Home > Screaming Frog > Screaming Frog Custom Extractions: A Guide to Extracting Crawl Data
Screaming Frog Custom Extractions: A Guide to Extracting Crawl Data
Screaming Frog (screamingfrog.co.uk) is a powerful SEO tool with many search engine optimization features, including custom extractions, which allow you to extract data from your crawls easily. This blog post will discuss how Screaming Frog Custom Extraction works and why it can help improve your SEO efforts, e-commerce digital marketing, and indexing strategies.
Websites have a ton of helpful information—most times, it’s too laborious or complicated to visit every page on a website to copy product data, metadata, title tags, and anchor text into a spreadsheet. Here is where Screaming Frog comes to the rescue with custom search data extractions, using APIs and regular expressions to automate the process. Custom extractions are a form of web scraping, web harvesting, or web data extraction used to scrape and extract data from websites, allowing you to store it locally on your computer.
The Screaming Frog SEO Spider software is a website crawler that improves onsite SEO by extracting and analyzing your website’s structured data using a graphical user interface (GUI), effectively handling XML and JavaScript-rendered content.
What are custom extractions?
Custom extractions are Screaming Frog’s SEO spider functions to extract explicit information from web pages. These extractions help optimize your site for a Technical SEO audit, including search results, gathering essential data on your copy, and helping locate and fix errors in headers and other elements.
How is Data Extraction done?
Use Screaming Frog if you want to process data extraction, which involves pulling the required data from your website. The information is saved within Screaming Frog’s memory, giving you the option to export your scanned results to Excel or Google Sheets for further review. This can include data from dropdown menus and internal linking structures.
Why is Data Extraction critical?
Data extraction allows you to harvest large amounts of data quickly and efficiently. This automation gives you immediate results of web architecture. This process saves you time and resources while giving you the valuable data you’ll need to plan and strategize search engine optimization strategies. Screaming Frog is the go-to Web Scraper Tool for SEOs and a data extractor. The options are endless; here are a ton of custom web-scraping syntaxes. Check the tutorial below.
How to Extract Custom Data using Screaming Frog
Use Screaming Frog if you want to process data extraction, which involves pulling the required data from your website. The information is saved within Screaming Frog’s memory, giving you the option to export your scanned results to Excel or Google Sheets for further review. For more advanced needs, you can incorporate regular expressions to precisely target and extract specific patterns from your HTML or JavaScript-rendered content, including nodes and snippets.
By integrating these techniques, you can optimize your SEO strategy effectively, leveraging the power of tools like Screaming Frog and even utilizing AI technologies like ChatGPT for deeper insights.
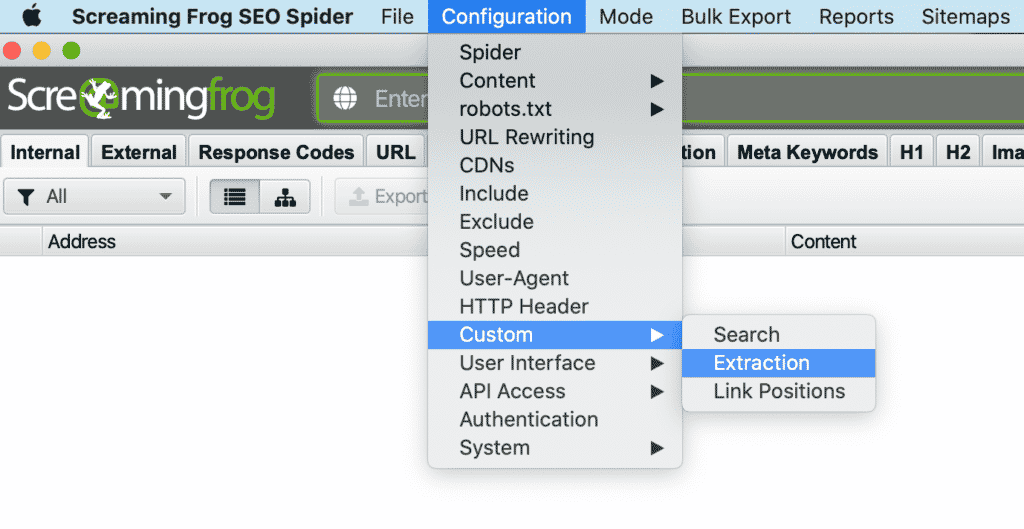
1. In ScreamingFrog, go to Configuration > Custom > Extraction.
Screaming Frog Custom Extraction
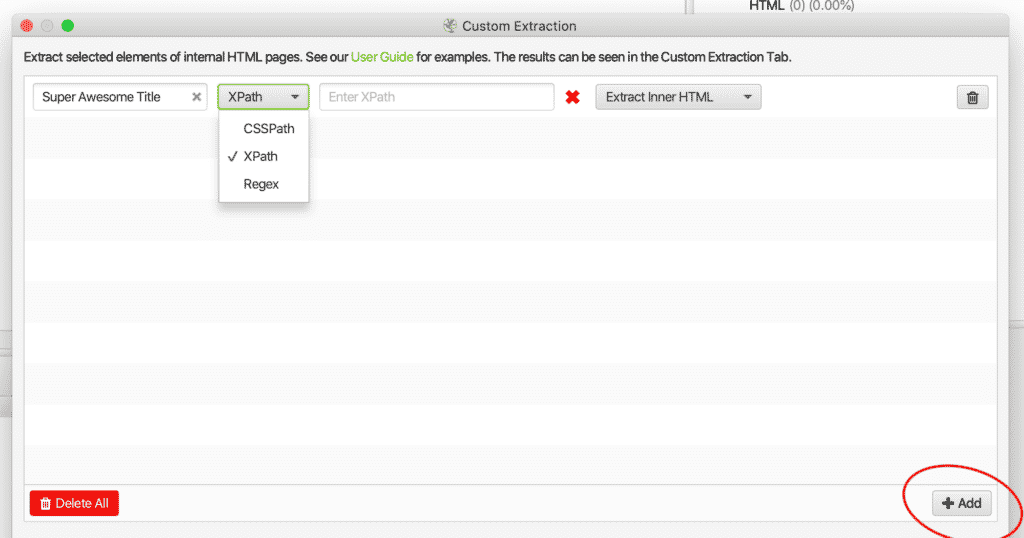
2. Next, you will need to +Add and set up your extraction rules.
Select elements of internal HTML using the Custom Extraction tab
3. Add a Title, 4. Select if you need CSSPath, XPath, or Regex, 5. Add your search function.
If you aren’t sure which selector or function you need, look at the examples below or use the inspect element function in Google Chrome Dev Tools. You can open Dev Tools by using “right-click” in the Google Chrome browser.
Example:
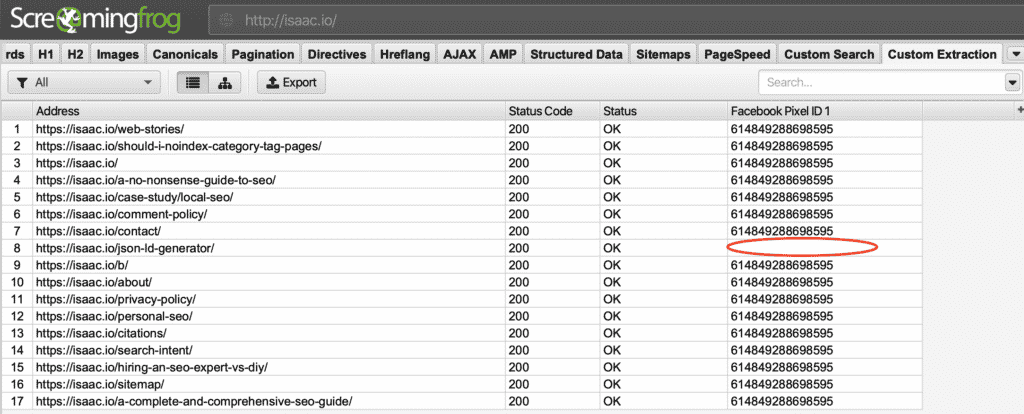
Here is an example of how you would scrape for a Facebook Pixel ID
Facebook Pixel ID Extraction
In the Results, you can see, one of my pages is missing a Facebook Pixel:
Missing Facebook ID
Below are predefined custom extraction datasets to get you started.
Isaac Adams-Hands is the SEO Director at SEO North, a company that provides Search Engine Optimization services. As an SEO Professional, Isaac has considerable expertise in On-page SEO, Off-page SEO, and Technical SEO, which gives him a leg up against the competition.