下のチュートリアルをご覧ください。
ウェブサイトから必要なデータを引き出すデータ抽出を処理したい場合は、Screaming Frogをご利用ください。情報はScreaming Frogのメモリ内に保存され、さらに確認するためにスキャンした結果をExcelやGoogle Sheetsにエクスポートするオプションがあります。より高度なニーズには、ノードやスニペットを含むHTMLやJavaScriptでレンダリングされたコンテンツから特定のパターンを正確にターゲットとし、抽出するために正規表現を組み込むことができます。
これらのテクニックを統合することで、SEO戦略を効果的に最適化し、Screaming Frogのようなツールのパワーを活用し、さらにはChatGPTのようなAIテクノロジーを活用してより深い洞察を得ることができる。
1.ScreamingFrogで、次のページに進みます。 設定」→「カスタム」→「抽出」。
 スクリーミングフロッグ カスタムエクストラクション
スクリーミングフロッグ カスタムエクストラクション
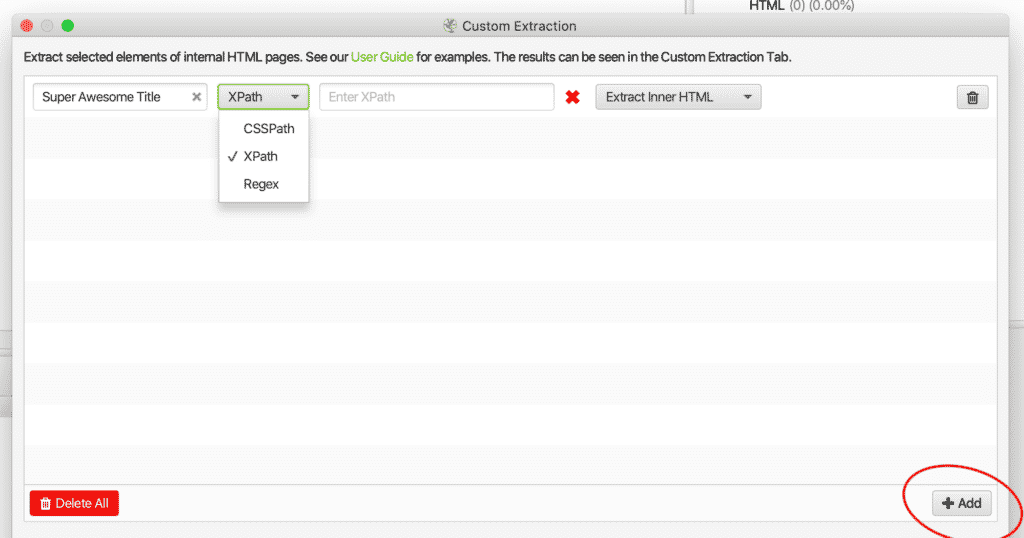
2.次に、次のことを行います。 +Add をクリックし、抽出ルールを設定します。
 カスタム抽出タブで内部HTMLの要素を選択する
カスタム抽出タブで内部HTMLの要素を選択する
3.を追加する。 タイトル,
4.必要な場合は選択してください。 CSSPathです。 エクスパットまたは レジェックス,
5.を追加します。 検索機能.
どのセレクタや関数が必要なのかわからない場合は、以下の例を見るか、あるいは グーグルクロームデバイスツール.グーグル・クローム・ブラウザの「右クリック」でDev Toolsを開くことができます。
例
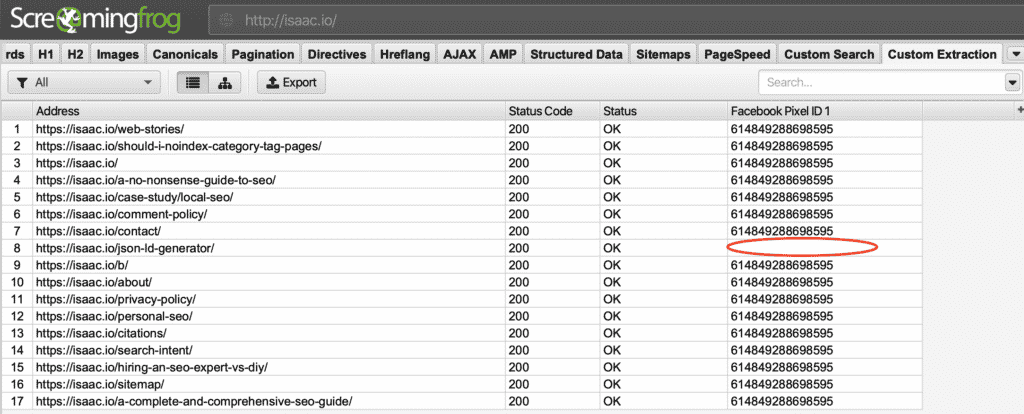
以下はその例である。 擦れ FacebookピクセルID
 FacebookピクセルID抽出
FacebookピクセルID抽出
での 結果ご覧の通り、私のページの1つにはFacebook Pixelがありません。
 Facebook IDの紛失
Facebook IDの紛失
以下は、あらかじめ定義されたカスタム抽出データセットです。
XPath Webスクレイピングを利用するための基本的な構文
| シンタックス | 機能 |
|---|
// | 文書内の任意の場所を検索 |
/ | のルート内を検索します。 ウェブサイト |
@ | 要素の特定の属性を選択する |
* | ワイルドカードは任意の要素を選択するために使用されます |
[ ] | 特定の要素を検索する |
. | 現在の要素を指定する |
.. | 親要素を指定する |
| |
エクスパット 機能
| エックスパス | OUTPUT |
|---|
//h1 | すべてのH1タグを抽出する |
//h2[1] | 最初のH2タグを抽出する |
//h2[2] | 2つ目のH2タグを抽出する |
//div/p | を抽出します。 <p> に含まれる。 <div> |
//div[@class='author']です。 | を抽出します。 <div> クラス "author "を持つ |
//p[@class='content']です。 | を抽出します。 <p> クラス "コンテンツ "を持つ |
//*[@class='content']. | クラス "content" を持つ任意の要素を抽出する。 |
//ul/li[last()]の場合 | |
//ol[@class='cat']/li[1]です。 | クラス "cat "を持つ内の最初の- を抽出する。
|
カウント(//h2) | H2の数を数える(抽出フィルターを「関数値」に設定する) |
//a[contains(.,'learn more')]]. | "learn more" を含むアンカーテキストを持つリンクを抽出します。 |
//a[starts-with(@title,'Written by')]. | "Written by "で始まるタイトルを持つリンクを抽出します。 |
| |
| エックスパス | OUTPUT |
|---|
//参照 | すべてのリンクを抽出する |
//a[starts-with(@href,'mailto')]/@href | mailto:」(メールアドレス)で始まるリンクを抽出します。 |
//a[starts-with(@href,'tel')]/@href | tel:"(電話番号)で始まるリンクを抽出します。 |
//img/@src | すべての画像ソースURLを抽出する |
//img[contains(@class,'aligncenter')]/@src | クラス名 "aligncenter" を含む画像のソース URL をすべて抽出します。 |
//リンク[@rel='alternate']です。 | rel属性が "alternate "に設定されている要素を抽出する。 |
//hreflang | すべての hreflang 値を抽出する |
| |
| エックスパス | OUTPUT |
|---|
//meta[@property='article:published_time']/@content | 記事の公開日を抽出(WordPressのWebサイトでよく見られるmetaタグ) |
| |
| エックスパス | OUTPUT |
|---|
//meta[@property='og:type']/@content | Open Graph型オブジェクトを抽出する |
//meta[@property='og:image']/@content | Open Graphのフィーチャー画像のURLを抽出します。 |
//meta[@property='og:updated_time']/@content | オープングラフの更新時刻を抽出する |
| |
| エックスパス | OUTPUT |
|---|
//meta[@name='twitter:card']/@content | Twitterカードの種類を抽出する |
//meta[@name='twitter:title']/@content | Twitterカードのタイトルを抽出する |
//meta[@name='twitter:site']/@content | Twitterカードサイトオブジェクト(Twitterハンドル)を抽出します。 |
| |
| エックスパス | OUTPUT |
|---|
//*[@itemtype]/@itemtype | ページ上のすべてのタイプのスキーママークアップを抽出します。 |
| |
でパンくずをチェックするために使用するカスタム抽出は以下の通りです。 スクリーミングフロッグ.
| エックスパス | OUTPUT |
|---|
//*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop]/a/@href | すべてのパンくずリンクを抽出する |
//*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop][1]/a/@href | 最初のパンくずリンクを抽出する |
//*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop]. | パンくずの名前を抽出する(抽出フィルタを「テキストを抽出」に設定)。 |
count(//*[contains(@itemtype,'BreadcrumbList')]/*[@itemprop]) | パンくずリスト項目の数を数える(抽出フィルタを "関数値 "にする) |
| |
| エックスパス | OUTPUT |
|---|
//*[@itemprop='name']/@content | 製品名を抽出する |
//*[@itemprop='description']/@content | 商品説明文の抜粋 |
価格] //*[@itemprop='price']/@content | 製品価格を抽出する |
価格通貨] //*[@itemprop='priceCurrency']/@content | 製品通貨を抽出する |
//*利用可否について | 製品の在庫状況を抽出 |
//*[@itemprop='sku']/@content | 製品SKUを抽出する |
| |
| エックスパス | OUTPUT |
|---|
//*[@itemprop='reviewCount']を指定します。 | レビュー回数を抽出 |
//*[@itemprop='ratingValue']を指定します。 | レーティング値を抽出する |
//*[@itemprop='bestRating']です。 | 最適なレビュー評価を抽出 |
//*レビュー]/*[@itemprop='name']。 | レビュー名を抽出する |
//*レビュー]/*[@itemprop='author']。 | レビュー執筆者を抜粋 |
//*レビュー]/*[@itemprop='datePublished']/@content | レビューの公開日を抽出する |
//*[@itemprop='review']/*[@itemprop='reviewBody']. | レビューの本文を抜粋 |
| |
| エックスパス | OUTPUT |
|---|
//*[contains(@itemtype,'organization')]/*[@itemprop='name']. | 組織名を抽出する |
//*住所]/*[@itemprop='streetAddress']を指定します。 | ストリートアドレスを抽出する |
//*住所]/*[@itemprop='addressLocality']を指定します。 | アドレスの局所性を抽出する |
//*住所]/*[@itemprop='addressRegion']。 | アドレス領域を抽出する |
//*[@itemprop='telephone']. | 電話番号を抽出する |
//*[@itemprop='sameAs']/@href | sameAs "リンクを抽出します。 |
| |
記事スキーマを抽出する
| エックスパス | OUTPUT |
|---|
//*[contains(@itemtype,'Article')]/*[@itemprop='headline']. | 記事の見出しを抽出する |
//*[@itemprop='author']/*[@itemprop='name']/@content | 著者名を抽出する |
//*出版社]/*[@itemprop='name']/@content | 出版社名を抽出する |
//*内容物 | 発行日を抜粋 |
//*[@itemprop='dateModified']/@content | 更新日時を抽出する |
| |
ワイルドカード
| シンタックス | 機能 |
|---|
. | 任意の1文字にマッチする |
* | 直前の文字に0回以上マッチする |
? | 直前の文字に0回または1回マッチする |
+ | 直前の文字に1回以上マッチする |
| | オア |
| |
アンカー
| シンタックス | 機能 |
|---|
^ | 文字列は、後続の文字から始まります。 |
$ | 文字列は直前の文字で終了する。 |
| |
グループ
| シンタックス | 機能 |
|---|
( ) | 囲んだ文字を正確な順序で一致させる |
[ ] | 囲んだ文字を任意の順序でマッチング |
- | 指定された範囲内の任意の文字にマッチする |
| |
エスケープ
| シンタックス | 機能 |
|---|
\ | 文字を正規表現としてではなく、文字として扱う。 |
| |
| リジェックス | OUTPUT |
|---|
["'](ua-.*?)["']です。 | Google AnalyticsのトラッキングIDを抽出する |
["'](G-.*?)["'] | Google Analytics 4(GA4)のトラッキングIDを抽出します。 |
["'](aw-.*?)["']です。 | Google AdsのコンバージョンIDやリマーケティングタグを抽出します。 |
["'](gtm-.*?)["']. | Google タグマネージャおよび Google オプティマイズの ID を抽出します。 |
fbq\(["']init["'], ["'](.*?)["'] | Facebook Pixel IDを抽出する |
\♪♪♪♪~ | Bing Ads UETタグの抽出 |
adroll_adv_id = ["'](.*?)["']. | AdRollの広告主IDを抽出する |
adroll_pix_id = ["'](.*?)["']. | AdRollのPixel IDを抽出します。 |
| |
すべてのスキーママークアップとスキーマタイプを抽出する
| リジェックス | OUTPUT |
|---|
["']application/ld+json["']>(.*?). | JSON-LDスキーマのマークアップをすべて抽出します。 |
["']@type["']:*["'](.*?)["'] | ページ上のJSON-LDスキーママークアップの全種類を抽出します。 |
| |
| リジェックス | OUTPUT |
|---|
["']item["']:*["']@id["']:*["'](.*?)["'] | パンくずリンクの抽出 |
["']item["']:*{["']@id["']:*["'].*?["'], *["']name["']:*["'](.*?)["'] | パンくずの名前を抽出する |
| |
| リジェックス | OUTPUT |
|---|
["']@type["']:*["']Product["'].*?["']name["']:*["'](.*?)["'] | 製品名を抽出する |
["']@type["']:*["']Product["'].*?["']description["']:*["'](.*?)["'] | 商品説明文の抜粋 |
["']@type["']:*["']Product["'].*?["']price["']:*["'](.*?)["'] | 製品価格を抽出する |
["']@type["']:*["']Product["'].*?["']priceCurrency["']:*["'](.*?)["'] | 製品通貨を抽出する |
["']@type["']:*["']Product["'].*?["']availability["']:*["'](.*?)["'] | 製品の在庫状況を抽出 |
["']@type["']:*["']Product["'].*?["']sku["']:*["'](.*?)["'] | 製品SKUを抽出する |
| |
| リジェックス | OUTPUT |
|---|
["']reviewCount["']:*["'](.*?)["'] | レビュー回数を抽出 |
["']ratingValue["']:*["'](.*?)["'] | レーティング値を抽出する |
["']bestRating["']です。*["'](.*?)["'] | 最適な評価を抽出する |
| |
| リジェックス | OUTPUT |
|---|
["']@type["']:*["']Organization["'].*?["']name["']:*["'](.*?)["'] | 組織名を抽出する |
["']streetAddress["']です。*["'](.*?)["'] | ストリートアドレスを抽出する |
["']addressLocality["']です。*["'](.*?)["'] | アドレスの局所性を抽出する |
["']addressRegion["']です。*["'](.*?)["'] | アドレス領域を抽出する |
["']電話["']:*["'](.*?)["'] | 電話番号を抽出する |
["']sameAs["']:*\[(.*?)\] | sameAs "リンクを抽出します。 |
| |
ArticleまたはBlogPosting Schemaを抽出する。
| リジェックス | OUTPUT |
|---|
["']ヘッドライン["']:*["'](.*?)["'] | 記事の見出しを抜粋 |
["']author["'].*?["']name["']:*["'](.*?)["'] | 著者名を抽出する |
["']publisher["'].*?["']name["']:*["'](.*?)["'] | 出版社名を抽出する |
["']datePublished["']:*["'](.*?)["'] | 発行日を抜粋 |
["']dateModified["']:*["'](.*?)["'] | 更新日時を抽出する |
| |
このリストに追加してほしい抽出物があれば教えてください。
発行日:2021-03-10
更新日: 2024-07-18
アイザック・アダムス・ハンズは、検索エンジン最適化サービスを提供するSEO North社でSEOディレクターを務めています。SEOのプロフェッショナルとして、アイザックはオンページSEO、オフページSEO、テクニカルSEOの分野で豊富な専門知識を持ち、競合他社を圧倒している。