Screaming Frog (https://www.screamingfrog.co.uk) is an excellent tool for crawling websites and extracting data, but if it’s not crawling all URLs, you won’t be performing a quality technical SEO audit (auditing on-page meta descriptions, response codes, internal linking, checking duplicate contents, page titles, backlinks, alt texts, etc) on your e-commerce sites. In this blog post, we’ll examine why Screaming Frog isn’t crawling all URLs and how you can fix the issue. So, if you’re having trouble getting Screaming Frog to crawl all of your URLs, stay tuned! You’re in for a treat.

Table of Contents
- How to fix Screaming Frog not crawling all URLs
- The site is blocked by robots.txt.
- The ‘nofollow’ attribute is present on links not being crawled.
- The page has a page-level ‘nofollow’ attribute.
- The User-Agent is being blocked.
- The site requires JavaScript.
- The site requires Cookies.
- The website uses framesets.
- The Content-Type header did not indicate the page is HTML.
- Conclusion
- FAQ
How to fix Screaming Frog not crawling all URLs
There are several reasons Screaming Frog may not crawl all subdomains on a website; the most common is that the website has been configured to block crawlers like Screaming Frog.
The site is blocked by robots.txt.

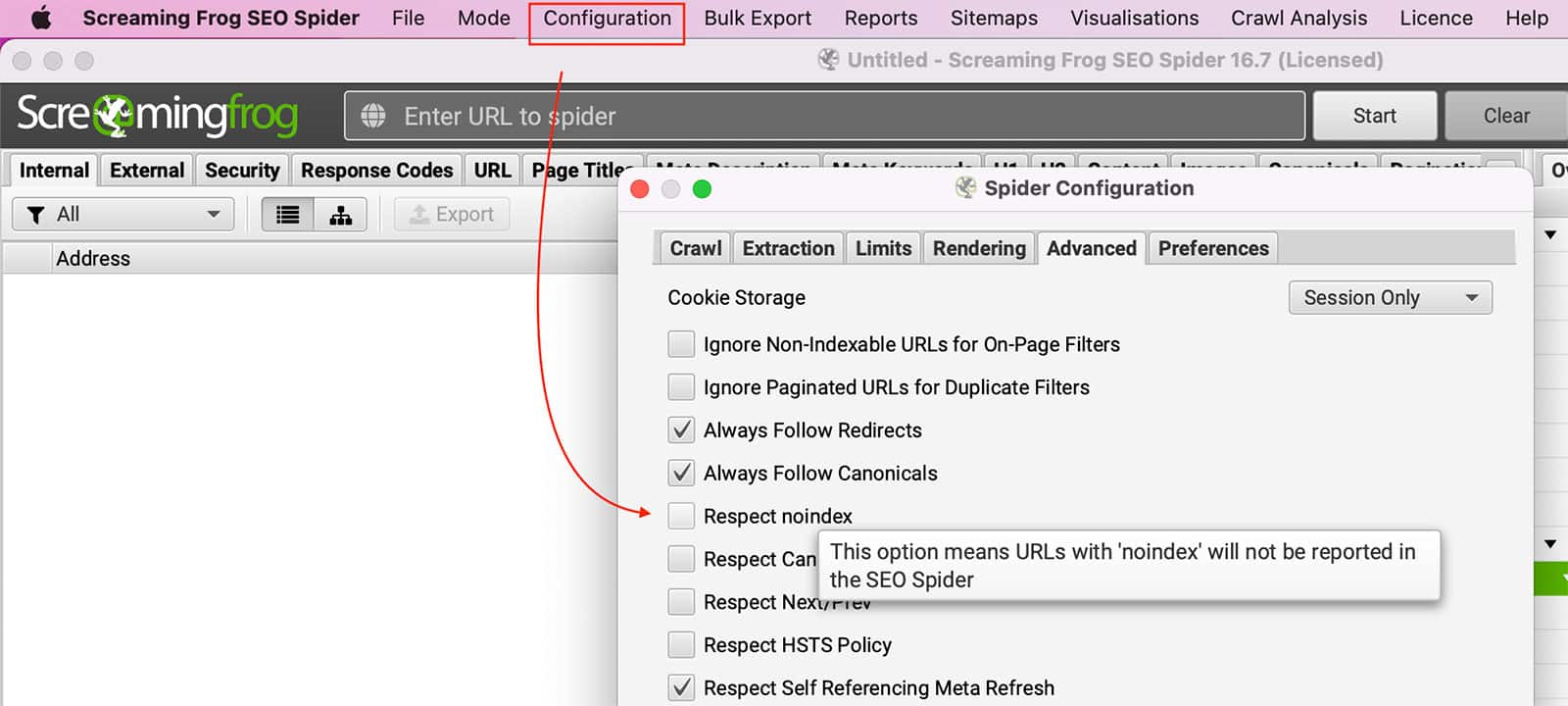
Robots.txt can block Screaming Frog crawl pages. You can configure the SEO Spider to ignore robots.txt by going to Configuration >> Spider >> Advanced >> Uncheck Respect Noindex setting.
You can also change your User Agent to GoogleBot to see if the website allows that crawl.
Robots.txt is used to instruct web crawlers, or “bots,” on what they are allowed to access on a given website. When a bot tries to access a page that is specifically disallowed in the robots.txt file, it will receive a message that the webmaster does not want this page crawled. In some cases, this may be intentional. For example, a site owner may want to prevent bots from indexing sensitive information. In other cases, it may simply be due to an oversight. Regardless of the reason, a site that is blocked by robots.txt will be inaccessible to anyone who tries to crawl it.
The ‘nofollow’ attribute is present on links not being crawled.

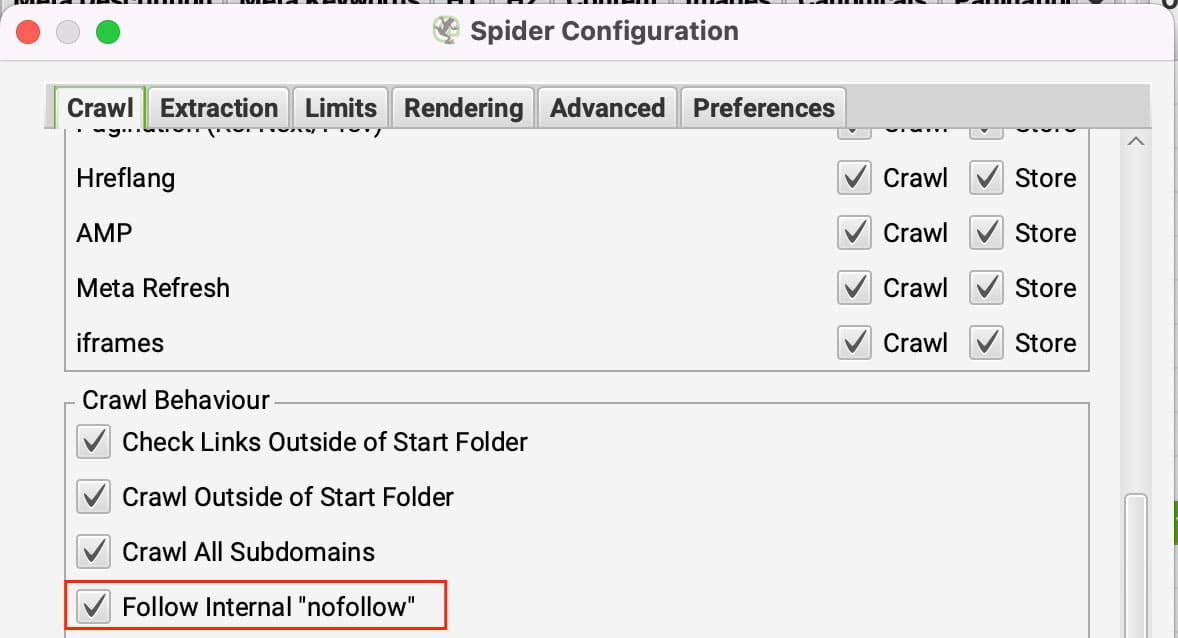
Nofollow links do as intended, they tell crawlers not to follow the links. If all links are set to nofollow on a page, then Screaming Frog has nowhere to go. To bypass this, you can set Screaming Frog to follow internal nofollow internal links.
You can update this option in Configuration >> Spider under the Crawl tab by clicking on Follow internal ‘nofollow’ links.
The page has a page-level ‘nofollow’ attribute.
The page-level nofollow attribute is set by either a meta robots tag or an X-Robots-Tag in the HTTP header. These can be seen in the “Directives” tab in the “Nofollow” filter. The page-level nofollow attribute is used to prevent search engines from following the links on a page.
This is useful for pages that contain links to unreliable or unimportant sources. By setting the nofollow attribute, you are telling search engines that they should not follow the links on the page. This will help to improve your site’s search engine rankings but stop you from crawling the website.
To ignore Noindex tags, you must go to Configuration >> Spider >> Advanced >> Uncheck the Respect noindex setting.
The User-Agent is being blocked.

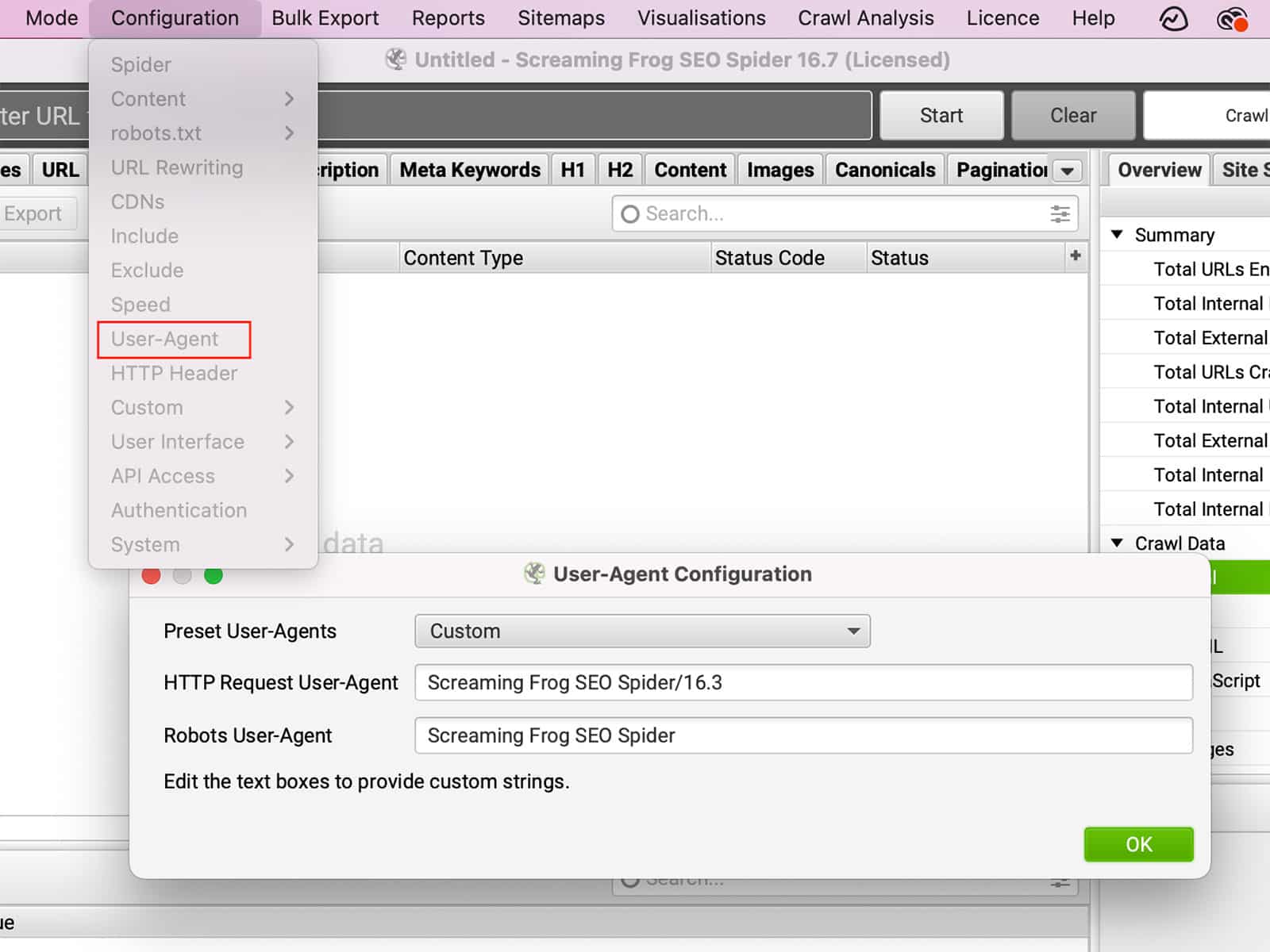
The User-Agent is a string of text that is sent by your browser to the website you are visiting. The User-Agent can provide information about your browser, operating system, and even your device. Based on this information, the website can change the way it behaves. For example, if you visit a website using a mobile device, the website may redirect you to a mobile-friendly version of the site. Alternatively, if you change the User-Agent to pretend to be a different browser, you may be able to access features that are not available in your actual browser. Likewise, some sites may block certain browsers altogether. By changing the User-Agent, you can change the way a site behaves, giving you more control over your browsing experience.
You can change the User-Agent under Configuration >> User-Agent.
The site requires JavaScript.

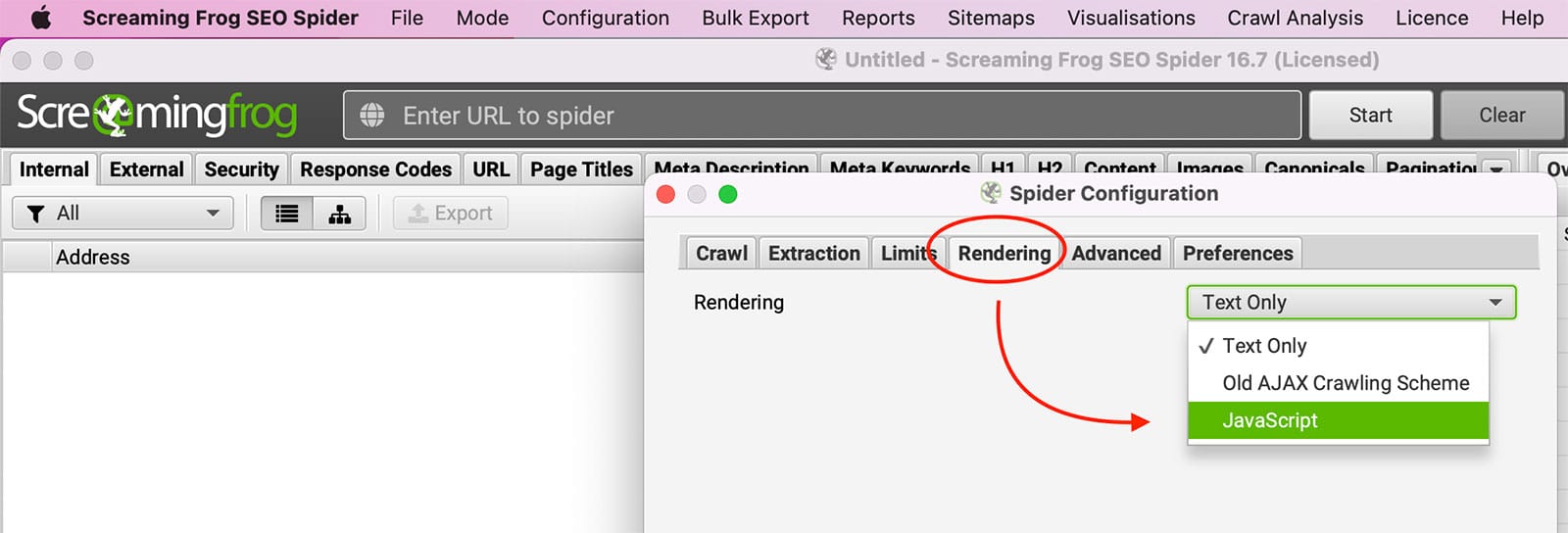
JavaScript is a programming language that is commonly used to create interactive web pages. When JavaScript is enabled, it can run automatically when a page is loaded, making it possible for items on the page to change without the need to refresh the entire page. For example, JavaScript can be used to create drop-down menus, display images based on user input, and much more. While JavaScript can be beneficial, some users prefer to disable it in their browser for various reasons. One reason is that JavaScript can be used to track a user’s browsing activity. However, disabling JavaScript can also lead to issues with how a website is displayed or how certain features work.
Try enabling javascript rendering within Screaming Frog under Configuration >> Spider >> Rendering.
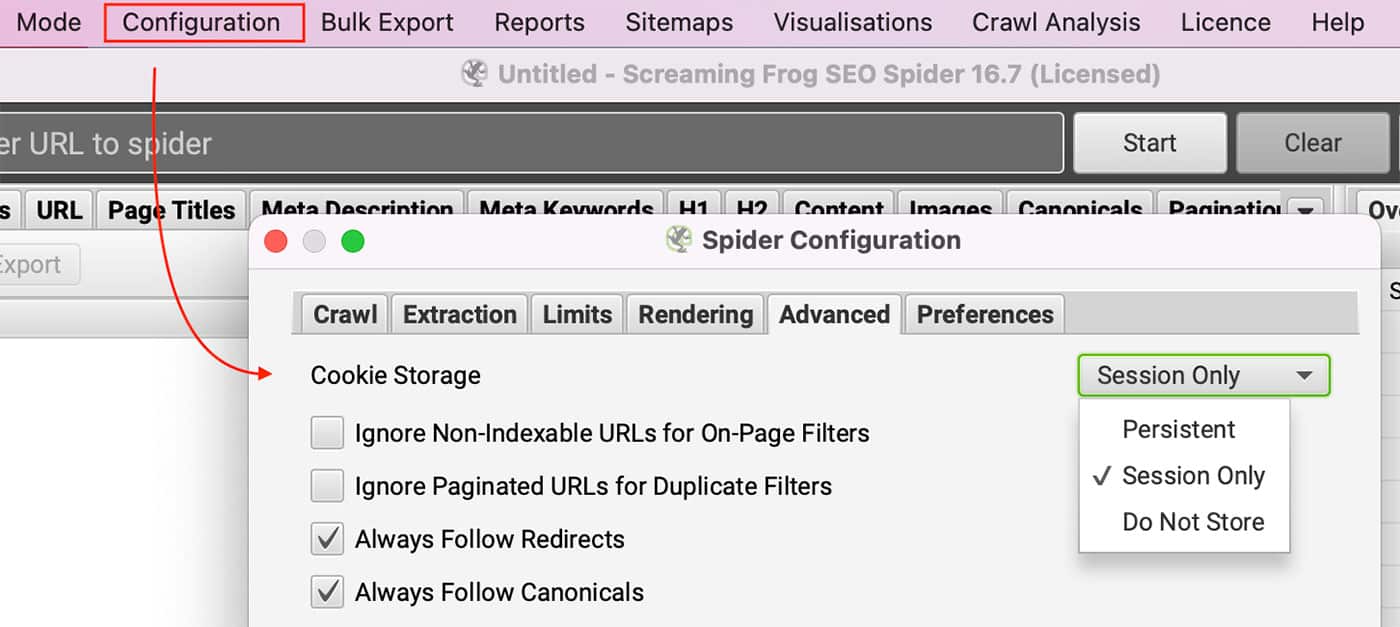
The site requires Cookies.

Can you view the site with cookies disabled in your browser? Licensed users can enable cookies by going to Configuration >> Spider and selecting Session only under Cookie Storage in the Advanced tab.
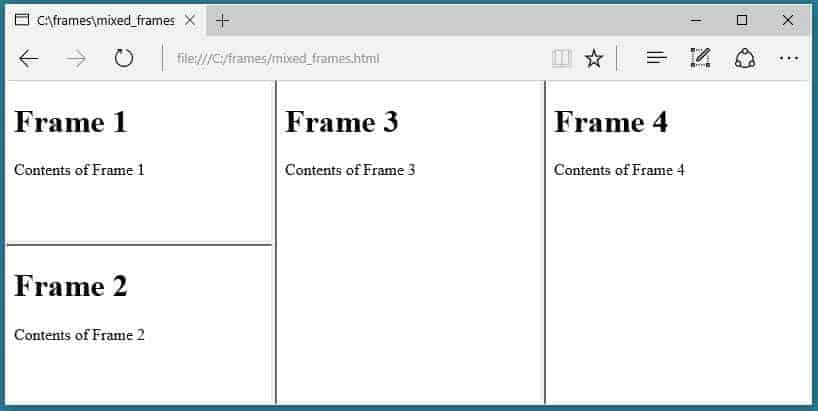
The website uses framesets.

The SEO Spider does not crawl the frame-src attribute.
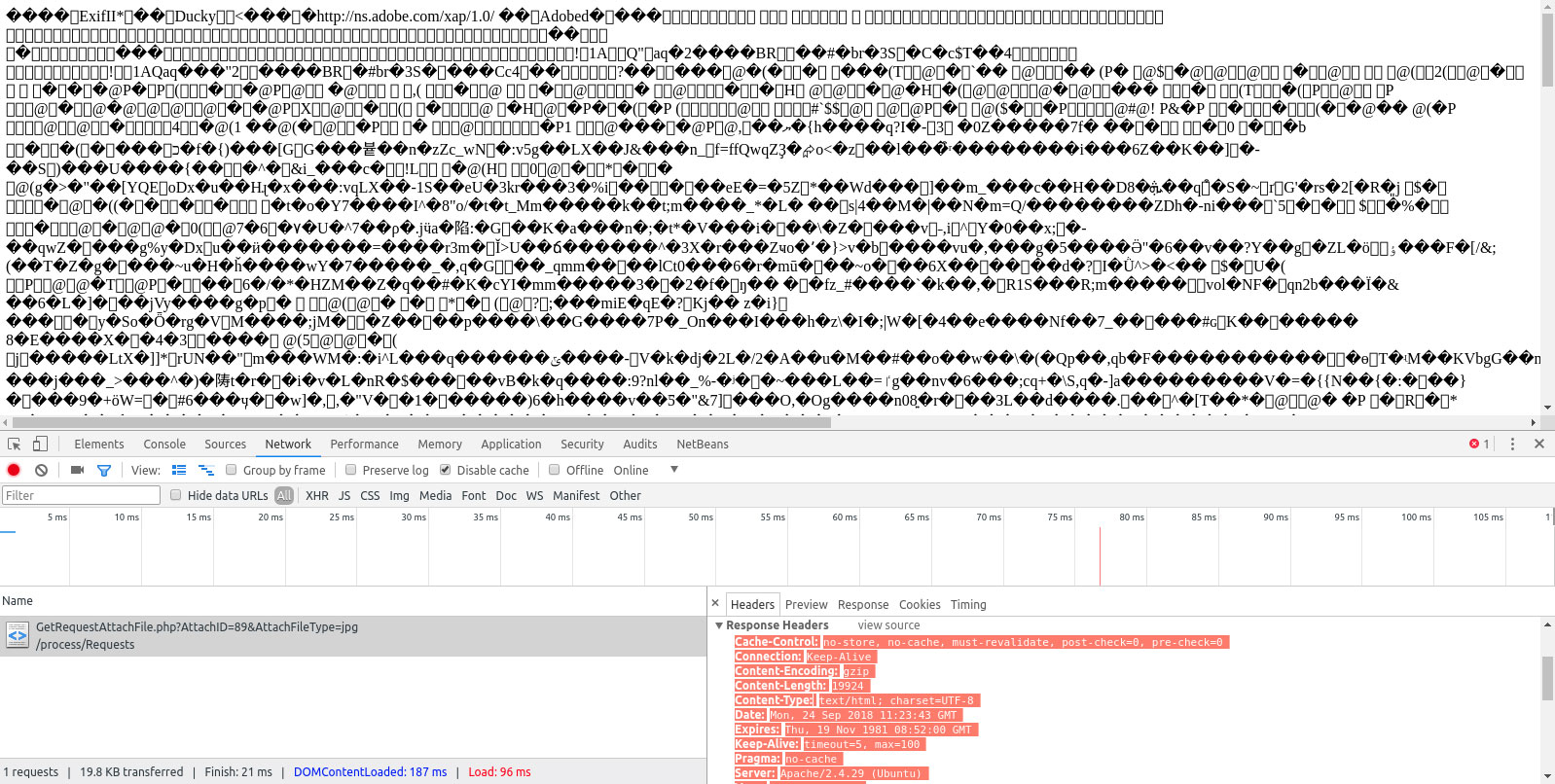
The Content-Type header did not indicate the page is HTML.

This is shown in the Content column and should be either text/HTML or application/xhtml+xml.
Conclusion
The Screaming Frog SEO spider can be an excellent tool for auditing your website, but it’s vital to ensure that all URLs are crawled. If you’re not getting the complete data that you need from your audits, there may be an issue with how Screaming Frog is configured. This blog post looked at why Screaming Frog might not be crawling all your URLs and how to fix the problem. By fixing these issues, you’ll be able to get more comprehensive data from your Screaming Frog audits and improve your SEO strategy. Have you tried using Screaming Frog for your website audits? What tips do you have for improving its functionality?
FAQ
Why is Screaming Frog not crawling all URLs?
Published on: 2022-06-07
Updated on: 2024-09-16