Screaming Frog (screamingfrog.co.uk) is a powerful SEO tool with many search engine optimization features. One of the lesser-known features, Screaming Frog Custom Extractions, allows you to easily extract data from your crawls. This blog post will discuss how Screaming Frog Custom Extraction works and why it can help improve your SEO efforts and e-commerce digital marketing SEO strategies!
Websites have a ton of helpful information—most times, it’s too laborious or complicated to visit every page on a website to copy product data, メタデータ, タイトルタグそして アンカーテキスト into a spreadsheet. Here is where Screaming Frog comes to the rescue with custom search data extractions to automate the process. Custom extractions are a form of ウェブスクレイピングウェブハーベスティング、またはウェブ データ抽出 は、ウェブサイトからデータをスクレイピングして抽出し、自分のコンピュータにローカルに保存できるようにするために使用されます。
があります。 Screaming Frog SEO Spider software is a website crawler that improves onsite SEO by extracting and analyzing your website’s structured data using a graphical user interface (GUI).
What are custom extractions?
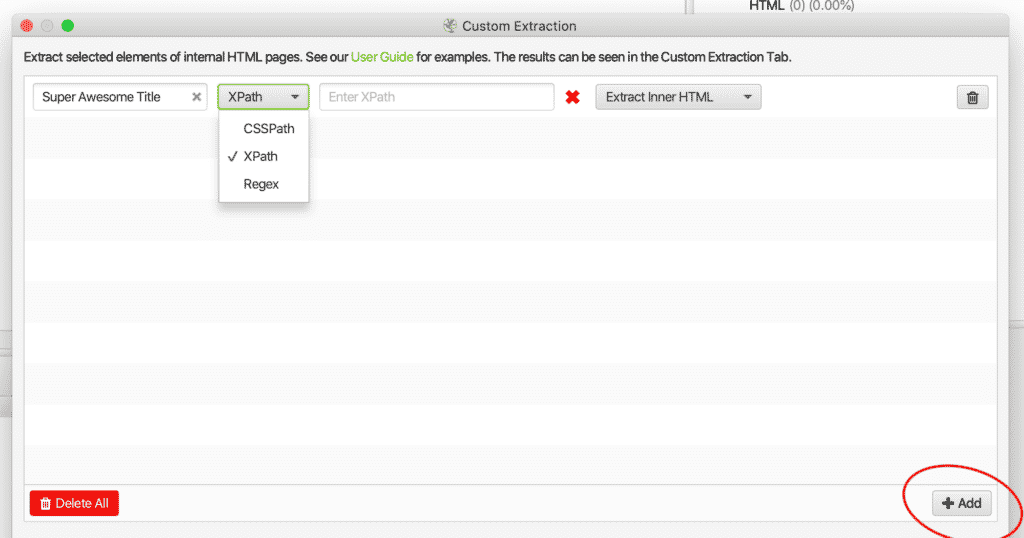
カスタムエクストラクションはScreaming Frogs SEO スパイダーは、ウェブページから明示的な情報を抽出する機能を備えています。これらの抽出は、あなたのサイトを以下のように最適化するのに役立ちます。 テクニカルSEO audit, including search results, gather essential data on your copy, and help locate and fix errors.
データ抽出はどのように行われるのですか?
Use Screaming Frog if you want to process data extraction, which involves pulling the required data from your website. The information is saved within Screaming Frog’s memoryにエクスポートすることができます。 エクセル または グーグルシート をご覧ください。
なぜデータ抽出が重要なのか?
データ抽出により、大量のデータを迅速かつ効率的に採取することができます。この自動化により、以下のような結果をすぐに得ることができます。 ウェブアーキテクチャ. This process saves you time and resources while giving you the valuable data you’ll need to plan and strategize search engine optimization strategies. Screaming Frog is the go-to Web Scraper Tool for SEOs and a data extractor. The options are endless; here are a ton of custom web-scraping syntaxes. Check the tutorial below.
If you aren’t sure which selector or function you need, look at the examples below or use the inspect element function in グーグルクロームデバイスツール. You can open Dev Tools by using “right-click” in the Google Chrome browser.
例
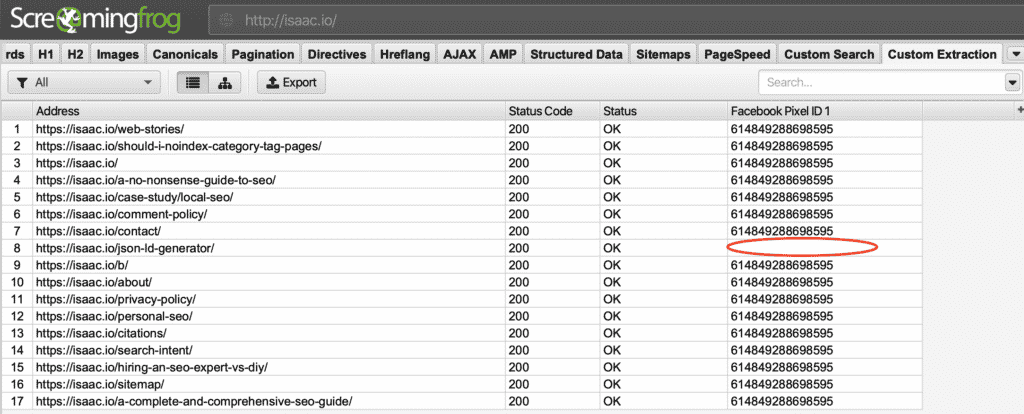
Here is an example of how you would scrape for a Facebook Pixel ID