Grenouille hurlante (https://www.screamingfrog.co.uk) est un excellent outil pour explorer les sites web et extraire des données, mais s'il n'explore pas tous les sites web de l URLsSi Screaming Frog n'explore pas toutes les URL, vous n'effectuerez pas un audit SEO technique de qualité (audit des méta-descriptions de page, des codes de réponse, des liens internes, vérification des contenus dupliqués, des titres de page, des backlinks, des textes alt, etc) sur vos sites de commerce électronique. Dans cet article de blog, nous allons examiner pourquoi Screaming Frog n'explore pas toutes les URL et comment vous pouvez résoudre ce problème. Si vous avez du mal à faire en sorte que Screaming Frog explore toutes vos URL, restez à l'écoute ! Vous allez en prendre plein les yeux.

Table des matières
- Comment réparer le fait que Screaming Frog n'explore pas toutes les URLs ?
- Le site est bloqué par robots.txt.
- L'attribut "nofollow" est présent sur les liens qui ne sont pas explorés.
- La page possède un attribut "nofollow" au niveau de la page.
- L'agent utilisateur est bloqué.
- Le site nécessite JavaScript.
- Le site nécessite des cookies.
- Le site web utilise des framesets.
- L'en-tête Content-Type n'indiquait pas que la page était en HTML.
- Conclusion
- FAQ
Comment réparer le fait que Screaming Frog n'explore pas toutes les URLs ?
Il y a plusieurs raisons pour lesquelles Screaming Frog n'explore pas tous les sous-domaines d'un site Web. site webLe plus courant est que le site Web a été configuré pour bloquer les robots d'exploration comme Screaming Frog.
Le site est bloqué par robots.txt.

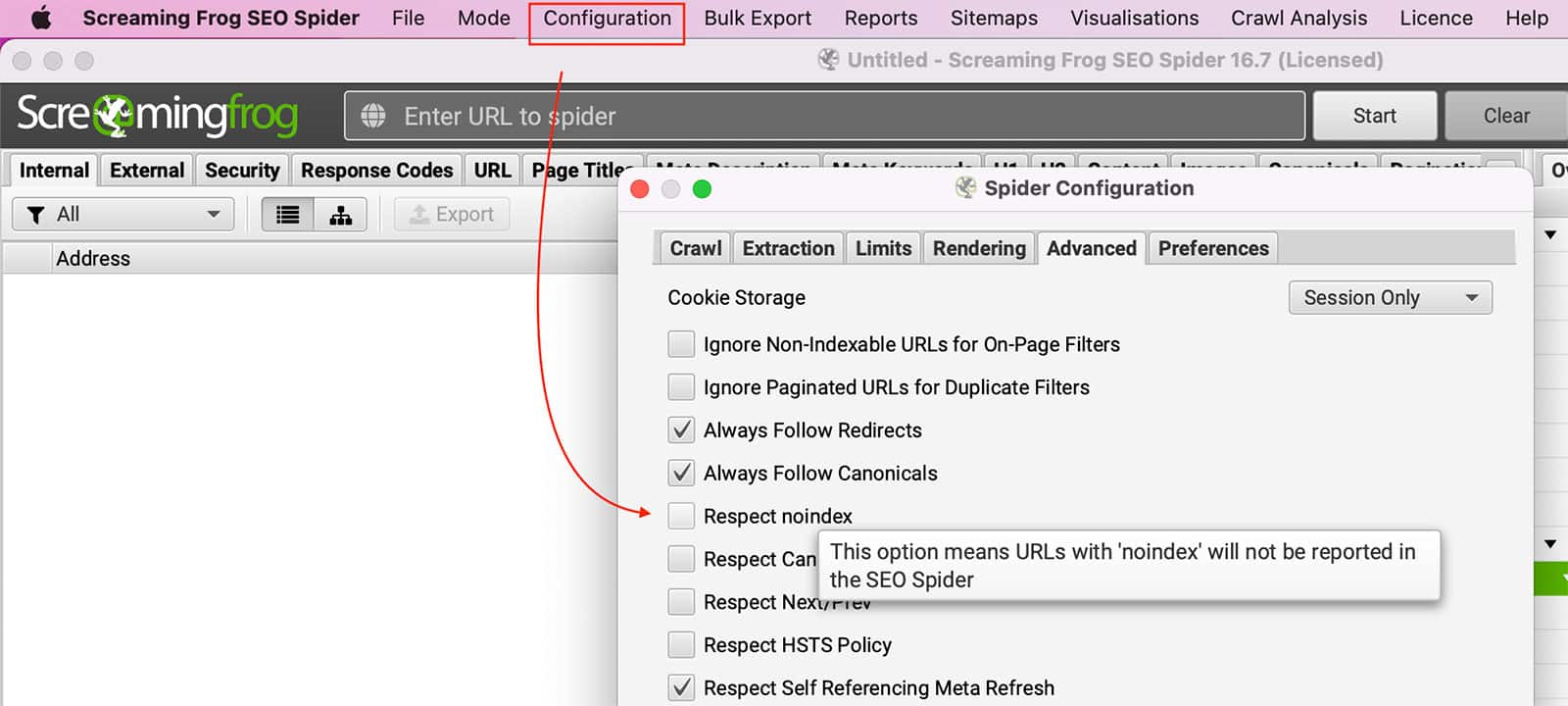
Robots.txt peut bloquer Grenouille hurlante crawl des pages. Vous pouvez configurer le SEO Spider pour qu'il ignore robots.txt en allant sur Configuration >> Araignée >> Avancé >> Décochez Respect Noindex réglage.
Vous pouvez également changer votre Agent de l'utilisateur à GoogleBot pour voir si le site web autorise ce crawl.
Robots.txt Le fichier robots.txt est utilisé pour indiquer aux robots d'indexation, ou "bots", ce à quoi ils sont autorisés à accéder sur un site web donné. Lorsqu'un robot tente d'accéder à une page qui est spécifiquement interdite dans le fichier robots.txt, il reçoit un message indiquant que le webmestre ne souhaite pas que cette page soit explorée. Dans certains cas, cela peut être intentionnel. Par exemple, le propriétaire d'un site peut vouloir empêcher les robots d'indexer des informations sensibles. Dans d'autres cas, il s'agit simplement d'un oubli. Quelle qu'en soit la raison, un site bloqué par le fichier robots.txt sera inaccessible à toute personne tentant de l'explorer.
L'attribut "nofollow" est présent sur les liens qui ne sont pas explorés.

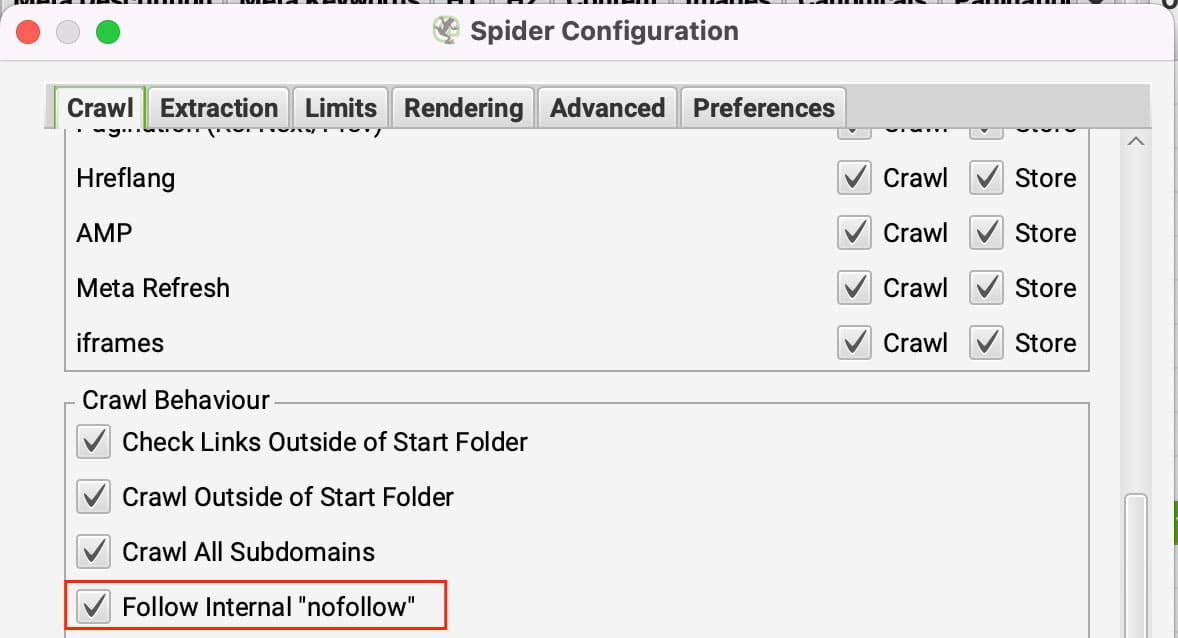
Les liens Nofollow font ce qu'ils sont censés faire, ils disent chenilles de ne pas suivre les liens. Si tous les liens d'une page sont réglés sur nofollow, Screaming Frog n'a nulle part où aller. Pour contourner ce problème, vous pouvez configurer Screaming Frog pour qu'il suive les liens internes en nofollow.
Vous pouvez mettre à jour cette option dans Configuration >> Araignée en vertu de la Onglet "Crawl en cliquant sur Suivi interne "nofollow". liens.
La page possède un attribut "nofollow" au niveau de la page.
Le site attribut nofollow au niveau de la page est défini par une balise méta robots ou une balise X-Robots dans l'en-tête HTTP. Ces éléments sont visibles dans l'onglet "Directives", dans le filtre "Nofollow". L'attribut nofollow au niveau de la page est utilisé pour empêcher les moteurs de recherche de suivre les liens d'une page.
Cet attribut est utile pour les pages qui contiennent des liens vers des sources peu fiables ou peu importantes. En définissant l'attribut nofollow, vous indiquez aux moteurs de recherche qu'ils ne doivent pas suivre les liens de la page. Cela contribuera à améliorer le classement de votre site dans les moteurs de recherche, mais vous empêchera d'explorer le site web.
Pour ignorer les balises Noindex, vous devez vous rendre à l'adresse suivante Configuration >> Araignée >> Avancé >> Décochez le site Respecter noindex réglage.
L'agent utilisateur est bloqué.

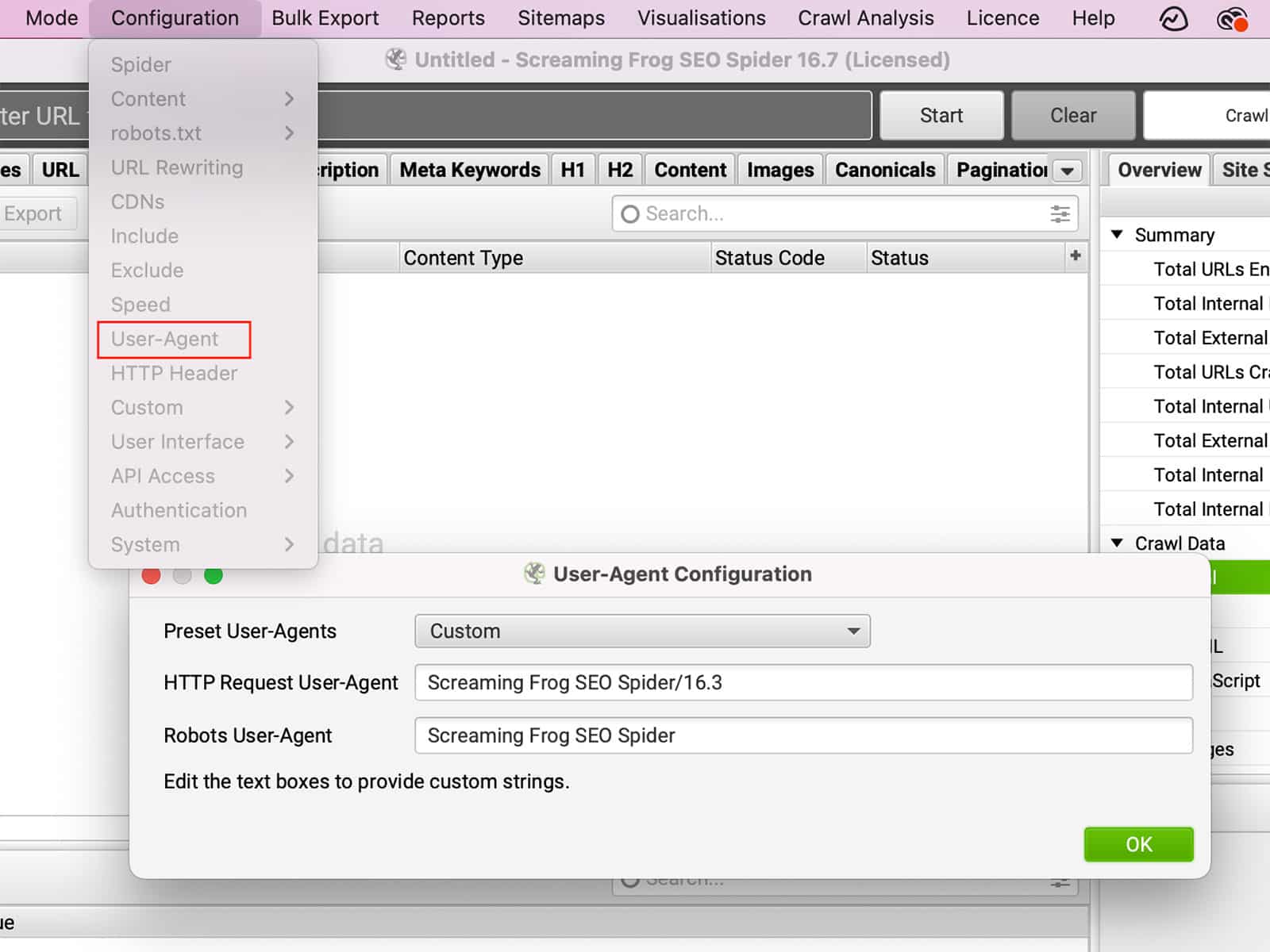
Le site User-Agent est une chaîne de texte qui est envoyée par votre navigateur au site Web que vous visitez. L'agent utilisateur peut fournir des informations sur votre navigateur, votre système d'exploitation et même votre appareil. Sur la base de ces informations, le site web peut modifier la façon dont il se comporte. Par exemple, si vous visitez un site web en utilisant un appareil mobile, le site web peut vous rediriger vers une version du site adaptée aux mobiles. Par ailleurs, si vous modifiez l'User-Agent pour vous faire passer pour un autre navigateur, vous pourrez accéder à des fonctionnalités qui ne sont pas disponibles dans votre navigateur réel. De même, Certains sites peuvent bloquer complètement certains navigateurs.. En modifiant l'agent utilisateur, vous pouvez changer la façon dont un site se comporte, ce qui vous donne un plus grand contrôle sur votre expérience de navigation.
Vous pouvez modifier l'agent utilisateur sous Configuration >> User-Agent.
Le site nécessite JavaScript.

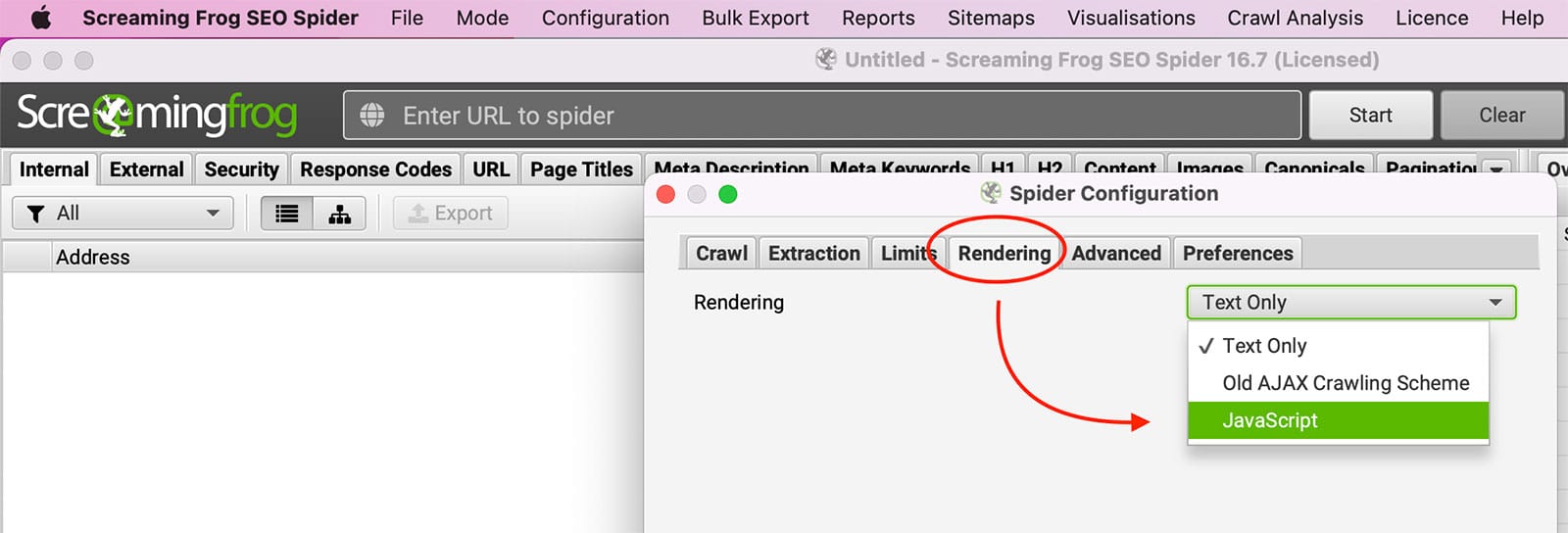
JavaScript est un langage de programmation couramment utilisé pour créer des pages web interactives. Lorsque JavaScript est activé, il peut s'exécuter automatiquement lorsqu'une page est chargée, ce qui permet de modifier les éléments de la page sans avoir à la rafraîchir entièrement. Par exemple, JavaScript peut être utilisé pour créer des menus déroulants, afficher des images en fonction des entrées de l'utilisateur, et bien d'autres choses encore. Bien que JavaScript puisse être bénéfique, certains utilisateurs préfèrent le désactiver dans leur navigateur pour diverses raisons. L'une d'entre elles est que JavaScript peut être utilisé pour suivre l'activité de navigation d'un utilisateur. Cependant, le JavaScript peut être utilisé pour suivre l'activité de navigation d'un utilisateur, La désactivation de JavaScript peut également entraîner des problèmes au niveau de l'affichage d'un site web ou du fonctionnement de certaines fonctionnalités.
Essayez activer le rendu javascript au sein de Screaming Frog sous Configuration >> Araignée >> Rendu.
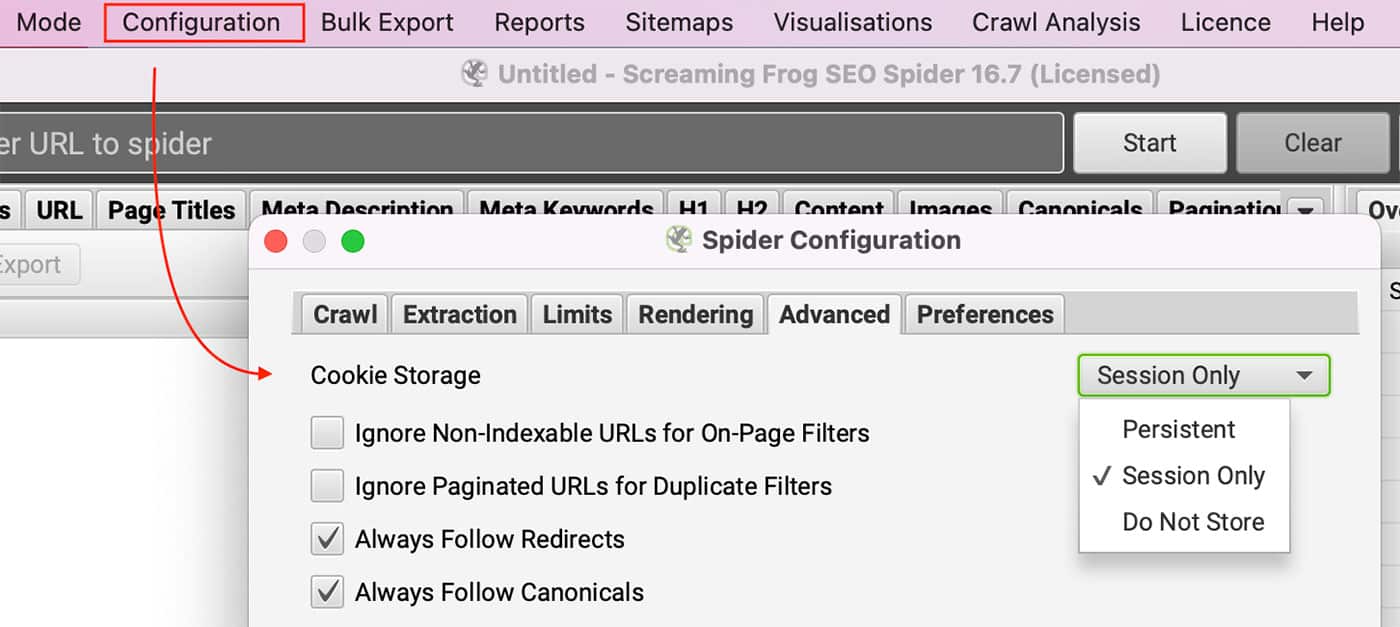
Le site nécessite des cookies.

Pouvez-vous consulter le site avec des cookies désactivés dans votre navigateur ? Les utilisateurs autorisés peuvent activer les cookies en allant sur Configuration >> Sp Sp Sp Sp Sp pour la configuration de l'espace de configuration et en sélectionnant Session uniquement sous Stockage des cookies dans le Onglet Avancé.
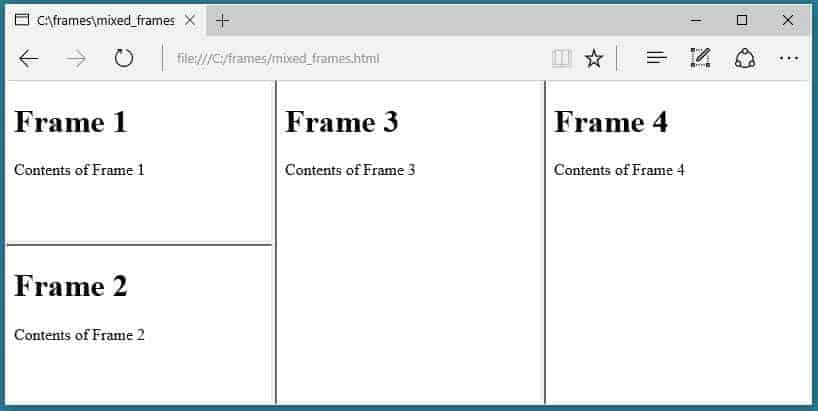
Le site web utilise des framesets.

Le SEO Spider n'explore pas l'attribut frame-src.
L'en-tête Content-Type n'indiquait pas que la page était en HTML.

Il est indiqué dans la colonne Contenu et doit être soit text/HTML soit application/xhtml+xml.
Conclusion
Le Screaming Frog SEO Spider peut être un excellent outil pour auditer votre site web, mais il est essentiel de s'assurer que toutes les URL sont explorées. Si vous n'obtenez pas les les données complètes dont vous avez besoin pour vos auditsIl se peut qu'il y ait un problème avec la configuration de Screaming Frog. Cet article de blog a examiné les raisons pour lesquelles Grenouille hurlante ne crawle peut-être pas toutes vos URL et comment résoudre le problème. En résolvant ces problèmes, vous pourrez obtenir des données plus complètes à partir de vos audits Screaming Frog et améliorer votre stratégie de référencement. Avez-vous essayé d'utiliser Screaming Frog pour vos audits de sites web ? Quels sont vos conseils pour améliorer ses fonctionnalités ?
FAQ
Pourquoi Screaming Frog n'explore-t-il pas toutes les URL ?
Publié le : 2022-06-07
Mise à jour le : 2024-09-16