尖叫青蛙 (https://www.screamingfrog.co.uk)是抓取网站和提取数据的优秀工具,但如果它没有抓取所有 URLs如果您没有对您的电子商务网站进行高质量的技术性搜索引擎优化审核(审核页面元描述、响应代码、内部链接、检查重复内容、页面标题、反向链接、alt 文本等),那么您的网站就不会被抓取。在这篇博文中,我们将探讨 Screaming Frog 为什么没有抓取所有 URL 以及如何解决这个问题。因此,如果您在让 Screaming Frog 抓取所有 URL 时遇到困难,请继续关注!您将大饱眼福。

目录
如何解决Screaming Frog没有抓取所有URL的问题
有几种原因导致 Screaming Frog 可能无法抓取以下站点上的所有子域 网站最常见的是,该网站被配置为阻止像尖叫蛙这样的爬虫。
该网站被robots.txt屏蔽了。

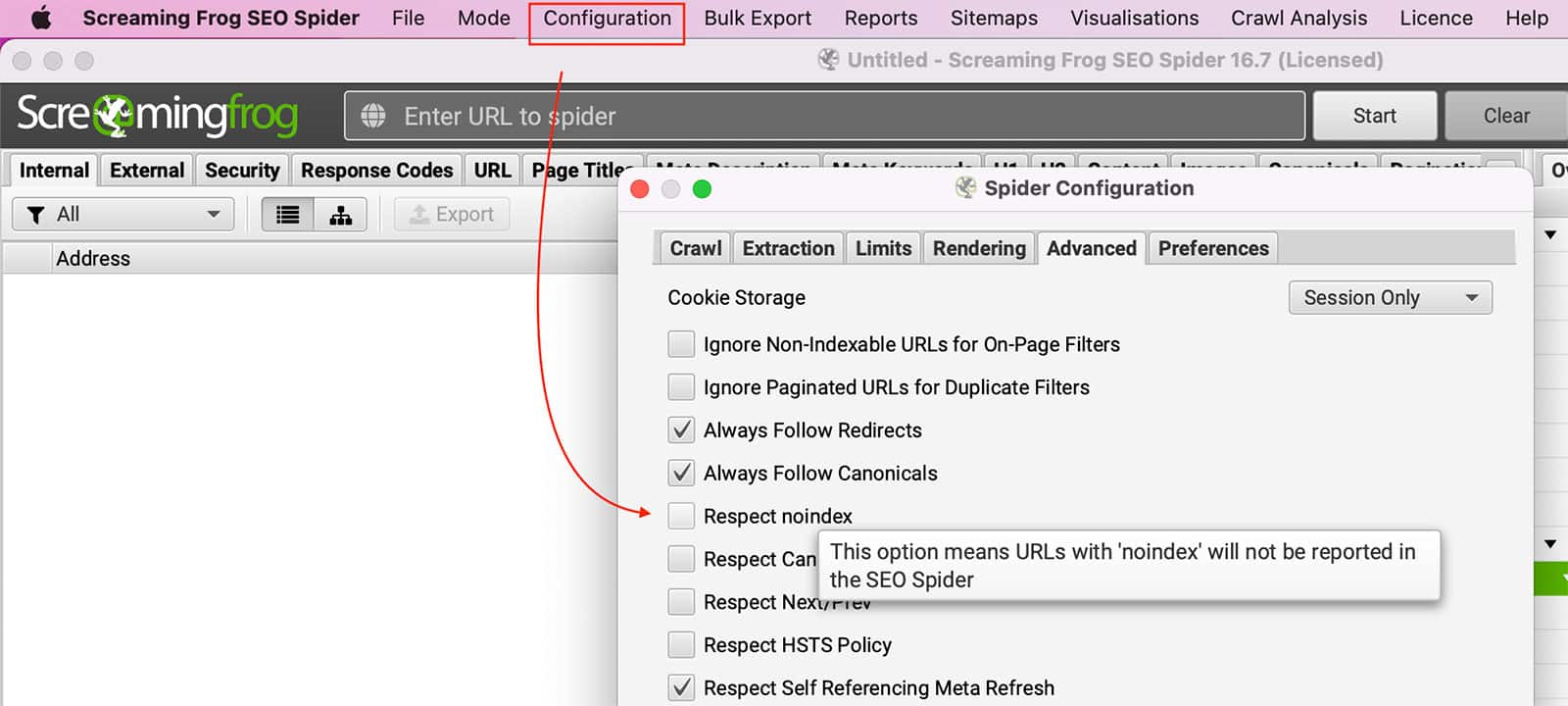
Robots.txt可以阻止 尖叫的青蛙 抓取页面。您可以设置 SEO Spider 忽略 robots.txt,方法是进入 配置 >> 蜘蛛 >> 高级 >> 取消勾选 尊重 没有索引 设置。
您还可以 改变 您的 用户代理 至 谷歌机器人 以查看网站是否允许抓取。
Robots.txt robots.txt 用于指示网络爬虫或 "机器人 "可以访问指定网站的哪些内容。当机器人试图访问 robots.txt 文件中明确禁止访问的页面时,它将收到一条站长不希望抓取该页面的信息。在某些情况下,这可能是有意为之。例如,网站所有者可能希望防止机器人索引敏感信息。在其他情况下,可能只是因为疏忽。无论原因如何,被 robots.txt 屏蔽的网站将无法被任何人抓取。
在不被抓取的链接上存在'nofollow'属性。

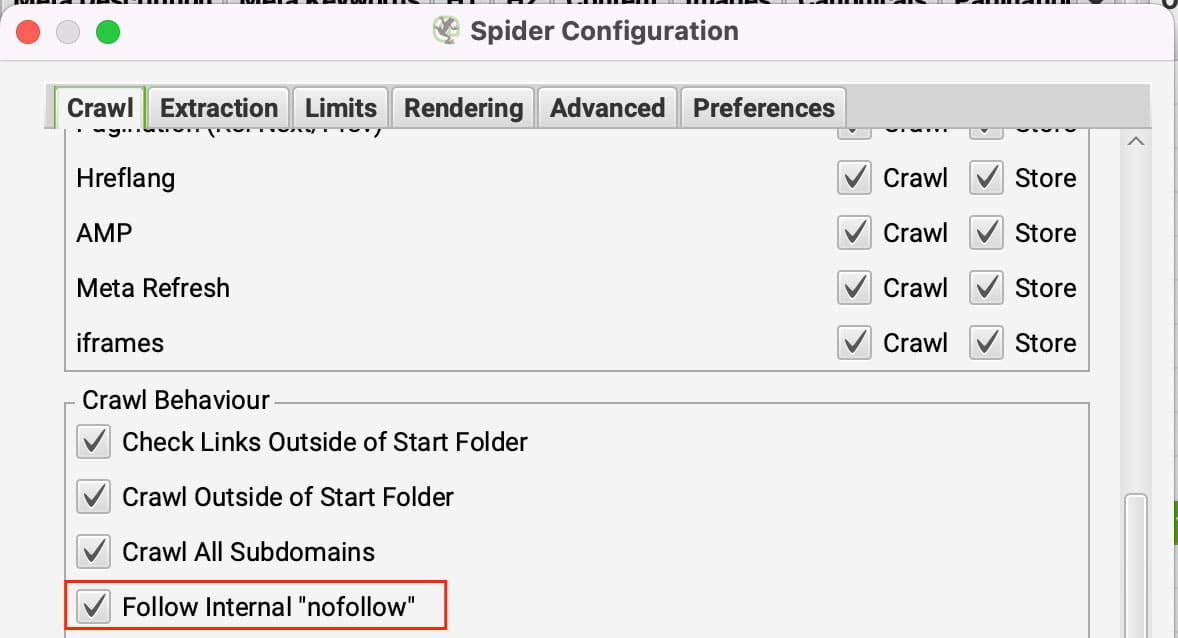
无标签链接的作用是,它们告诉人们 爬虫 不跟踪链接。如果页面上的所有链接都设置为 nofollow,那么 Screaming Frog 就无处可去。要绕过这一点,您可以将 Screaming Frog 设置为跟踪内部 nofollow 内部链接。
你可以在以下文件中更新这个选项 配置 >> 蜘蛛 根据 抓取标签 点击 关注内部'nofollow'。 链接。
该页面有一个页面级别的 "nofollow "属性。
ǞǞǞ 页级nofollow属性 由 HTTP 头中的 meta robots 标签或 X-Robots-Tag 设置。这些可以在 "指令 "选项卡的 "Nofollow "过滤器中看到。页面级 nofollow 属性用于防止搜索引擎跟踪页面上的链接。
这对于包含指向不可靠或不重要来源的链接的页面非常有用。通过设置 nofollow 属性,您可以告诉搜索引擎不要跟踪页面上的链接。这将有助于提高网站在搜索引擎中的排名,但会阻止搜索引擎抓取网站。
要忽略Noindex标签,你必须到 配置 >> 蜘蛛 >> 高级 >> 取消勾选 的 尊重无索引 设置。
用户代理被阻止了。

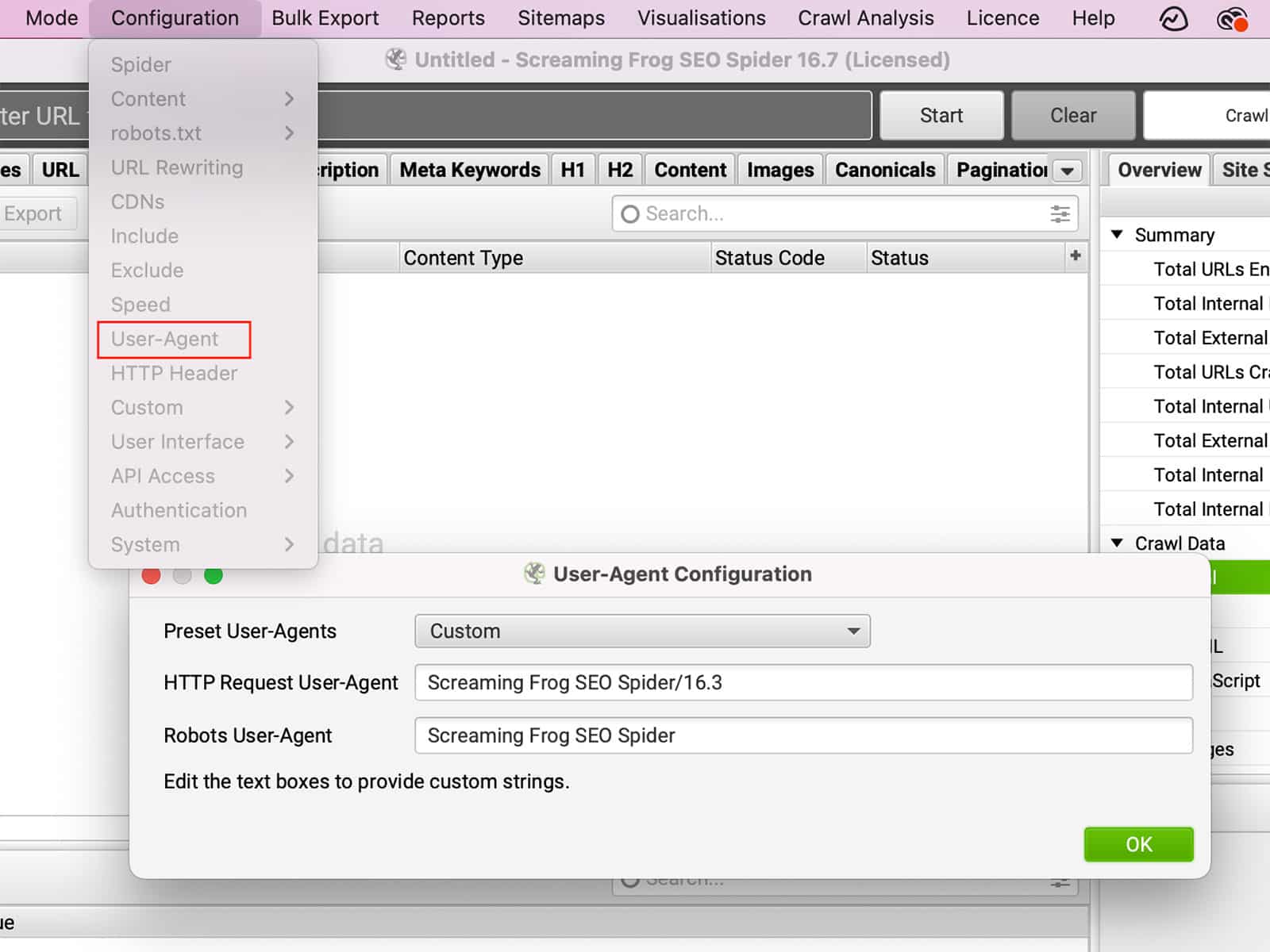
ǞǞǞ 用户代理 是一个文本字符串,由你的浏览器发送至你正在访问的网站。用户代理可以提供有关你的浏览器、操作系统、甚至你的设备的信息。基于这些信息,网站可以改变其行为方式。例如,如果你使用移动设备访问一个网站,该网站可能会将你重定向到该网站的移动友好版本。或者,如果你改变User-Agent以假装是一个不同的浏览器,你可能能够访问你的实际浏览器中没有的功能。同样地。 有些网站可能会完全屏蔽某些浏览器.通过改变用户代理,你可以改变一个网站的行为方式,让你对你的浏览体验有更多的控制。
你可以在下面改变User-Agent 配置 >> 用户代理.
该网站需要JavaScript。

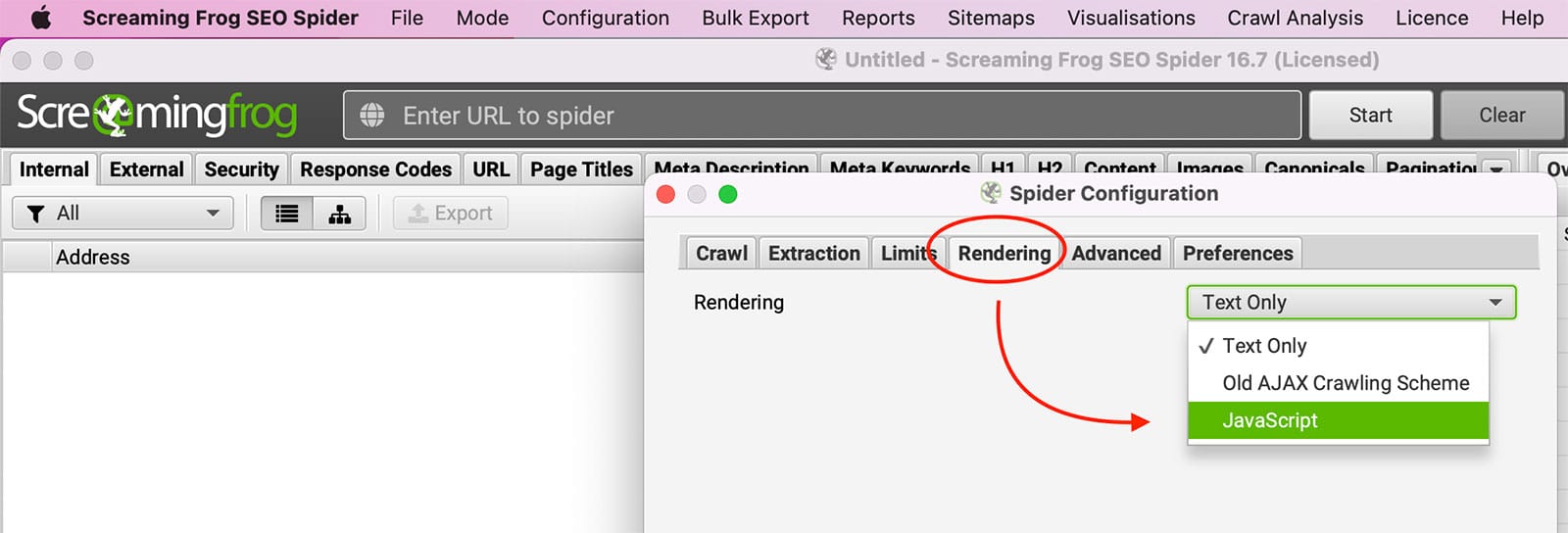
脚本 是一种编程语言,常用于创建交互式网页。启用 JavaScript 后,它可以在加载页面时自动运行,使页面上的项目无需刷新整个页面即可更改。例如,JavaScript 可用于创建下拉菜单、根据用户输入显示图像等。虽然 JavaScript 有很多好处,但出于各种原因,有些用户还是喜欢在浏览器中禁用 JavaScript。原因之一是 JavaScript 可用于跟踪用户的浏览活动。但是 禁用 JavaScript 还可能导致网站的显示方式或某些功能的工作方式出现问题。
尝试 启用JavaScript渲染 在 "尖叫青蛙 "内的 配置 >> 蜘蛛 >> 效果图
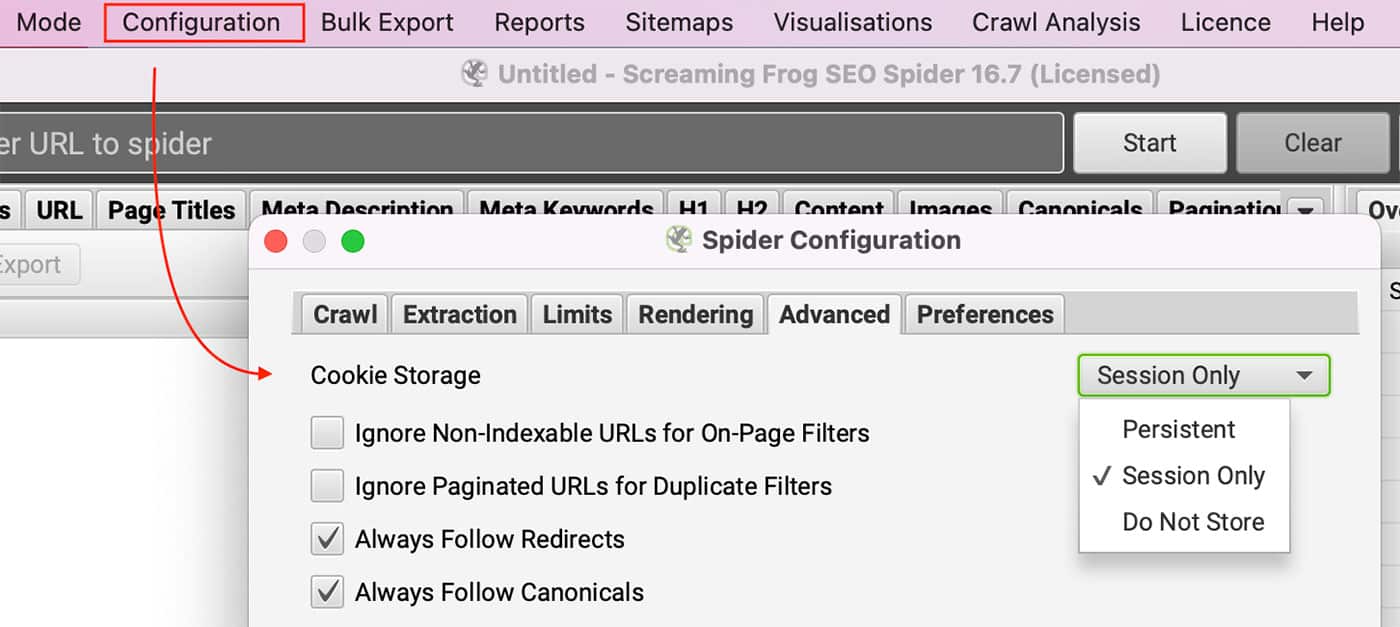
本网站需要Cookies。

您能否在浏览器中禁用cookie来浏览本网站?有许可证的用户可以通过以下方式启用cookies 配置 >> 蜘蛛 并选择 仅限会议 根据 饼干存储 在 高级标签.
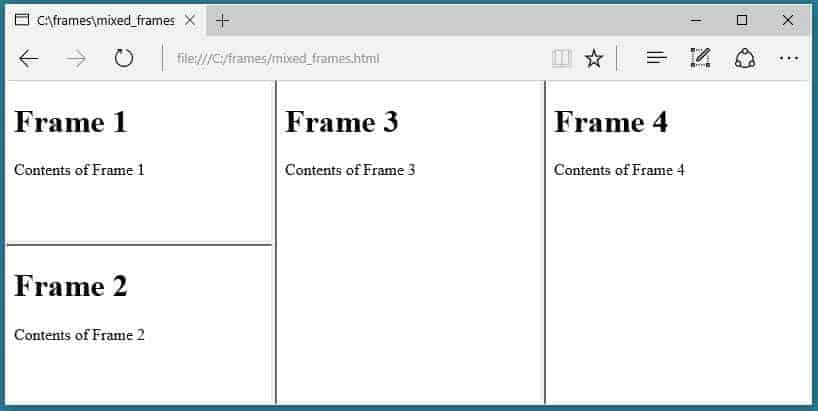
该网站使用框架集。

SEO蜘蛛不抓取框架-src属性。
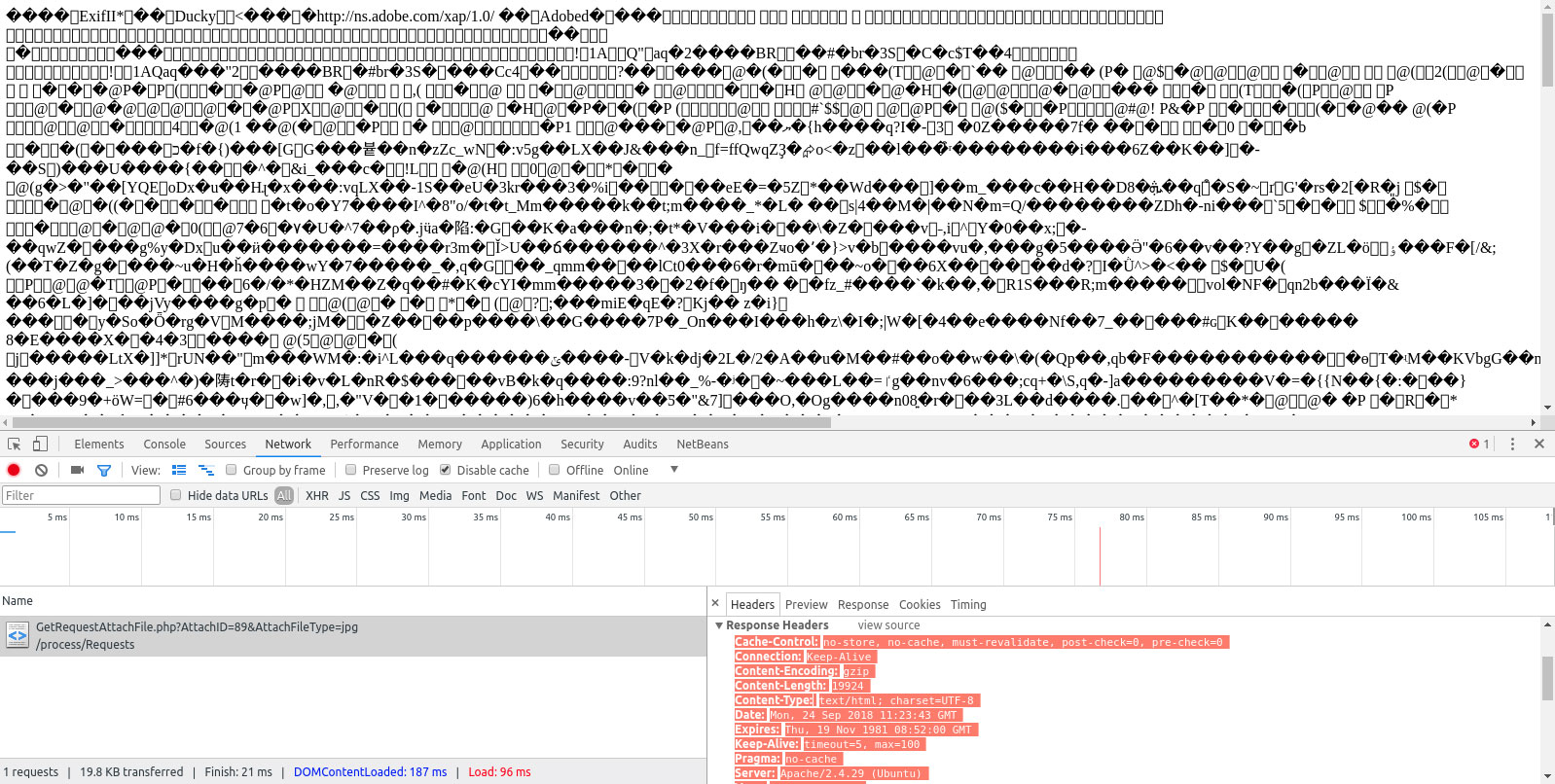
内容类型标头没有表明该页面是HTML。

这显示在内容栏中,应该是文本/HTML或应用/xhtml+xml。
总结
Screaming Frog SEO 蜘蛛是审核网站的绝佳工具,但确保抓取所有 URL 至关重要。如果您没有获得 完整的审计数据可能是 Screaming Frog 的配置出现了问题。这篇博文探讨了为什么 尖叫的青蛙 可能没有抓取您的所有 URL 以及如何解决问题。解决了这些问题,您就能从 Screaming Frog 审计中获得更全面的数据,并改进您的搜索引擎优化策略。您尝试过使用 Screaming Frog 进行网站审核吗?您有什么改进其功能的建议?
常见问题
为什么Screaming Frog没有抓取所有的URL?
发表于:2022-06-07
更新日期: 2024-09-16