Screaming Frog (https://www.screamingfrog.co.uk) is an excellent tool for crawling websites and extracting data, but if it’s not crawling all URLs, you won’t be performing a quality technical SEO audit (auditing on-page meta descriptions, response codes, internal linking, checking duplicate contents, page titles, backlinks, alt texts, etc) on your e-commerce sites. In this blog post, we’ll examine why Screaming Frog isn’t crawling all URLs and how you can fix the issue. So, if you’re having trouble getting Screaming Frog to crawl all of your URLs, stay tuned! You’re in for a treat.

How to fix Screaming Frog not crawling all URLs
There are several reasons Screaming Frog may not crawl all subdomains on a website; the most common is that the website has been configured to block crawlers like Screaming Frog.
1. Check HTTP Status Codes First
If Screaming Frog is only crawling one page or returning far fewer URLs than expected, the first thing to check is the Status Code column in the crawl results. The status code tells you exactly why a URL was or wasn’t crawled successfully.
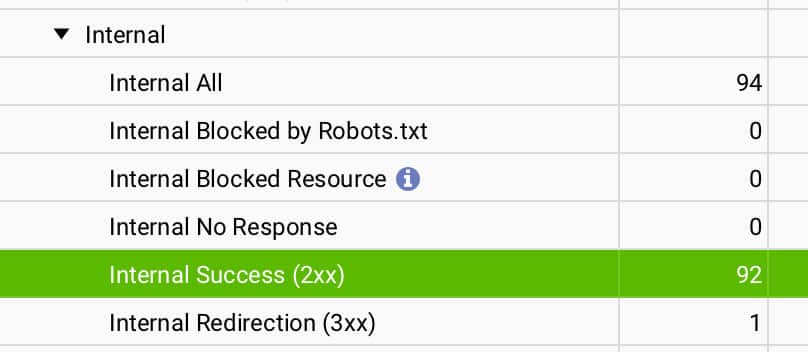
Here’s a quick reference for the most common status codes you’ll encounter:
| Status Code | What It Means | What to Do |
|---|---|---|
| 200 | Page loaded successfully | No action needed |
| 301 | Permanent redirect | Check redirect destination is correct |
| 302 | Temporary redirect | Verify this is intentional, not a misconfiguration |
| 403 | Forbidden | The server is blocking the request. Try changing your User-Agent or check if the site requires authentication |
| 404 | Page not found | The URL is broken or the page has been removed |
| 429 | Too many requests | The server is rate limiting your crawl. Reduce your crawl speed |
| 500 | Internal server error | The server encountered an error. This is a server-side issue, not a Screaming Frog problem |
| 503 | Service unavailable | The server is temporarily overloaded or under maintenance |
| 0 | No HTTP response | DNS lookup failed, connection timed out, or the site is unreachable |
If you see a mix of 200s and errors, the status codes will point you toward the exact problem. A crawl full of 403s suggests the server is blocking your requests. A crawl full of 0s points to a connection or DNS issue.
2. Crawl Depth and URL Limits
One of the most overlooked reasons Screaming Frog doesn’t crawl all URLs is that a crawl limit has been set. This is especially common when using the free version, which limits crawls to 500 URLs.

Even in the paid version, check the Limits tab under Configuration > Spider > Limits. Two settings to look for:
- Limit Crawl Depth. This controls how many clicks deep from the start URL Screaming Frog will crawl. If this is set to 3, any page that requires 4 or more clicks to reach from the homepage will be excluded. Set this to 0 for unlimited depth, or increase it to match your site’s architecture.
- Limit Crawl Total. This caps the total number of URLs crawled. If your site has 10,000 pages but this is set to 5,000, the crawl will stop halfway through. Set this to 0 for no limit.
If you’re consistently seeing fewer URLs than expected, these two settings are worth checking before troubleshooting anything else.
3. The Site is Blocked by Robots.txt
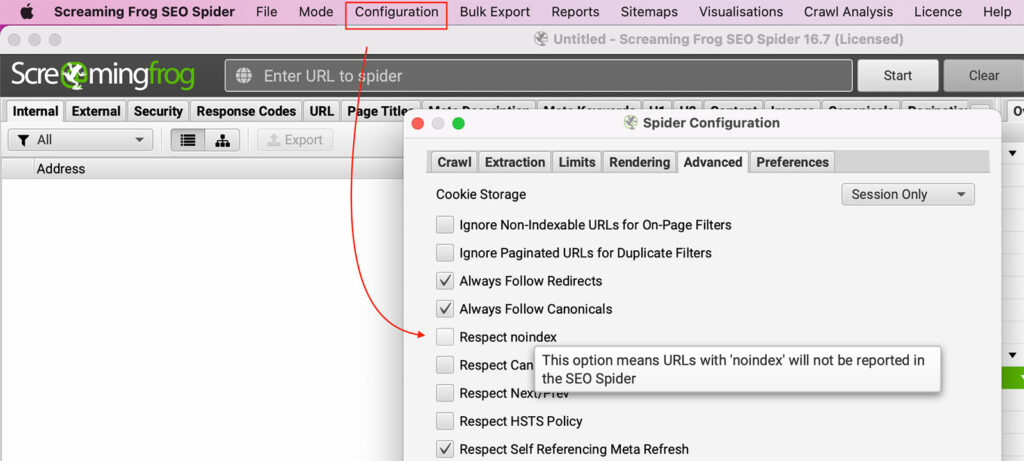
Robots.txt can block Screaming Frog from crawling pages. You can configure the SEO Spider to ignore robots.txt by going to Configuration > Spider > Advanced > Uncheck Respect Noindex setting.
You can also change your User Agent to GoogleBot to see if the website allows that crawl.
Robots.txt is used to instruct web crawlers, or “bots,” on what they are allowed to access on a given website. When a bot tries to access a page that is specifically disallowed in the robots.txt file, it will receive a message that the webmaster does not want this page crawled. In some cases, this may be intentional. For example, a site owner may want to prevent bots from indexing sensitive information. In other cases, it may simply be due to an oversight. Regardless of the reason, a site that is blocked by robots.txt will be inaccessible to anyone who tries to crawl it.
4. The ‘Nofollow’ Attribute is Present on Links Not Being Crawled
Nofollow links do as intended, they tell crawlers not to follow the links. If all links are set to nofollow on a page, then Screaming Frog has nowhere to go. To bypass this, you can set Screaming Frog to follow internal nofollow links.
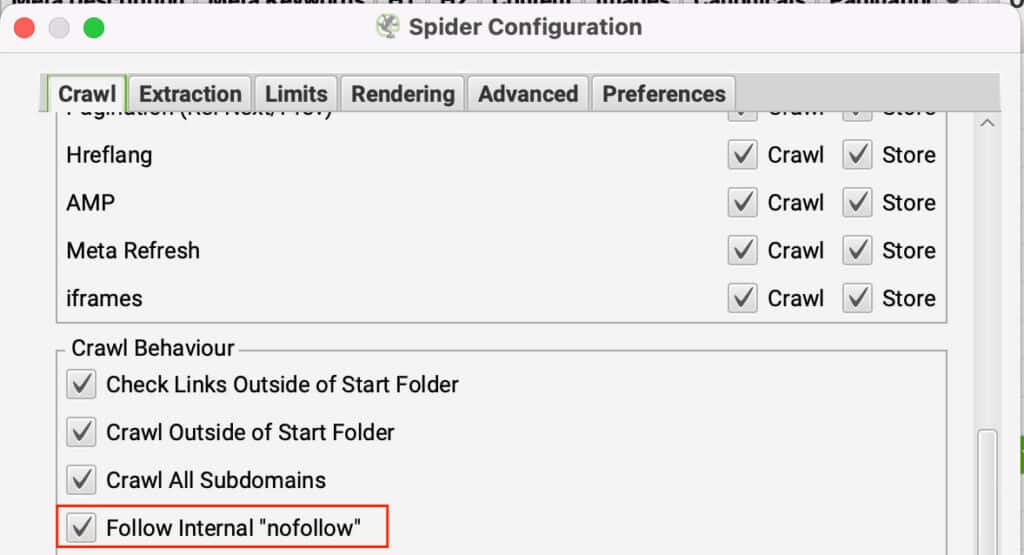
You can update this option in Configuration > Spider under the Crawl tab by clicking on Follow internal ‘nofollow’ links.
5. The Page Has a Page-Level ‘Noindex’ Attribute
A page-level noindex directive can be set by either a meta robots tag or an X-Robots-Tag in the HTTP header. These can be seen in the “Directives” tab in the “Noindex” filter. The noindex directive tells search engines not to index the page, and when Screaming Frog is configured to respect it, those pages may be excluded from your crawl results.

This is common on pages like login screens, thank-you pages, or staging environments where the site owner doesn’t want the content appearing in search results. If Screaming Frog is skipping pages that you need to audit, the noindex directive may be the cause.
To ignore noindex tags, go to Configuration > Spider > Advanced > Uncheck the Respect noindex setting.
6. The User-Agent is Being Blocked
The User-Agent is a string of text that is sent by your browser to the website you are visiting. The User-Agent can provide information about your browser, operating system, and even your device. Based on this information, the website can change the way it behaves. For example, if you visit a website using a mobile device, the website may redirect you to a mobile-friendly version of the site. Alternatively, if you change the User-Agent to pretend to be a different browser, you may be able to access features that are not available in your actual browser. Likewise, some sites may block certain browsers altogether. By changing the User-Agent, you can change the way a site behaves, giving you more control over your browsing experience.
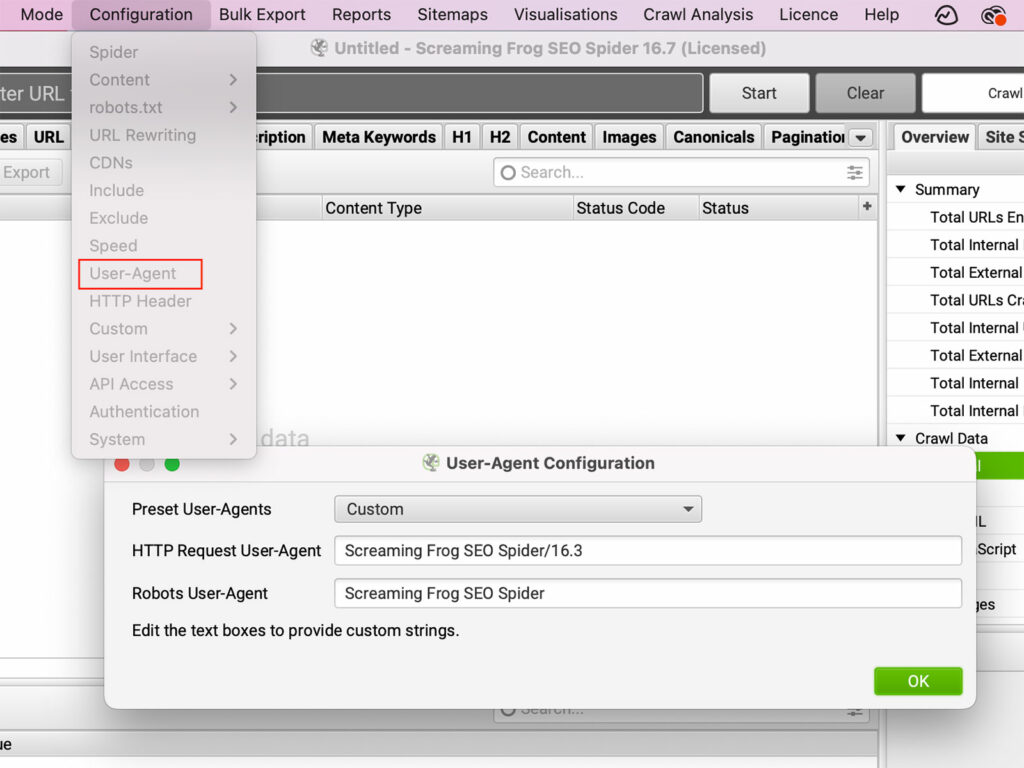
You can change the User-Agent under Configuration > User-Agent.
7. Rate Limiting and Crawl Speed
If your crawl starts strong but then URLs begin returning 429 (Too Many Requests) status codes, the server is rate limiting your requests. This is the server telling Screaming Frog to slow down.
Many web servers and CDNs (like Cloudflare) impose rate limits to prevent abuse. When Screaming Frog sends requests too quickly, the server starts rejecting them.
To fix this, reduce your crawl speed under Configuration > Speed. You can limit the number of concurrent threads (try lowering to 1 or 2) and add a delay between requests. A crawl rate of 1 URL per second is a safe starting point for servers that are rate limiting aggressively.
Also check the User-Agent you’re using. Some servers apply stricter rate limits to unknown or bot-like user-agents. Switching to a Chrome user-agent under Configuration > User-Agent may reduce the likelihood of being throttled.
Keep in mind that crawling too aggressively can also cause server errors (500, 503) on fragile servers, particularly staging or development environments. Always start slow and increase speed only if the server handles it well.
8. The Site Requires JavaScript Rendering
JavaScript is a programming language that is commonly used to create interactive web pages. When JavaScript is enabled, it can run automatically when a page is loaded, making it possible for items on the page to change without the need to refresh the entire page. For example, JavaScript can be used to create drop-down menus, display images based on user input, and much more. While JavaScript can be beneficial, some users prefer to disable it in their browser for various reasons. One reason is that JavaScript can be used to track a user’s browsing activity. However, disabling JavaScript can also lead to issues with how a website is displayed or how certain features work.
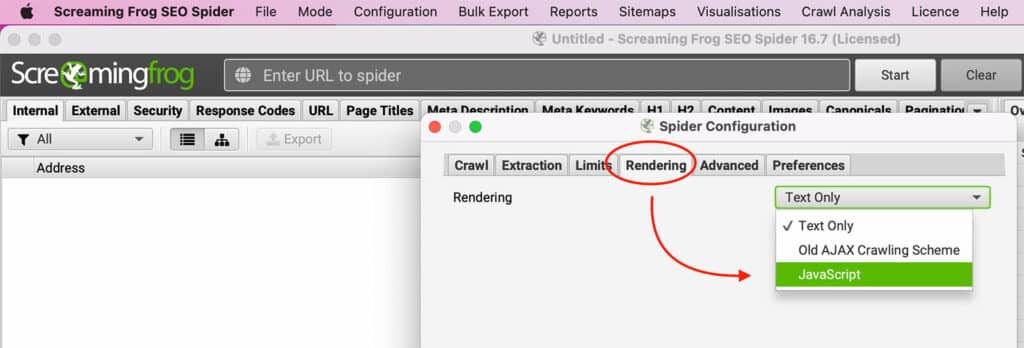
Try enabling JavaScript rendering within Screaming Frog under Configuration > Spider > Rendering.
9. The Site Requires Cookies
Can you view the site with cookies disabled in your browser? Licensed users can enable cookies by going to:
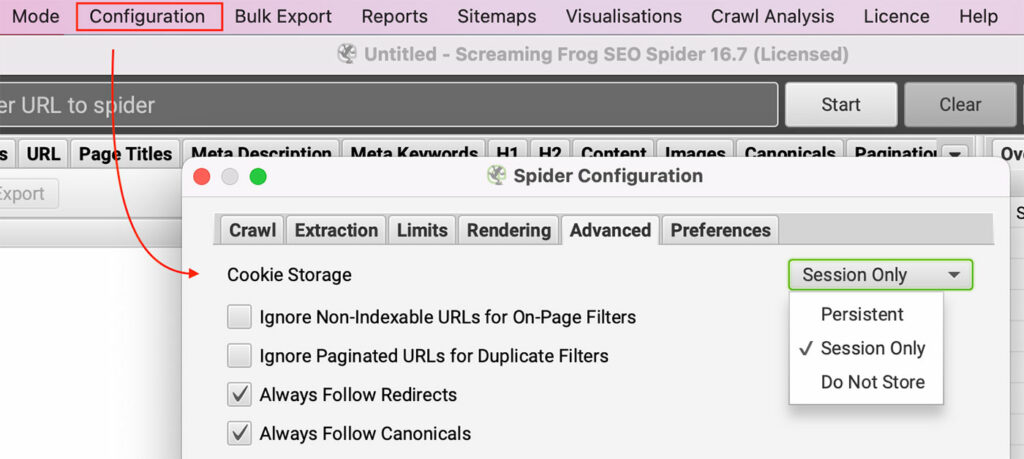
Configuration > Spider and selecting Session only under Cookie Storage in the Advanced tab.
10. Connection Errors, DNS Failures, and Timeouts
When Screaming Frog returns a status code of 0, it means no HTTP response was received at all. This is different from a server error. It means Screaming Frog couldn’t even reach the server.
Common causes include:
- DNS lookup failed. The domain name couldn’t be resolved to an IP address. This can happen if the domain doesn’t exist, your DNS settings are misconfigured, or you’re trying to crawl a staging site on an internal network without the proper DNS or hosts file configuration.
- Connection timeout. Screaming Frog sent a request but the server didn’t respond within the allowed time. This often happens with slow or overloaded servers. You can increase the response timeout under Configuration > Spider > Advanced. Try increasing the response timeout and the AJAX timeout if the site relies heavily on JavaScript.
- Connection refused. The server actively rejected the connection. This is common when a firewall or antivirus software is blocking outbound requests from Screaming Frog, or when the server has IP-based restrictions in place.
- Network connectivity issues. Make sure your own internet connection is stable. If you’re using a proxy, verify your proxy settings under Configuration > System > Proxy. A misconfigured proxy will prevent Screaming Frog from reaching any URLs.
If you’re behind a corporate firewall or VPN, check that Screaming Frog is allowed through. Some antivirus software and firewall rules will block the SEO Spider’s outbound requests entirely.
11. Authentication and Login Requirements
Some websites require authentication before any content is accessible. If Screaming Frog can’t get past a login screen, it will only crawl that one page.
Screaming Frog supports several authentication methods:
- Basic and digest authentication. If the server presents an authentication pop-up (the browser-level username and password dialog, not a web form), you can enter your credentials under Configuration > Authentication. Add the server URL along with your username and password, and Screaming Frog will supply them with each request.
- Web form authentication. For sites that use a standard login form (like a WordPress login page), use Configuration > Authentication > Forms. Screaming Frog can fill in and submit login credentials through the web form, then crawl the authenticated session. This requires JavaScript rendering to be enabled.
- Cookie-based authentication. If neither method works, you can manually supply a session cookie. Log in to the site in your browser, copy the session cookie value, and add it as a custom HTTP header under Configuration > HTTP Headers. Use the format: Cookie: session_id=your_value_here. Screaming Frog will then send that cookie with every request, effectively crawling as a logged-in user.
If you’re working with a staging site or development environment that restricts access by IP address, you’ll need to have your IP allowlisted on the server before Screaming Frog can reach it at all.
12. Crawling Staging and Development Websites
Staging and development sites often have extra layers of protection that prevent crawling. If you’re trying to audit a pre-launch site, here are the most common blockers:
- IP restrictions. Many staging servers only allow access from specific IP addresses. Contact the hosting provider or dev team to have your IP allowlisted.
- Robots.txt blocking everything. Staging sites frequently use a blanket Disallow: / in robots.txt to prevent search engines from indexing unfinished content. You can bypass this in Screaming Frog by unchecking “Respect robots.txt” under Configuration > Spider > Advanced.
- Noindex directives. Staging sites often set noindex on all pages as an extra layer of protection. If you have “Respect noindex” checked, Screaming Frog may skip these pages. Uncheck this setting to crawl them.
- Authentication barriers. See the Authentication section above for handling basic auth, web form login, and cookie-based access.
- Hosts file for custom domains. If the staging site uses a custom domain that isn’t publicly registered in DNS, you may need to add an entry to your local hosts file (or Screaming Frog’s built-in hosts file override) to point the domain to the correct server IP address.
After crawling a staging site, you can use Screaming Frog’s crawl comparison feature and URL mapping to compare the staging crawl against a live site crawl. This helps identify any differences in URLs, redirects, or page structures before pushing changes to production.
13. The Content-Type Header Did Not Indicate the Page is HTML
If the Content-Type header doesn’t indicate HTML (text/html or application/xhtml+xml), Screaming Frog won’t process the page. Check the Content column in your crawl results to identify affected URLs.
14. The Website Uses Framesets
The SEO Spider does not crawl the frame-src attribute. If the site uses framesets, URLs within frames won’t be discovered during the crawl.
Conclusion
The Screaming Frog SEO spider can be an excellent tool for auditing your website, but it’s vital to ensure that all URLs are crawled. If you’re not getting the complete data that you need from your audits, there may be an issue with how Screaming Frog is configured. This blog post looked at why Screaming Frog might not be crawling all your URLs and how to fix the problem. By fixing these issues, you’ll be able to get more comprehensive data from your Screaming Frog audits and improve your SEO strategy. Have you tried using Screaming Frog for your website audits? What tips do you have for improving its functionality?
FAQs
Why is Screaming Frog not crawling all URLs?
Why does Screaming Frog only crawl one page?
Why is Screaming Frog so slow?
Can Screaming Frog crawl password-protected websites?
Published on: 2022-06-07
Updated on: 2026-04-02