Tabela de Conteúdos
- Guia para iniciantes em SEO
- Como funcionam os motores de busca
- Como um Search Engine Index e Rank Content?
- Diferentes motores de busca produzem melhores resultados
- Os motores de busca podem descobrir seu site?
- Mostre aos motores de busca o caminho certo para rastrear seu site
- Será que os rastreadores encontrarão seu conteúdo mais importante?
- Erros de navegação a evitar
- Verifique sua arquitetura de informação
- Revise seu Sitemaps
- Seu site tem erros de rastreamento?
- Como seu site é indexado
- Como são as minhas páginas para os motores de busca?
- Mostrar os motores de busca Como indexar corretamente seu site
- Saiba mais sobre os diferentes robôs Meta Tags
- Como os motores de busca classificam as páginas em seu site?
- E as Métricas de Engajamento?
- Busca localizada
- Perguntas frequentes
- Este artigo respondeu às suas perguntas?
Guia para iniciantes em SEO

Os motores de busca são projetados para encontrar respostas para os usuários da Internet. Eles organizam a internet para que você possa descobrir instantaneamente resultados de busca relevantes. Para que seu site apareça nos resultados, você tem que ser classificado no motor de busca. É por isso que a otimização para mecanismos de busca (SEO) é tão importante. Você precisa de técnicas de SEO de primeira linha se quiser estar nas páginas de resultados para mecanismos de busca (SERPs).
Como funcionam os motores de busca
A motor de busca é feita para rastejar, indexar e classificar a internet. O rastreamento envolve a busca de conteúdo na web. O processo de indexação envolve a organização do conteúdo da Internet. Após a indexação de uma página, ela aparecerá como a resposta às consultas de pesquisa. Em seguida, o processo de classificação envolve determinar quais são os melhores resultados para consultas específicas.
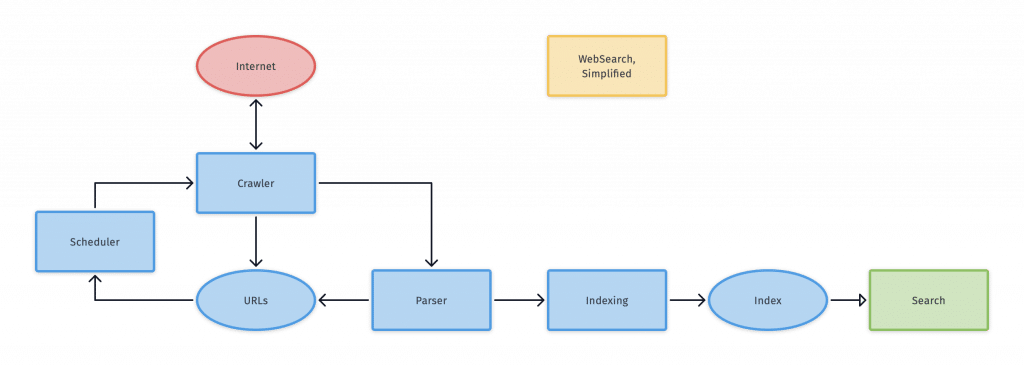
Um mecanismo de busca rastreia um site e envia robôs de busca. Estes robôs também são conhecidos como aranhas. Eles rastejam cada página de conteúdo seguindo links de certas páginas para novas URLs. Quando os spiders encontram novo conteúdo, eles o entregam a um índice chamado Cafeína. Este índice é um banco de dados de URLs que pode ser recuperado pelos mecanismos de busca sempre que alguém procura por algo.
Como um Search Engine Index e Rank Content?
O índice de um mecanismo de busca armazena todo o conteúdo que um mecanismo de busca encontra e armazena. Quando alguém digita uma consulta de busca, o mecanismo pesquisa através do índice para encontrar o conteúdo relevante. O mecanismo de busca classifica esses resultados de acordo com o quão relevantes eles são. Um site com uma alta classificação significa que o mecanismo de busca pensa que é mais relevante do que outros resultados.
Você pode bloquear os rastreadores da web de passar por suas páginas web se quiser. Você também pode dizer aos mecanismos de busca para pararem de armazenar suas páginas em seu índice. A menos que você tenha uma razão para fazer isso, você deve evitá-lo. Se os mecanismos de busca não puderem rastrear e armazenar suas páginas, suas páginas são essencialmente invisíveis para os mecanismos de busca.
Diferentes motores de busca produzem melhores resultados
Embora possam ter a mesma aparência, os vários mecanismos de busca diferem. O Google possui a maior parcela do mercado, mas existem mais de 30 grandes motores de busca. A maioria dos escritores de conteúdo e designers de sites se concentra principalmente no Google, porque 90% das buscas acontecem neste site. É 20 vezes maior do que o Yahoo e o Bing juntos.
Os motores de busca podem descobrir seu site?
Se você quiser que seu site apareça nas SERPs, os spiders devem ser capazes de rastrear suas páginas. Você pode ver se seu o site pode ser rastreado observando quantas páginas do site estão incluídas no índice. Para fazer isso, você pode digitar "site:yourdomain.com" na barra de pesquisa do Google. Os resultados são todas as páginas que o Google indexou de seu site.
Embora o número de páginas não seja exato, é um bom ponto de referência. Você pode tentar usar o relatório de cobertura de índice do Google Search Console se quiser resultados extremamente precisos. Esta ferramenta permite submeter um mapa do site e determinar rapidamente quantas páginas estão incluídas no índice do Google.
Há algumas razões comuns para que você não apareça nos motores de busca.
- Seu site é inteiramente novo e ainda não foi rastejado.
- A navegação do site torna difícil para um robô rastrear o seu site.
- Seu site ainda não está vinculado a sites externos.
- Os motores de busca estão penalizando você por táticas semelhantes às de spam.
- Seu site tem diretrizes de rastejadores que param motores de busca de rastejá-lo e indexá-lo.
Mostre aos motores de busca o caminho certo para rastrear seu site
Se suas páginas não estiverem sendo indexadas corretamente, há algumas medidas que você pode tomar. Você pode dizer ao Googlebot como você quer que o conteúdo seja rastreado. Enquanto você quer que o Googlebot rastreie a maioria de suas páginas, pode haver URLs duplicadas, páginas de encenação e conteúdo fino que você não quer que o Googlebot rastreie.
Robots.txt
Estes arquivos são colocados no diretório raiz do site como uma sugestão para os mecanismos de busca. Eles informam aos mecanismos de busca quais páginas devem ser rastreadas e a rapidez com que devem fazer isso. Quando o Googlebot não vê um arquivo robots.txt, ele rasteja o site inteiro como se fosse normal. Se ele descobre um arquivo robots.txt, ele geralmente escuta as sugestões do arquivo. Quando há um erro no arquivo robots.txt, ele não rastejará o site de forma alguma.
Ponha seu orçamento de rastreamento para trabalhar
Seu site tem um orçamento de rastreamento que determina quantas URLs o Googlebot geralmente irá analisar antes de sair. Se você otimizar seu orçamento de rastreamento, você pode fazer com que o Googlebot rastreie suas páginas mais essenciais ao invés de suas páginas sem importância. Seu orçamento de rastreamento se torna incrivelmente importante quando um site tem milhares ou milhões de URLs.
Quando você otimizar seu orçamento de rastejamento, preste atenção ao noindex e às tags canônicas. Você não quer bloquear os rastejadores da web de páginas com outras diretrizes. Se você bloquear o Googlebot, ele não poderá ver as tags canônicas ou noindex.
Alguns robôs não prestam atenção aos robôs.txt. Os golpistas e maus atores podem até usar o robots.txt como guia para encontrar onde você colocou seu conteúdo privado. Enquanto bloquear os rastreadores das páginas de login e conteúdo privado parece intuitivo, você deve ser cauteloso ao fazer isso. Você torna pública a localização deles colocando estas URLs em um arquivo robots.txt. Ao invés disso, você deve usar noindex nestas páginas e adicionar um formulário de login.
Definindo seus parâmetros de URL
Sites como os de comércio eletrônico permitem que o mesmo conteúdo apareça em várias URLs, anexando certos parâmetros. Por exemplo, você pode refinar sua busca por casacos na Amazon selecionando o tamanho, estilo, marca e cor do casaco. A URL muda um pouco cada vez que você refina sua busca.
Embora o mecanismo de busca do Google seja bastante bom em determinar qual URL é a melhor URL representativa sem ajuda, você pode ajudar os mecanismos de busca usando o recurso Parâmetros de URL do Console de Busca do Google. Este recurso permite que você diga ao Googlebot para parar de rastrear URLs com parâmetros específicos. Em essência, você esconde páginas com conteúdo duplicado dos mecanismos de busca.
Será que os rastreadores encontrarão seu conteúdo mais importante?
Manter os rastreadores longe de certas páginas é útil, mas você também quer que o Googlebot encontre suas páginas essenciais imediatamente. Você pode atingir este objetivo assegurando que o Googlebot possa rastejar facilmente através de seu site. Alguns sites são como rastejadores de parede que podem alcançar, mas não podem passar da página inicial. Se seu conteúdo estiver escondido atrás de formulários de login, um rastreador não poderá acessá-lo.
Qual é a melhor maneira de fornecer um mecanismo de busca com instruções de rastejamento?
Criando um mapa do site é a melhor maneira de fornecer aos motores de busca instruções de rastejamentoartigos recentemente atualizados e novas páginas são as páginas web que você quer que sejam rastreadas primeiro em seu site. Sitemaps contêm uma lista de URLs com a última data modificada, fornecendo aos mecanismos de busca uma lista de páginas a serem rastreadas.

Da mesma forma, os robôs são incapazes de usar formulários de busca. Eles também não podem ler conteúdos não textuais como imagens. Se os mecanismos de busca quiserem entender as imagens de seu site, você precisa adicionar texto dentro da marcação HTML de sua página web.
Além disso, os motores de busca devem ser capazes de seguir um caminho de links de uma página para a próxima. Se uma página não estiver vinculada a nenhuma outra página, ela é invisível para os mecanismos de busca. Você precisa estruturar sua navegação para que os rastreadores possam navegar facilmente.
- Você deve evitar ter navegação móvel e de mesa que mostrem resultados diferentes.
- Sua navegação deve ter itens de menu no HTML. Por exemplo, a navegação habilitada para JavaScript ainda pode ser difícil para um mecanismo de busca rastejar e entender.
- A personalização da navegação para certos tipos de usuários pode se parecer camuflagem para o Googlebot.
- Se você não tiver um link para páginas primárias em seu site, os rastejadores não poderão encontrá-las. Os links são a principal maneira que os rastejadores chegam às novas páginas.
Verifique sua arquitetura de informação
Seu site utiliza uma arquitetura de informação limpa? Sua arquitetura de informação é como o conteúdo de seu site é organizado e rotulado. A arquitetura de informação limpa é intuitiva para os usuários, para que eles possam encontrar com eficiência tudo o que quiserem.
Revise seu Sitemaps
Um mapa do site é como um mapa para os URLs que você tem em seu site. Ele mostra ao Google quais páginas são a mais alta prioridade e quais não são importantes. Embora você ainda precise de excelente navegação no site, um mapa do site ajuda os rastreadores a determinar quais páginas são as mais importantes. Você deve certificar-se de listar apenas as URLs que você deseja indexar. Se você ainda não tiver links de outros sites, o Google Search Console permite que você envie um mapa do site XML para que seu site seja indexado.
Seu site tem erros de rastreamento?
O ideal seria que os rastejadores pudessem ver seu site sem nenhum problema. Você pode visitar o Console de Busca do Google se quiser um relatório de Erros de Rastejamento. Este relatório lhe dirá quais URLs têm problemas. Seus arquivos de log do servidor também têm esta informação, mas os iniciantes podem achar difícil acessar este log.
4xx Códigos
Esses tipos de erros ocorrem devido a erros do cliente. Isso significa que o URL solicitado não pode ser preenchido. Ele também pode conter alguma sintaxe incorreta. A Erro 404 é o tipo de erro mais comum. Isso acontece porque houve um redirecionamento interrompido, uma página excluída ou um erro de digitação no URL.
5xx Códigos
Estes códigos são erros de servidor. Eles acontecem se o servidor não atender o pedido do pesquisador. Estes geralmente acontecem porque a URL foi temporizada, o que significa que o bot deixa de tentar acessar a página.
Faça uma página personalizada 404
Você pode melhorar sua taxa de ressalto com uma página 404 personalizada. Para fazer isso, você tem que adicionar links para outras páginas importantes em seu site ou um recurso de busca. Outra opção é usar um redirecionamento 301 para enviar usuários de uma URL antiga para uma nova.

Criar um 301 Redirecionamento
Você pode usar um 301 para aumentar a equidade do link, transferindo pessoas de sua página antiga para a nova página. Ele também ajuda o Google a descobrir e indexar sua nova página. Embora 404 erros não prejudiquem seu desempenho geral, você pode perder sua classificação nessas páginas específicas.
Por causa disso, você pode querer usar um código de status 301. Ele mostra que a página foi permanentemente mudada para um novo local. Enquanto isso, uma página de redirecionamento 302 representa uma mudança temporária.
Você precisa evitar a criação de uma cadeia de redirecionamento. O Googlebot tem problemas ao passar por vários códigos de status 301 para chegar a uma página. Por causa disso, você deve limitar-se a ter apenas uma página de redirecionamento, tanto quanto possível.
Como seu site é indexado
Seu primeiro objetivo é garantir que o Google possa rastrear seus sites. O próximo passo é conseguir que ele seja indexado. A indexação é a forma como os mecanismos de busca armazenam suas páginas. Em essência, um mecanismo de busca armazena uma renderização de sua página, como uma biblioteca armazena um livro.
Como são as minhas páginas para os motores de busca?
Você pode ver facilmente a última versão em cache de cada página de seu site. Quando você verificar as SERPs, clique na seta suspensa ao lado da URL da página. Em seguida, selecione a opção para o cache. Sites populares e estabelecidos tendem a ser rastreados e colocados em cache com mais freqüência. Você também pode verificar uma versão somente de texto de cada página em cache.
Há muitas razões pelas quais um índice pode remover uma página. As seguintes são algumas das razões mais comuns.
- A URL foi penalizada por uma violação das diretrizes do mecanismo de busca.
- O URL bloqueou os rastreadores por causa de uma exigência de senha.
- A URL retorna com um erro 4xx ou 5xx.
- O URL tem uma diretiva noindex.
Você pode experimentar a ferramenta de inspeção URL se achar que há um problema. Você também pode ir buscar a página como Google. Então, você pode ver se a página está sendo renderizada apropriadamente pelo Google.
Mostrar os motores de busca Como indexar corretamente seu site
As meta diretrizes também são conhecidas como meta tags. Estas meta tags são instruções que dizem aos motores de busca como olhar para suas páginas. Você pode criar meta tags que impedem que os mecanismos de busca possam indexar uma página. Estas instruções são geralmente colocadas no cabeçalho de suas páginas HTM ou sua X-Robots-Tag em seu cabeçalho HTTP.
Saiba mais sobre os diferentes robôs Meta Tags
Índice/noindex: Isto diz aos motores de busca se devem ou não rastrear a página.
Seguir/nofolhar: Isto mostra se os bots devem ou não seguir os links que você tem em sua página.
Noarchive: Isto diz aos mecanismos de busca que eles não devem manter uma cópia em cache de uma página específica.
Com as meta diretrizes, você pode afetar a forma como suas páginas são indexadas. Elas não afetam a forma como as páginas são indexadas. Para seguir a diretriz, o rastejador deve rastejar a página para vê-las.
X-robots-tag: Esta etiqueta pode ser colocada no cabeçalho HTTP do seu URL para bloquear os mecanismos de busca.
Como os motores de busca classificam as páginas em seu site?
Sua classificação se refere à altura de sua página na lista de resultados do mecanismo de busca. A maioria das pessoas clica nos três primeiros resultados, portanto, seu ranking determina o número de visitantes do site que você recebe. Os mecanismos de busca usam fórmulas e algoritmos para determinar como a informação é armazenada. Esses algoritmos dos mecanismos de busca mudam constantemente à medida que o Google trabalha para melhorar a qualidade da busca.
Os motores de busca querem dar aos pesquisadores as melhores respostas para suas perguntas. Com o tempo, os motores de busca têm se tornado melhores na compreensão da semântica. Enquanto práticas como o recheio de palavras-chave são usadas para enganar os motores de busca, os motores de busca agora são capazes de dizer quando uma página é artificialmente recheada com uma palavra-chave.
Links e SEO
Os links são essenciais para SEO. Os motores de busca olham para seus links internos e links de entrada. Os links de entrada são os links que você obtém de outros sites que levam ao seu site. De certa forma, eles são como uma versão on-line de referências boca-a-boca. Embora os mecanismos de busca não confiem tanto nesses links como antigamente, eles ainda desempenham um papel na determinação de sua classificação nos mecanismos de busca. Algoritmo PageRank do Google analisa a quantidade e a qualidade de cada link que vai para suas páginas.
Conteúdo e SEO
O conteúdo também desempenha um papel na determinação das classificações de seu mecanismo de busca. Os rastreadores escaneam seu conteúdo para decidir do que se trata sua página. Então, ele encontra o conteúdo mais relevante possível para cada consulta de busca. Como o objetivo principal é alcançar a satisfação do usuário, não há nenhuma regra definida sobre quanto tempo você deve fazer seu conteúdo.
RankBrain e SEO
Conteúdo, links e RankBrain são os principais fatores que determinam como o Google classifica seu site. O RankBrain envolve aprendizado de máquina. Ele pode usar observações para aprender sozinho ao longo do tempo. Como ele está constantemente melhorando, os resultados da pesquisa também melhoram. Se um URL for mais relevante para o usuário da pesquisa, ele obterá uma classificação melhor. Isso significa que a melhor coisa que você pode fazer é melhorar a experiência do usuário e garantir que seu conteúdo seja relevante.
E as Métricas de Engajamento?
As métricas de engajamento são freqüentemente mais altas para locais com uma classificação mais alta, mas há muito debate sobre se isso se deve à causalidade ou correlação. As métricas de engajamento incluem cliques em sua listagem nos resultados de busca, sua taxa de retorno e o tempo gasto em suas páginas. A taxa de retorno é a porcentagem das sessões em que o telespectador verifica apenas uma página antes de sair.
O Google disse que eles usam dados de clique para ajustar seus SERPs. Se a maioria das pessoas clicar no segundo resultado em vez do primeiro, o Google eventualmente mudará a ordem dos resultados. Isto significa que as métricas de engajamento servem como verificadores de fatos para motores de busca. Os rastejadores podem adivinhar se uma página é relevante. Então, visitantes reais mostram ao Google quais páginas são relevantes, clicando nelas. Se uma página tem uma alta taxa de salto, ela provavelmente não é relevante para o pesquisador.
Busca localizada
O Google tem experimentou uma variedade de pesquisas formatos ao longo do tempo. O objetivo é melhorar a experiência do usuário, oferecendo a ele o melhor tipo de conteúdo. Com a pesquisa localizada, o Google se preocupa com a relevância, a distância e o destaque. Para garantir uma boa classificação, você deve otimizar sua listagem do Google Meu Negócio.
Relevância significa que sua empresa precisa corresponder ao que o pesquisador deseja. Enquanto isso, a distância envolve sua localização geográfica. Embora as pesquisas orgânicas raramente divulguem esse fato, elas geralmente são influenciadas pela localização do pesquisador. Por fim, o Google quer recompensar as empresas de destaque que são populares no mundo real. Eles podem saber se você tem uma empresa conhecida observando seu Avaliações do Google e citações em outros sites. Além disso, o Google considerará suas outras técnicas de SEO para determinar a posição do seu site em uma pesquisa localizada.
Perguntas frequentes
Como funcionam os mecanismos de busca?
O que é rastejamento e indexação?
Qual é a maneira mais comum de um mecanismo de busca descobrir uma página web?
Qual é o objetivo principal de um mecanismo de busca?
O que pode ajudar um mecanismo de busca a entender a diferença entre os tópicos?
O que pode ajudar um mecanismo de busca a entender a diferença?
Como os mecanismos de busca rastejam os sites?
Como os motores de busca lidarão com uma má estrutura do site?
Qual é a posição média no Console de Busca do Google?
Como é um mapa do site?
O que está rastejando em SEO?
Qual foi o primeiro mecanismo de busca criado?
A seguir: Pesquisa por palavra-chave
Anterior: SEO 101
Publicado em: 2020-09-10
Atualizado em: 2024-04-22