Rana gritona (https://www.screamingfrog.co.uk) es una herramienta excelente para rastrear sitios web y extraer datos, pero si no está rastreando todo URLSi Screaming Frog no está rastreando todas las URL, no estará realizando una auditoría SEO técnica de calidad (auditoría de meta descripciones en la página, códigos de respuesta, enlaces internos, comprobación de contenidos duplicados, títulos de páginas, backlinks, textos alternativos, etc.) en sus sitios de comercio electrónico. En esta entrada de blog, examinaremos por qué Screaming Frog no está rastreando todas las URL y cómo puede solucionar el problema. Por lo tanto, si tiene problemas para que Screaming Frog rastree todas sus URL, permanezca atento. Usted está en un convite.

Índice de contenidos
- Cómo solucionar que Screaming Frog no rastree todas las URLs
- El sitio está bloqueado por robots.txt.
- El atributo "nofollow" está presente en los enlaces que no se rastrean.
- La página tiene un atributo 'nofollow' a nivel de página.
- El User-Agent está siendo bloqueado.
- El sitio requiere JavaScript.
- El sitio web requiere cookies.
- El sitio web utiliza conjuntos de marcos.
- La cabecera Content-Type no indica que la página sea HTML.
- Conclusión
- PREGUNTAS FRECUENTES
Cómo solucionar que Screaming Frog no rastree todas las URLs
Hay varias razones Screaming Frog puede no rastrear todos los subdominios en un sitio webEl más común es que el sitio web haya sido configurado para bloquear rastreadores como Screaming Frog.
El sitio está bloqueado por robots.txt.

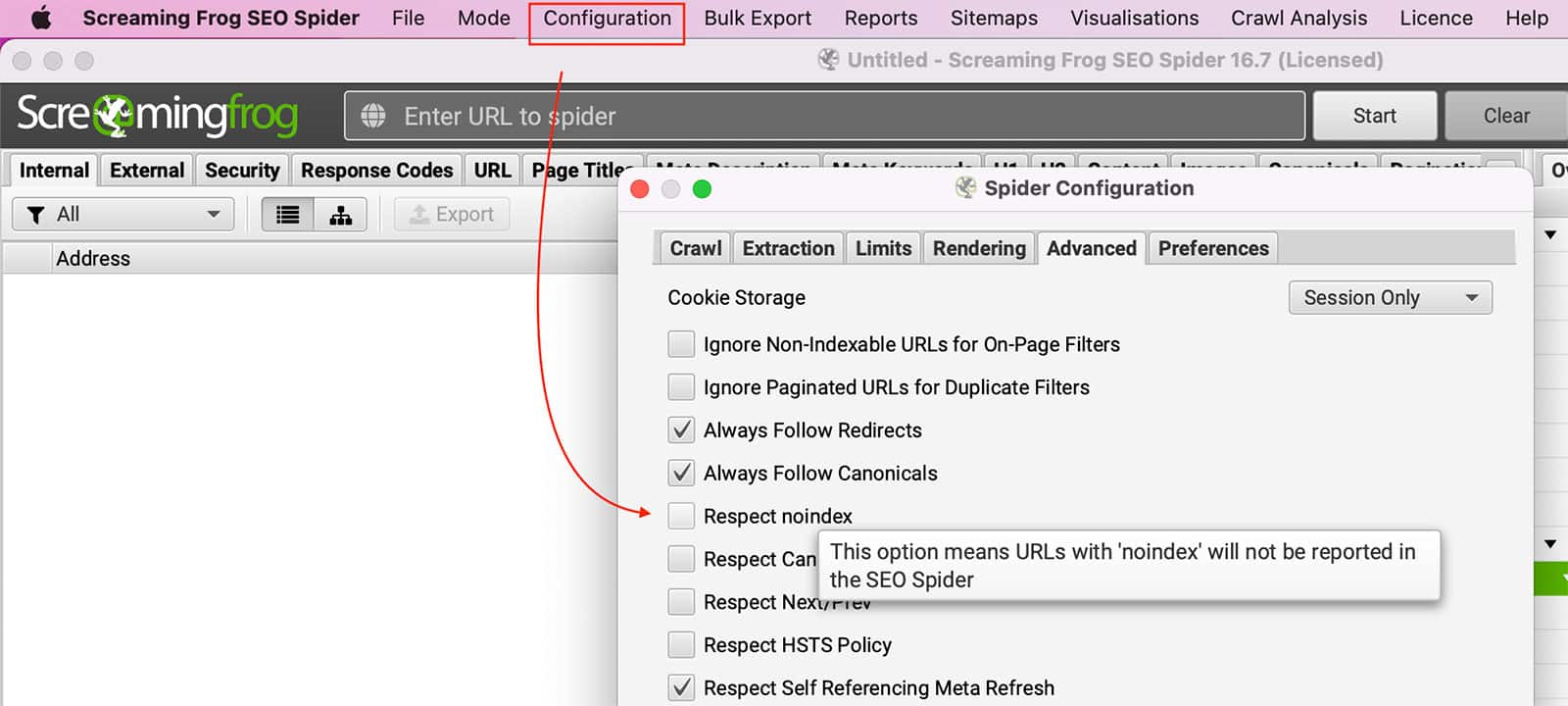
Robots.txt puede bloquear La Rana Gritona rastrear páginas. Puede configurar el SEO Spider para ignorar robots.txt yendo a Configuración >> Araña >> Avanzado >> Desmarque Respetar Noindex el escenario.
También puede cambiar su Agente del usuario a GoogleBot para ver si el sitio web permite ese rastreo.
Robots.txt se utiliza para indicar a los rastreadores web, o "bots", a qué pueden acceder en un sitio web determinado. Cuando un bot intenta acceder a una página que está específicamente prohibida en el archivo robots.txt, recibirá un mensaje de que el webmaster no quiere que se rastree esa página. En algunos casos, esto puede ser intencionado. Por ejemplo, el propietario de un sitio puede querer evitar que los robots indexen información sensible. En otros casos, puede deberse simplemente a un descuido. Sea cual sea el motivo, un sitio bloqueado por robots.txt será inaccesible para cualquiera que intente rastrearlo.
El atributo "nofollow" está presente en los enlaces que no se rastrean.

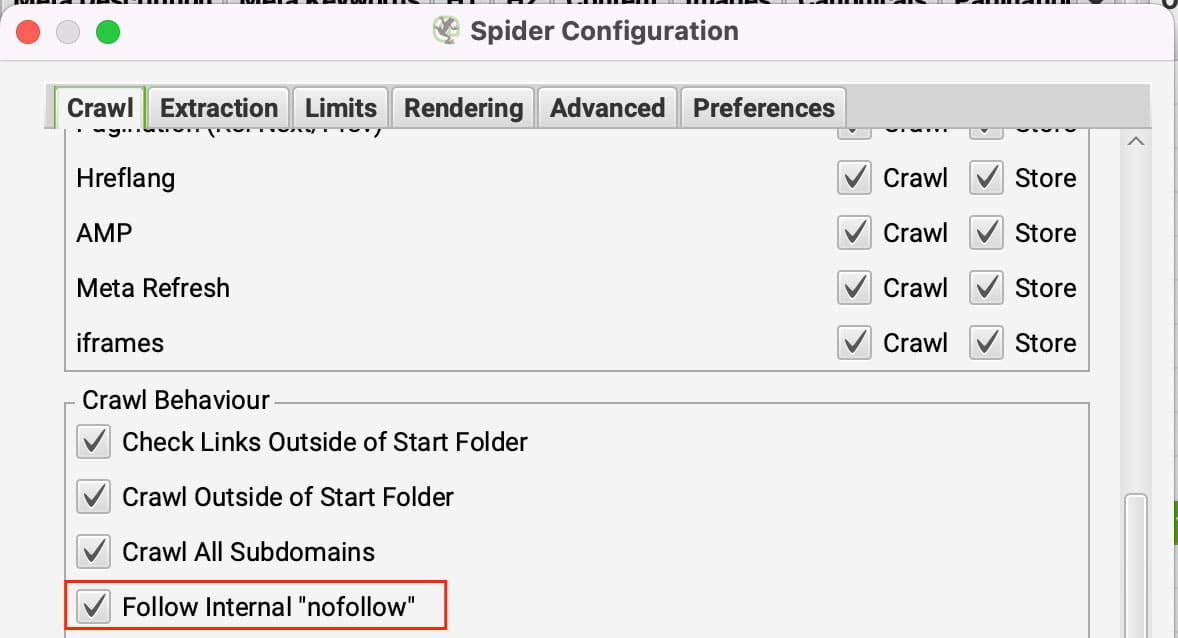
Los enlaces nofollow hacen lo que se pretende, dicen orugas no seguir los enlaces. Si todos los enlaces se establecen en nofollow en una página, a continuación, Screaming Frog no tiene a dónde ir. Para evitar esto, puede configurar Screaming Frog para seguir enlaces internos nofollow.
Puede actualizar esta opción en Configuración >> Araña bajo el Pestaña "Crawl" (arrastrarse) haciendo clic en Seguimiento interno 'nofollow' enlaces.
La página tiene un atributo 'nofollow' a nivel de página.
El atributo nofollow a nivel de página se establece mediante una etiqueta meta robots o una etiqueta X-Robots en la cabecera HTTP. Estos se pueden ver en la pestaña "Directivas" en el filtro "Nofollow". El atributo nofollow a nivel de página se utiliza para evitar que los motores de búsqueda sigan los enlaces de una página.
Esto es útil para páginas que contienen enlaces a fuentes poco fiables o sin importancia. Al establecer el atributo nofollow, está indicando a los motores de búsqueda que no deben seguir los enlaces de la página. Esto ayudará a mejorar la clasificación de su sitio en los motores de búsqueda, pero impedirá que rastreen el sitio web.
Para ignorar las etiquetas Noindex, debe ir a Configuración >> Araña >> Avanzado >> Desmarque el Respetar noindex el escenario.
El User-Agent está siendo bloqueado.

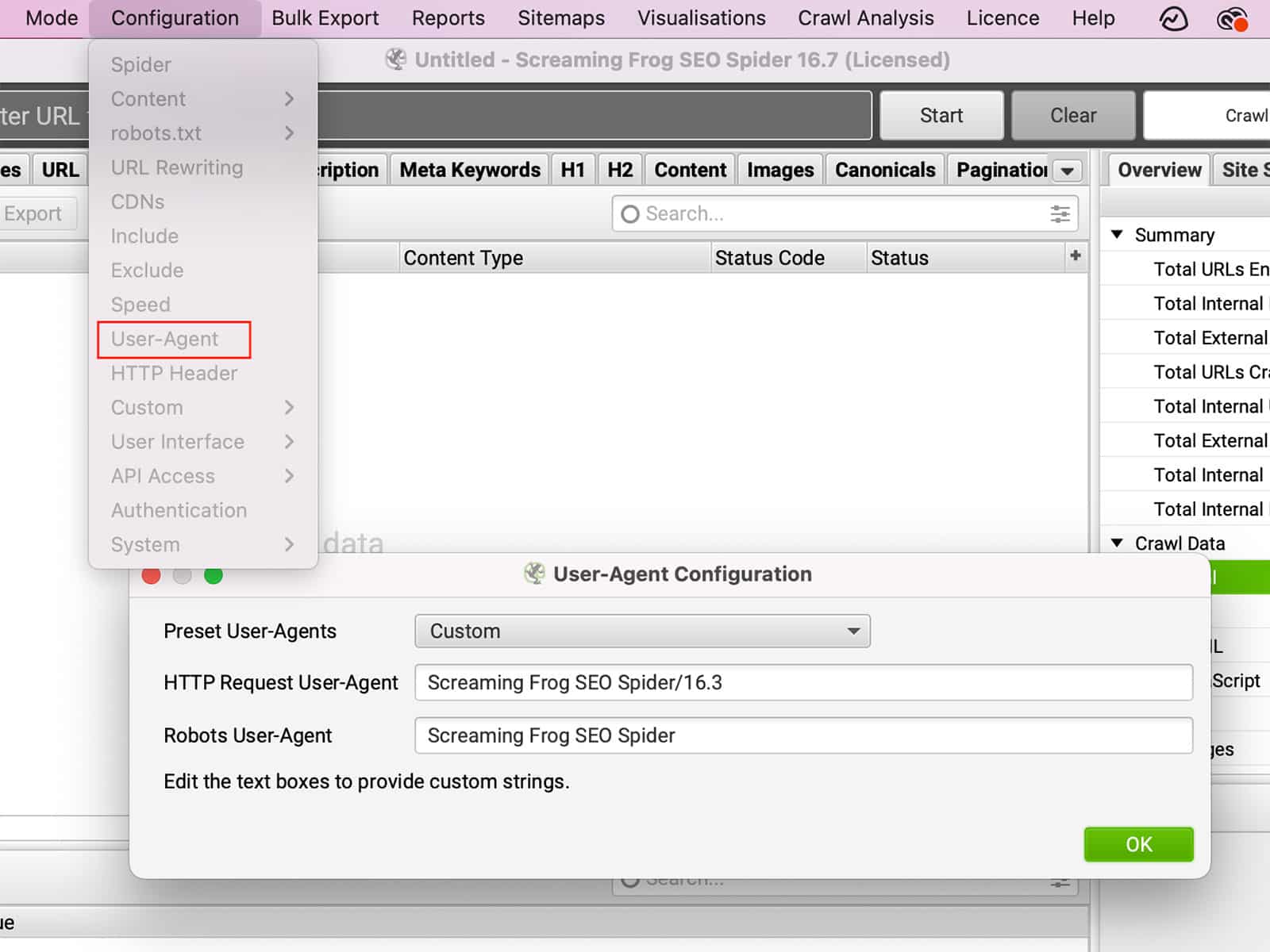
El Usuario-Agente es una cadena de texto que su navegador envía al sitio web que está visitando. El User-Agent puede proporcionar información sobre su navegador, sistema operativo e incluso su dispositivo. En función de esta información, el sitio web puede cambiar su comportamiento. Por ejemplo, si visita un sitio web utilizando un dispositivo móvil, el sitio web puede redirigirle a una versión del sitio adaptada a dispositivos móviles. Por otra parte, si cambia el User-Agent para simular ser un navegador diferente, es posible que pueda acceder a funciones que no están disponibles en su navegador real. Igualmente, algunos sitios pueden bloquear totalmente ciertos navegadores. Al cambiar el User-Agent, puede cambiar la forma en que un sitio se comporta, dándole más control sobre su experiencia de navegación.
Puede cambiar el User-Agent en Configuración >> Usuario-Agente.
El sitio requiere JavaScript.

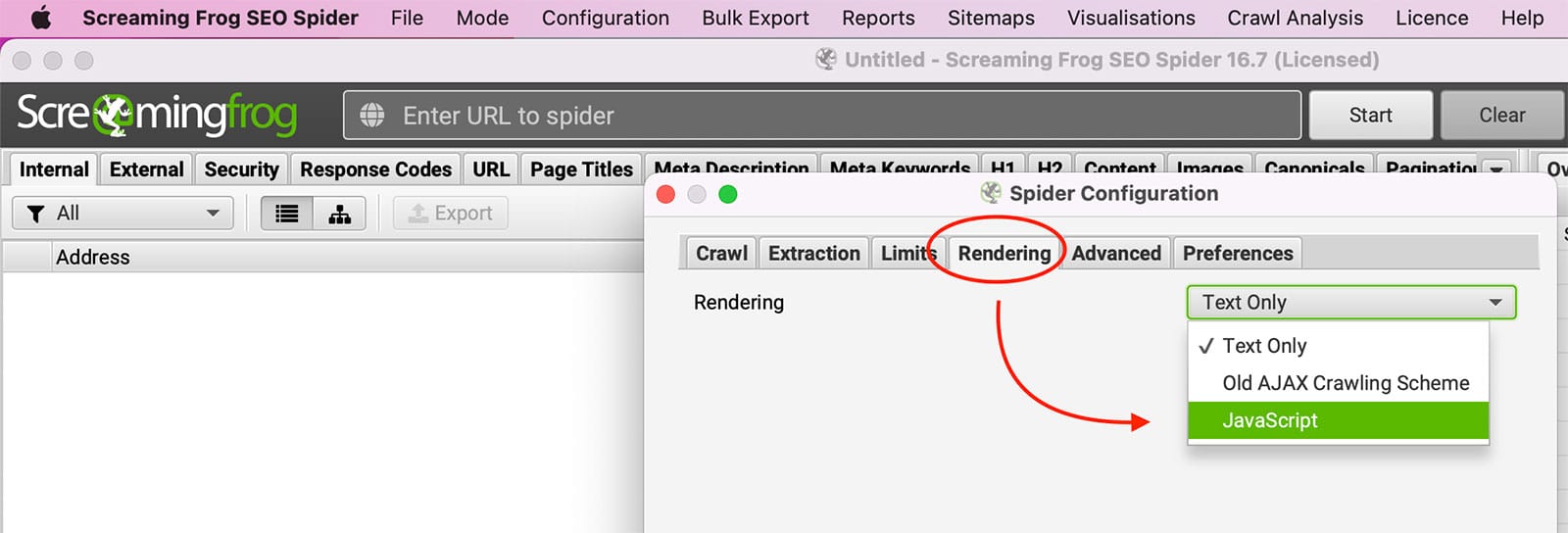
JavaScript es un lenguaje de programación que se utiliza habitualmente para crear páginas web interactivas. Cuando JavaScript está activado, puede ejecutarse automáticamente al cargar una página, lo que permite cambiar los elementos de la página sin necesidad de actualizarla por completo. Por ejemplo, JavaScript puede utilizarse para crear menús desplegables, mostrar imágenes en función de las entradas del usuario y mucho más. Aunque JavaScript puede ser beneficioso, algunos usuarios prefieren desactivarlo en su navegador por varias razones. Una de ellas es que JavaScript puede utilizarse para rastrear la actividad de navegación del usuario. Sin embargo, desactivar JavaScript también puede provocar problemas en la visualización de un sitio web o en el funcionamiento de determinadas funciones.
Prueba con habilitar la representación de javascript dentro de Screaming Frog bajo Configuración >> Araña >> Renderizado.
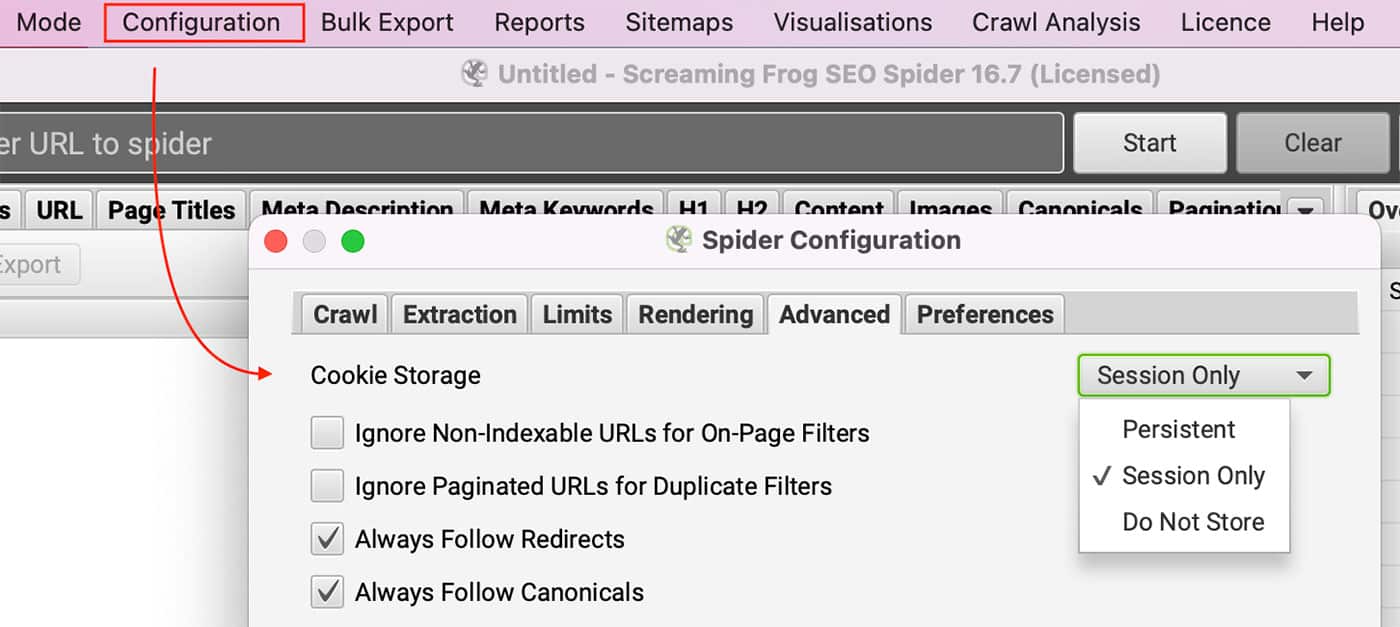
El sitio web requiere cookies.

¿Puede ver el sitio con las cookies desactivadas en su navegador? Los usuarios con licencia pueden habilitar las cookies accediendo a Configuración >> Araña y seleccionando Sólo sesión en Almacenamiento de galletas en el Pestaña avanzada.
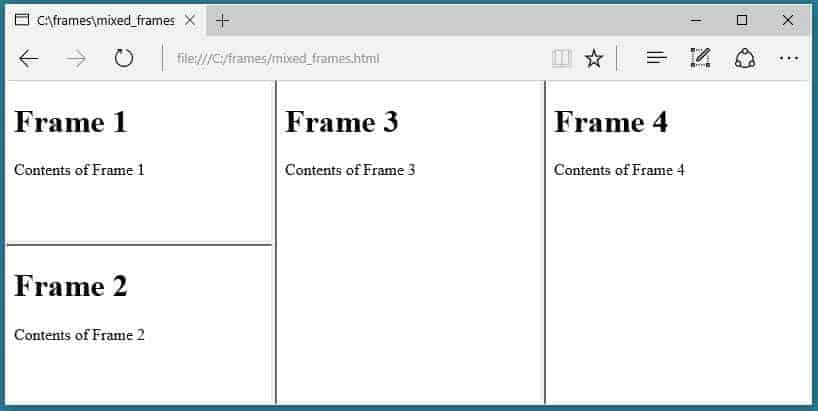
El sitio web utiliza conjuntos de marcos.

El SEO Spider no rastrea el atributo frame-src.
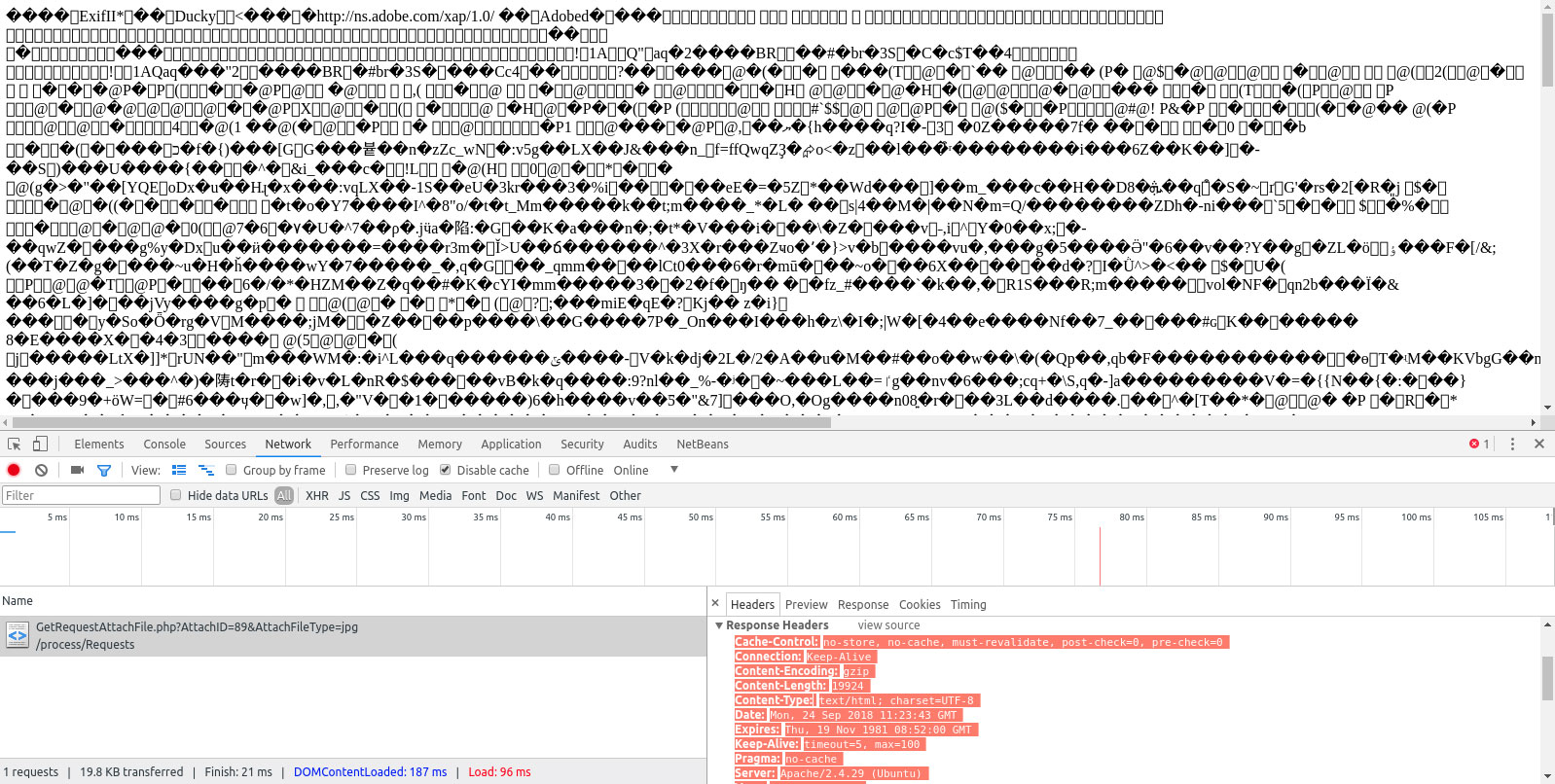
La cabecera Content-Type no indica que la página sea HTML.

Se muestra en la columna Contenido y debe ser texto/HTML o application/xhtml+xml.
Conclusión
La araña SEO de Screaming Frog puede ser una herramienta excelente para auditar su sitio web, pero es vital asegurarse de que se rastrean todas las URL. Si usted no está recibiendo la datos completos que necesita de sus auditoríaspuede haber un problema con la configuración de Screaming Frog. Esta entrada de blog examina por qué La Rana Gritona podría no estar rastreando todas sus URLs y cómo solucionar el problema. Al solucionar estos problemas, podrá obtener datos más completos de sus auditorías de Screaming Frog y mejorar su estrategia de SEO. ¿Ha intentado utilizar Screaming Frog para sus auditorías de sitios web? ¿Qué consejos tiene para mejorar su funcionalidad?
PREGUNTAS FRECUENTES
¿Por qué Screaming Frog no rastrea todas las URLs?
Publicado en: 2022-06-07
Actualizado el: 2024-09-16