スクリーミング・フロッグhttps://www.screamingfrog.co.uk)はウェブサイトをクロールしてデータを抽出するための優れたツールだが、もしすべての URLもしScreaming FrogがすべてのURLをクロールしていないのであれば、あなたのEコマースサイトで質の高いテクニカルSEO監査(ページ上のメタディスクリプション、レスポンスコード、内部リンクの監査、重複コンテンツのチェック、ページタイトル、バックリンク、altテキストなど)を行っていないことになります。このブログ記事では、Screaming FrogがすべてのURLをクロールしていない理由と、その問題を解決する方法を検証します。Screaming FrogがすべてのURLをクロールしてくれないとお困りの方は、ぜひご期待ください!お楽しみに

目次
Screaming FrogがすべてのURLをクロールしないのを修正する方法
ScreamingFrogがすべてのサブドメインをクロールしない理由はいくつかあります。 ウェブサイト最も一般的なのは、Screaming Frogのようなクローラーをブロックするようにウェブサイトが設定されている場合です。
robots.txtでブロックされています。

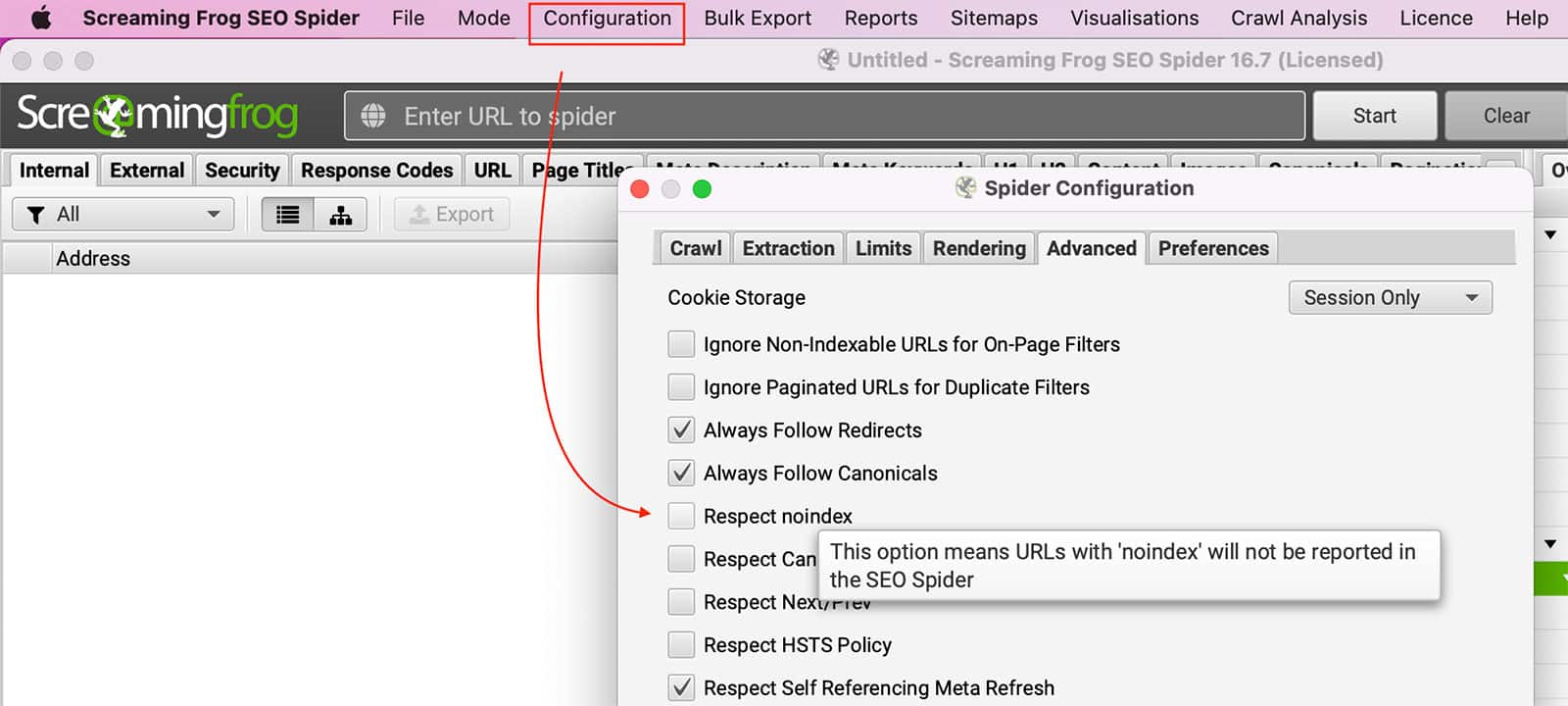
Robots.txtでブロックできること スクリーミングフロッグ ページをクロールします。SEOスパイダーがrobots.txtを無視するように設定するには、次の手順に従います。 コンフィギュレーション >> スパイダー >> アドバンスト >> チェックをはずす リスペクト インデックスなし を設定します。
また、次のこともできる。 変更 あなたの ユーザーエージェント まで グーグルボット をクリックして、そのウェブサイトがクロールを許可しているかどうかを確認する。
Robots.txt robots.txtは、ウェブクローラー(ボット)に対して、ウェブサイト上でアクセスを許可されているページを指示するために使用されます。ボットがrobots.txtで特にアクセスを禁止されているページにアクセスしようとすると、ウェブマスターがこのページのクロールを望んでいないというメッセージを受け取ります。これは意図的な場合もあります。例えば、サイトオーナーはボットが機密情報をインデックスするのを防ぎたい場合があります。また、単に見落としによる場合もある。理由の如何にかかわらず、robots.txtによってブロックされたサイトは、クロールしようとする誰もがアクセスできなくなる。
nofollow」属性は、クロールされないリンクに存在します。

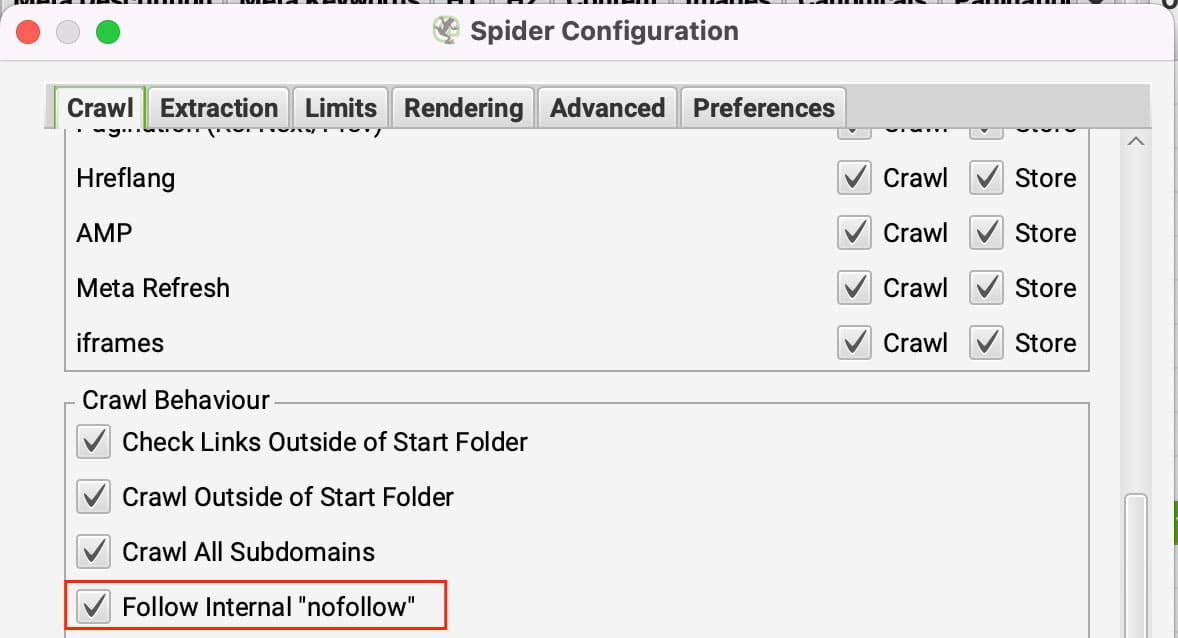
Nofollowリンクは意図したとおりの働きをします。 ハイジャック犯 リンクをたどらないページ上のすべてのリンクがnofollowに設定されている場合、Screaming Frogは行き場を失います。これを回避するには、Screaming Frogがnofollowの内部リンクをフォローするように設定します。
で更新することができます。 コンフィギュレーション >> スパイダー の下に クロールタブ をクリックしてください。 フォロー内部'nofollow' のリンクです。
このページには、ページレベルの 'nofollow' 属性が設定されています。
があります。 ページレベルnofollow属性 は、HTTPヘッダのmeta robotsタグかX-Robots-Tagで設定します。これらは「ディレクティブ」タブの「nofollow」フィルターで見ることができます。ページレベルのnofollow属性は、検索エンジンがページ上のリンクをたどらないようにするために使われます。
信頼性の低い、あるいは重要でない情報源へのリンクを含むページに有効です。nofollow属性を設定することで、検索エンジンにページ上のリンクをたどらないように指示することになります。これにより、サイトの検索エンジン・ランキングは向上しますが、クロールはできなくなります。
Noindexタグを無視するには、次のようにします。 コンフィギュレーション >> スパイダー >> アドバンスト >> チェックをはずす その noindexを尊重する を設定します。
User-Agentがブロックされています。

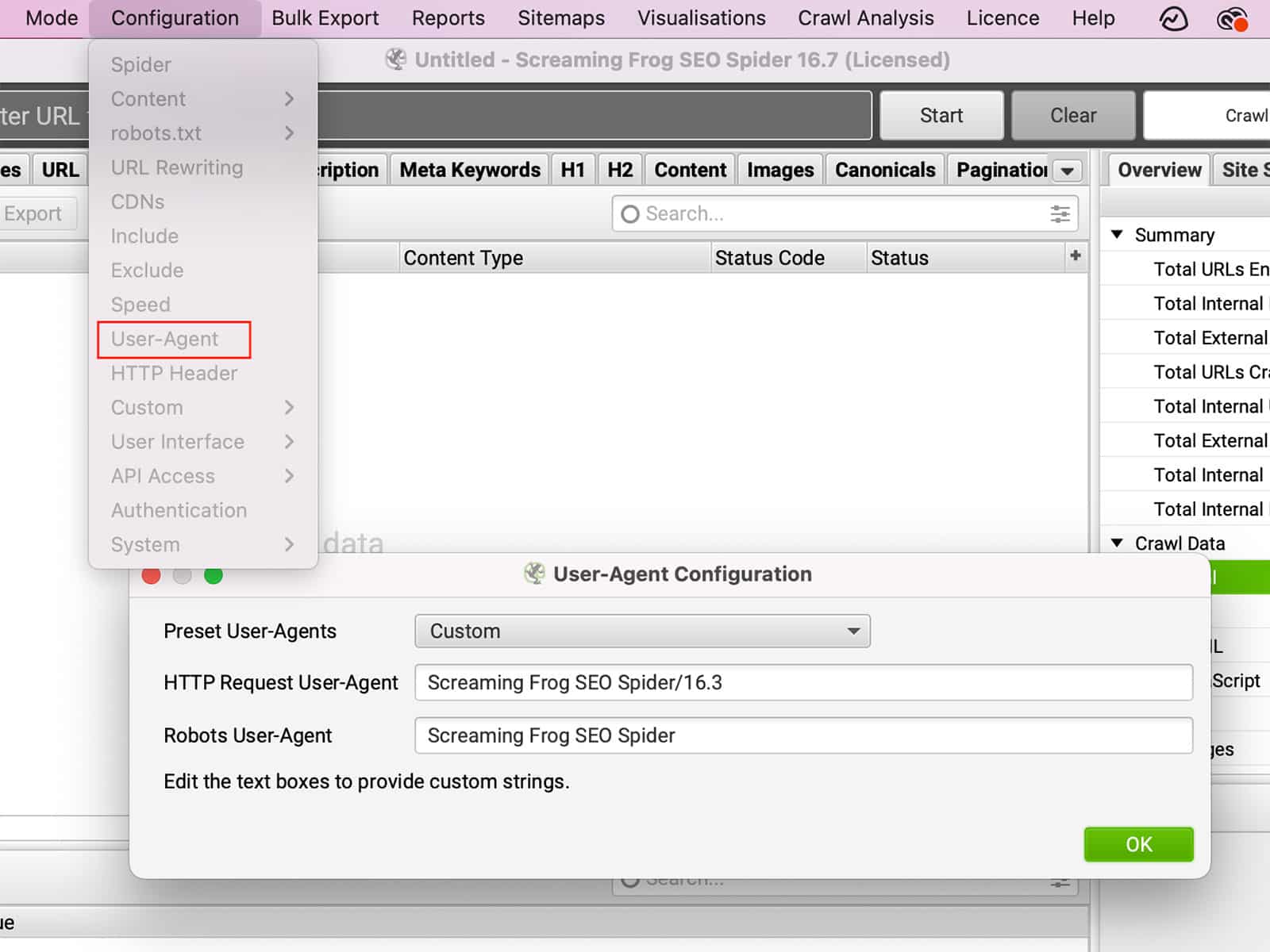
があります。 ユーザーエージェント は、お使いのブラウザから訪問先のウェブサイトに送信されるテキスト文字列です。ユーザーエージェントは、お客様のブラウザ、オペレーティングシステム、さらにお客様のデバイスに関する情報を提供することができます。この情報に基づいて、ウェブサイトはその動作を変更することができます。例えば、お客様がモバイル端末を使用してウェブサイトを訪問した場合、ウェブサイトはお客様をモバイルフレンドリーバージョンにリダイレクトすることがあります。あるいは、ユーザーエージェントを変更して別のブラウザーのふりをした場合、実際のブラウザーでは利用できない機能にアクセスできるようになることがあります。同様に 一部のサイトでは、特定のブラウザを完全にブロックする場合があります。.User-Agentを変更することで、サイトの動作を変更することができ、ブラウジングをより自由にコントロールすることができます。
でUser-Agentを変更することができます。 コンフィギュレーション >> ユーザーエージェント.
このサイトではJavaScriptを使用しています。

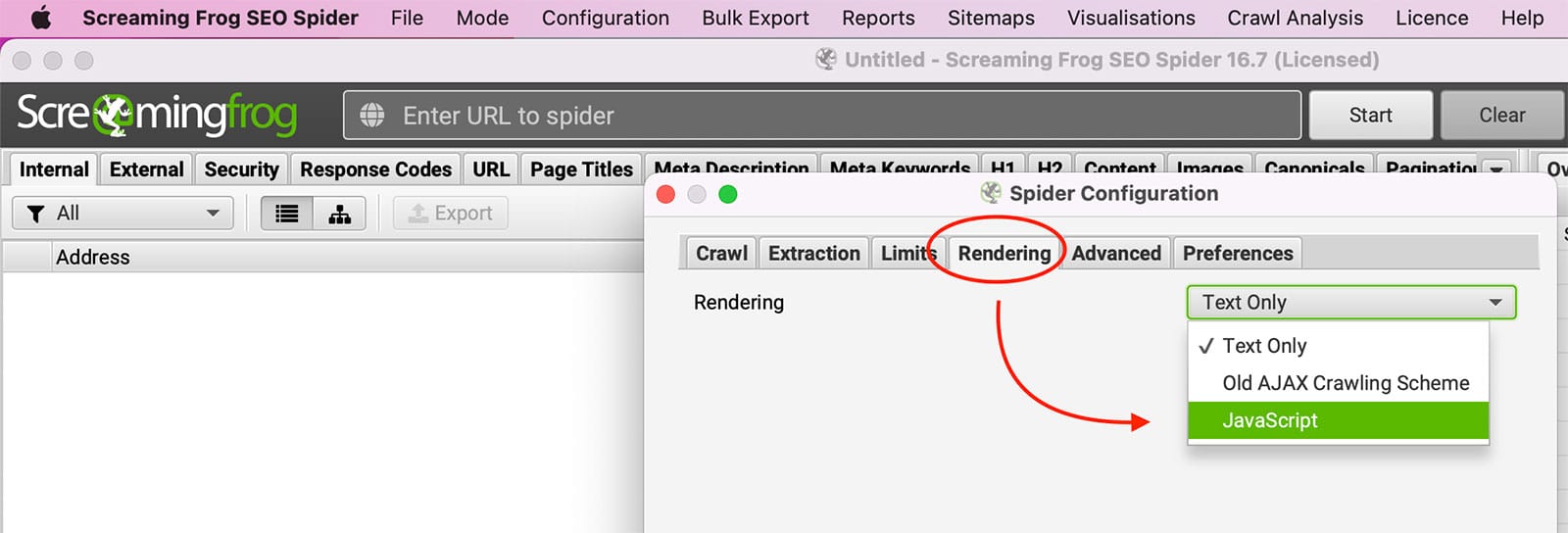
ジャバスクリプト は、インタラクティブなウェブページを作成するためによく使われるプログラミング言語です。JavaScriptを有効にすると、ページが読み込まれたときに自動的に実行され、ページ全体を更新することなくページ上の項目を変更することができます。例えば、JavaScriptを使ってドロップダウンメニューを作成したり、ユーザー入力に基づいて画像を表示したりすることができます。JavaScriptは有益ですが、さまざまな理由からブラウザで無効にすることを好むユーザーもいます。その理由のひとつは、JavaScriptがユーザーのブラウジング活動を追跡するのに使われる可能性があることです。しかし JavaScriptを無効にすると、ウェブサイトの表示方法や特定の機能の動作に問題が生じることもあります。
トライ javascriptのレンダリングを有効にする in Screaming Frog under コンフィギュレーション >> スパイダー >> レンダリング。
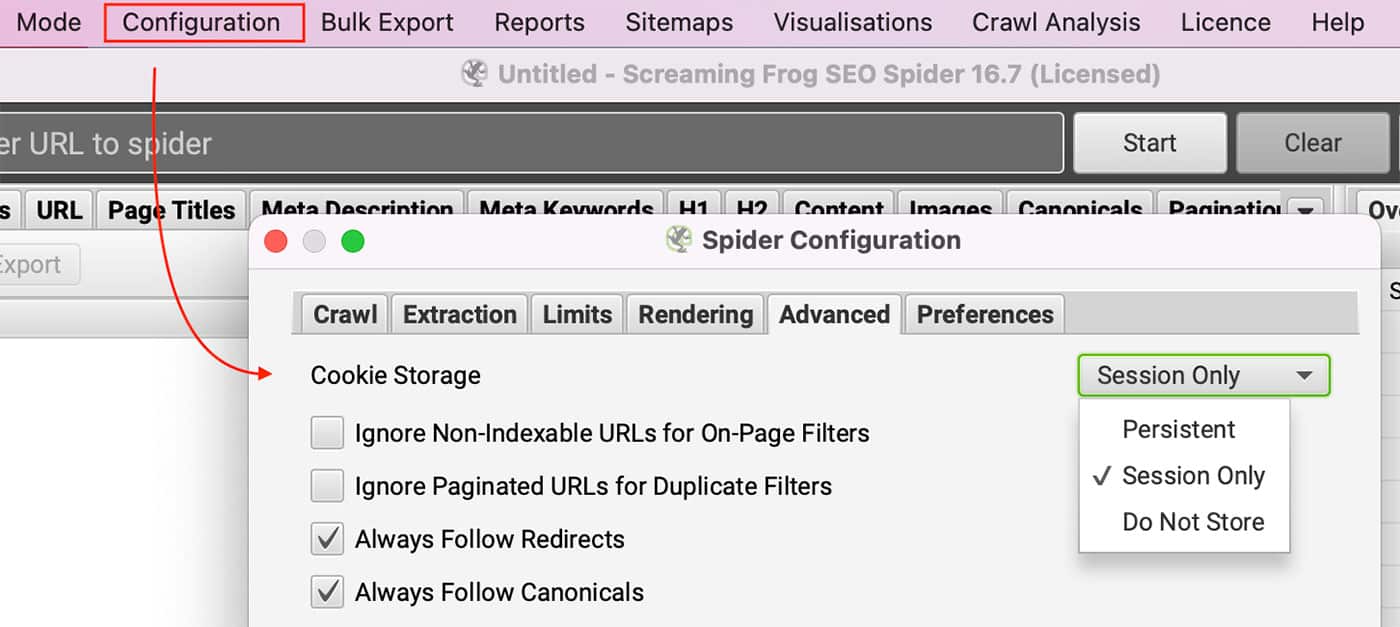
このサイトでは、Cookieを使用しています。

ブラウザのCookieを無効にしてサイトを見ることはできますか?ライセンスをお持ちの方は、以下の方法でCookieを有効にすることができます。 コンフィギュレーション >> スパイダー を選択し セッションのみ 下 クッキーの保存 において 詳細設定タブ.
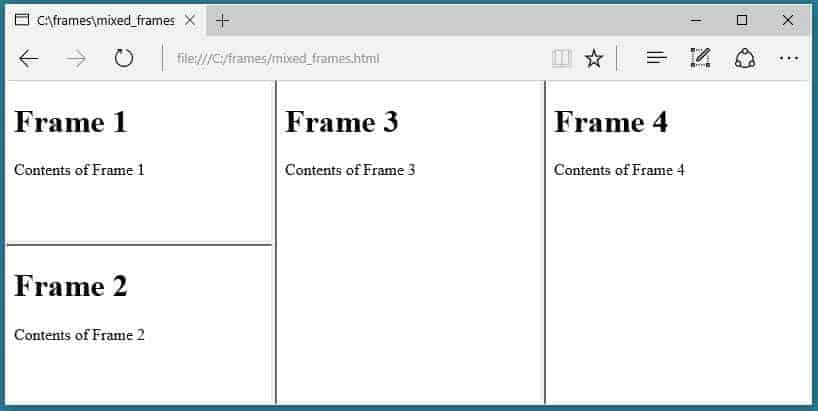
本サイトではフレームセットを使用しています。

SEOスパイダーは、frame-src属性をクロールしません。
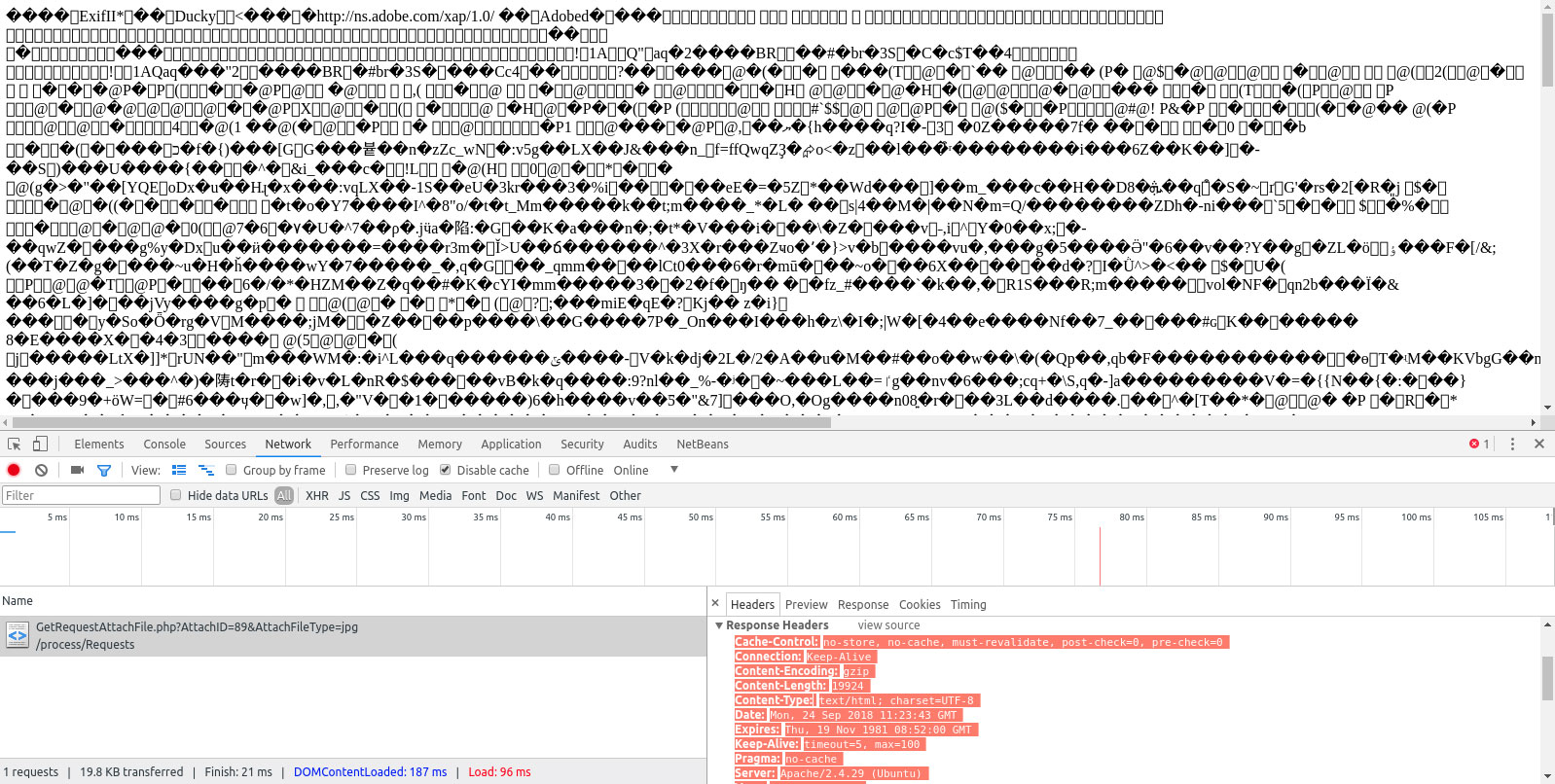
Content-Typeヘッダーが、そのページがHTMLであることを示さなかった。

これはContent欄に表示され、text/HTMLまたはapplication/xhtml+xmlのどちらかである必要があります。
結論
Screaming Frog SEOスパイダーは、ウェブサイトを監査するための優れたツールですが、すべてのURLを確実にクロールすることが重要です。もし 監査に必要な完全なデータScreamingFrogの設定方法に問題がある可能性があります。このブログ記事では、なぜ スクリーミングフロッグ はすべてのURLをクロールしていない可能性があり、どのように問題を解決すればよいのでしょうか?これらの問題を解決することで、Screaming Frogの監査からより包括的なデータを得ることができ、SEO戦略を改善することができます。ウェブサイト監査にScreaming Frogを使用してみましたか?機能を改善するためのヒントはありますか?
よくあるご質問
なぜScreaming FrogはすべてのURLをクロールしないのですか?
公開日: 2022-06-07
更新日: 2024-09-16