目次
- SEO初級ガイド
- 検索エンジンの仕組み
- 検索エンジンはどのようにコンテンツをインデックスし、ランク付けしているのか?
- 検索エンジンの違いによる成果の違い
- 検索エンジンはあなたのサイトを発見してくれるのか?
- 検索エンジンに正しい方法でクロールさせるために
- クローラーは、あなたの最も重要なコンテンツを見つけることができますか?
- ナビゲーションの間違い
- 情報アーキテクチャの確認
- サイトマップを見直す
- あなたのサイトにはクロールエラーはありませんか?
- サイトがインデックスされる仕組み
- 検索エンジンは私のページをどう見ているのか?
- 検索エンジンに適切なインデックスを表示する方法
- ロボットのメタタグの違いについて学ぶ
- 検索エンジンはどのようにあなたのサイトのページをランク付けしているのか?
- エンゲージメント指標は?
- ローカライズ検索
- よくあるご質問
- この記事はあなたの疑問を解決してくれましたか?
SEO初級ガイド

検索エンジンは、インターネットユーザーのために答えを見つけるために設計されています。関連する検索結果を即座に発見できるように、インターネットを整理しているのです。あなたのサイトが検索結果に表示されるためには、検索結果の上位に表示される必要があります。 検索エンジン.そのため、検索エンジン最適化(SEO)が非常に重要です。検索エンジンの結果ページ(SERPs)に表示されたいのであれば、一流のSEO技術が必要なのです。
検索エンジンの仕組み
A 検索エンジン とする。 クロール、インデックス、ランキング.クローリングは、ウェブのコンテンツを検索することです。インデックス作成は、インターネットのコンテンツを整理する作業です。インデックス作成後、そのページは 検索に応じる.そして、ランキングのプロセスでは、特定のクエリに対してどのコンテンツが最良の結果であるかを決定します。
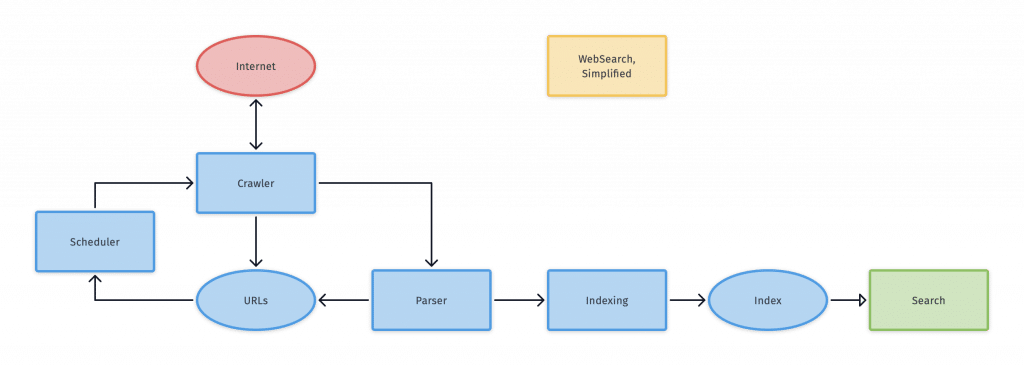
検索エンジンは、サイトをクロールして検索エンジンロボットを送り込みます。これらのロボットは、スパイダーとも呼ばれます。スパイダーは、特定のページから新しいURLへのリンクをたどることで、各コンテンツページをクロールします。スパイダーは新しいコンテンツを見つけると、それをCaffeineと呼ばれるインデックスに渡します。このインデックスは、誰かが何かを検索したときに検索エンジンが取り出すことのできるURLのデータベースである。
検索エンジンはどのようにコンテンツをインデックスし、ランク付けしているのか?
検索エンジンのインデックスには、検索エンジンが見つけて保存しているすべてのコンテンツが格納されています。誰かが検索クエリを入力すると、エンジンはインデックスを検索して、関連するコンテンツを見つけます。検索エンジンは、これらの結果を関連性の高さに応じてランク付けします。ランキングの高いウェブサイトは、検索エンジンが他の結果よりも関連性が高いと考えることを意味します。
ウェブクローラーがあなたのウェブページを通過するのをブロックすることができます。また、検索エンジンのインデックスにあなたのページを保存しないように指示することもできます。どうしてもそうしなければならない理由がない限り、避けた方がよいでしょう。検索エンジンがあなたのページをクロールして保存できない場合、あなたのページは基本的に検索エンジンから見えなくなります。
検索エンジンの違いによる成果の違い
同じように見えても、検索エンジンはさまざまです。Googleは市場で最も大きな部分を占めていますが、30以上の大きな検索エンジンが存在します。ほとんどのコンテンツライターやウェブサイトデザイナーは、検索の90%がこのサイトで行われるため、主にGoogleに焦点を当てています。YahooとBingを合わせた20倍もの規模があります。
検索エンジンはあなたのサイトを発見してくれるのか?
あなたのサイトをSERPに表示させるには、スパイダーがあなたのページをクロールできなければなりません。あなたの サイトがクローラブルである そのサイトのページがどれだけインデックスに含まれているかを見ることである。これを行うには、Googleの検索バーに「site:yourdomain.com」と入力します。結果は、グーグルがあなたのサイトからインデックスしたすべてのページです。
ページ数は正確ではありませんが、参考にはなります。極めて正確な結果が必要な場合は、Google Search ConsoleのIndex Coverageレポートを使ってみるとよいでしょう。このツールでは、サイトマップを送信して、Googleのインデックスに含まれるページ数を素早く判断することができます。
検索エンジンに表示されない理由には、いくつかの共通点があります。
- あなたのサイトはまったく新しいもので、まだクロールされていません。
- サイトのナビゲーションが、ロボットによるクロールを困難にしている。
- あなたのサイトはまだ外部サイトにリンクされていません。
- 検索エンジンは、スパムのような手法でペナルティを与えているのです。
- あなたのサイトには、クローラーを停止させるディレクティブがあります。 検索エンジン をクロールしてインデックスを作成します。
検索エンジンに正しい方法でクロールさせるために
ページが正しくインデックスされない場合、いくつかの対処法があります。Googlebotにコンテンツをどのようにクロールさせたいかを指示することができます。Googlebotにほとんどのページをクロールさせたい一方で、重複したURLやステージングページ、薄いコンテンツなど、Googlebotにクロールさせたくないページがあるかもしれません。
Robots.txt
これらのファイルは、検索エンジンへの提案として、サイトのルートディレクトリに置かれます。検索エンジンに、どのページをどれくらいの速度でクロールさせるかを指示します。Googlebotは、robots.txtファイルがない場合、通常通りサイト全体をクロールします。robots.txtを発見した場合、通常、ファイル内の提案に耳を傾けます。robots.txtファイルにエラーがある場合は、そのサイトをまったくクロールしません。
クロールの予算を有効活用する
あなたのサイトにはクロールバジェットがあり、Googlebotが一般的に離脱するまでに何個のURLを見るかを決定します。クロールバジェットを最適化すれば、Googlebotに、重要でないページではなく、最も重要なページをクロールさせることができます。クロールバジェットは、何千、何百万ものURLを持つサイトでは、非常に重要になります。
クロールバジェットを最適化する際には、noindexタグとcanonicalタグに注意する。他のディレクティブでウェブクローラーをページからブロックしないようにします。Googlebotをブロックすると、canonicalタグやnoindexタグを見ることができなくなる。
robots.txtに注意を払わないロボットもいます。詐欺師や悪質業者は、robots.txtをガイドとして、あなたがプライベートコンテンツを置いている場所を探すことさえあります。ログイン・ページやプライベート・コンテンツからクローラーをブロックすることは直感的に理解できるように思えますが、この方法には注意が必要です。これらのURLをrobots.txtに記述することで、その場所を公にしてしまうからです。代わりに、これらのページにはnoindexを使用し、ログインフォームを追加する必要があります。
URL パラメータの定義
ECサイトなどのサイトでは、特定のパラメータを付けることで、同じコンテンツをさまざまなURLで表示させることができます。例えば、Amazonでコートを検索する場合、コートのサイズ、スタイル、ブランド、色を選択することで絞り込み検索が可能です。URLは絞り込むたびに少しずつ変化します。
Googleの検索エンジンは、助けを借りずにどのURLが最適な代表URLかを判断することに長けていますが、Google Search ConsoleのURLパラメータ機能を使って、検索エンジンを支援することができます。この機能は、特定のパラメータを持つURLのクロールを停止するようにGooglebotに指示することができます。要するに、重複するコンテンツを含むページを検索エンジンから隠すことができるのです。
クローラーは、あなたの最も重要なコンテンツを見つけることができますか?
クローラーを特定のページに近づけないようにすることは有効ですが、Googlebotに必要なページをすぐに見つけてもらうことも必要です。この目標は、Googlebotが簡単にサイト内をクロールできるようにすることで達成できます。サイトによっては、クローラーが到達できる壁のようなものがありますが、最初のトップページを越えることはできません。コンテンツがログインフォームの後ろに隠されている場合、クローラーはアクセスすることができません。
検索エンジンにクロール指示を出すには、どのような方法があるのでしょうか?
サイトマップの作成 は、検索エンジンにクロールの指示を出すのに最適な方法です。; 最近更新された記事や新しいページは、あなたのWebサイトで最初にクロールされたいWebページです。サイトマップには、最終更新日付のURLのリストが含まれており、検索エンジンにクロールされるべきページのリストを提供する。

同様に、ロボットは検索フォームを使用することができません。また、画像のような非テキストコンテンツも読み取ることができません。検索エンジンがあなたのサイトの画像を理解したい場合は、ウェブページのHTMLマークアップの中にテキストを追加する必要があります。
さらに、検索エンジンは、あるページから次のページへのリンクの経路をたどることができなければなりません。あるページが他のページにリンクされていなければ、そのページは検索エンジンからは見えません。クローラーが簡単に移動できるように、ナビゲーションを構造化する必要があります。
- モバイルとデスクトップで異なる結果を表示するようなナビゲーションは避けるべきです。
- ナビゲーションは、HTMLの中にメニュー項目があることが望ましいです。例えば、JavaScriptを使用したナビゲーションは、検索エンジンがクロールして理解することがまだ困難な場合があります。
- 特定のタイプのユーザー向けにナビゲーションをパーソナライズすると、次のようになります。 匍匐前進 をGooglebotに送信します。
- Webサイトの主要なページにリンクを張らなければ、クローラーはそのページを見つけることができません。リンクは、クローラーが新しいページにたどり着くための主要な手段です。
情報アーキテクチャの確認
あなたのサイトでは、きれいな情報アーキテクチャが使われていますか?情報アーキテクチャとは、ウェブサイトのコンテンツがどのように整理され、ラベル付けされているかを示すものです。クリーンな情報アーキテクチャは、ユーザーにとって直感的で、何でも効率的に見つけることができます。
サイトマップを見直す
サイトマップとは、あなたのサイトにあるURLの地図のようなものです。どのページが最も優先度が高く、どのページが重要でないかをGoogleに示します。優れたサイトナビゲーションは必要ですが、サイトマップはクローラーがどのページが最も重要であるかを判断するのに役立ちます。インデックスさせたいURLだけをリストアップするようにしましょう。まだ他のサイトからのリンクがない場合は、Google Search ConsoleでXMLサイトマップを送信して、サイトをインデックスさせることができます。
あなたのサイトにはクロールエラーはありませんか?
クローラーが問題なくサイトを見ることができるのが理想的です。クロールエラーのレポートが必要な場合は、Google Search Consoleにアクセスすることができます。このレポートでは、どのURLに問題があるのかを知ることができます。サーバーのログファイルにもこの情報は含まれていますが、初心者がこのログにアクセスするのは難しいかもしれません。
4xxコード
この種のエラーは、クライアントのエラーによって発生する。これは、要求されたURLを満たすことができないことを意味します。また、間違った構文が含まれている可能性もあります。A 404エラー は最も一般的なタイプのエラーです。リダイレクトが壊れていたり、ページが削除されていたり、URLにタイプミスがあったりするために起こります。
5xxコード
これらのコードは、サーバーのエラーです。サーバーが検索者のリクエストに応えられない場合に発生します。一般的には、URLのタイムアウト、つまりボットがページにアクセスするのをやめたために起こります。
カスタム404ページを作成する
カスタマイズされた404ページで直帰率を改善することができます。そのためには、サイト内の他の重要なページへのリンクや、検索機能を追加する必要があります。また、301リダイレクトを使用して、ユーザーを古いURLから新しいURLに送るという方法もあります。

301リダイレクトを作成する
301を使用すると、古いページから新しいページに人々を移動させることによって、リンクエクイティを高めることができます。また、Googleがあなたの新しいページを発見し、インデックスするのにも役立ちます。404エラーは全体的なパフォーマンスには影響しませんが、特定のページでのランキングを失う可能性があります。
このため、301ステータスコードを使用するとよいでしょう。これは、ページが恒久的に新しい場所に切り替わったことを表しています。一方、302リダイレクトページは、一時的な移動を表します。
リダイレクトの連鎖を作らないようにする必要があります。Googlebotは、ページに到達するために複数の301ステータスコードを通過することに問題があります。このため、できるだけ1つのリダイレクトページを持つことにこだわる必要があります。
サイトがインデックスされる仕組み
最初の目標は、Googleがあなたのサイトをクロールできるようにすることです。次のステップは、インデックスさせることです。インデックスとは、検索エンジンがあなたのページを保存する方法のことです。要するに、検索エンジンは、図書館が本を保管するように、あなたのページのレンダリングを保管するのです。
検索エンジンは私のページをどう見ているのか?
サイトの各ページの最新キャッシュ版を簡単に確認することができます。SERPsを確認する際、ページのURLのそばにあるドロップダウン矢印をクリックします。そして、キャッシュのオプションを選択します。人気のあるサイトや定評のあるサイトは、より頻繁にクロールされ、キャッシュされる傾向があります。また、キャッシュされた各ページのテキストのみのバージョンもチェックすることができます。
インデックスがページを削除する理由には、さまざまなものがあります。以下は、最も一般的な理由の一部です。
- 検索エンジンのガイドラインに違反するとして、このURLにペナルティが課されました。
- パスワードが必要なため、URLがクローラーをブロックしている。
- URLが4xxまたは5xxのエラーで返される。
- URLにnoindexディレクティブが指定されている。
問題があると思われる場合は、URL Inspection toolを試してみてください。また、Googleとしてページを取得することもできます。そうすれば、そのページがGoogleによって適切にレンダリングされているかどうかを確認することができます。
検索エンジンに適切なインデックスを表示する方法
メタディレクティブは、メタタグとも呼ばれます。これらのタグは、検索エンジンがあなたのページをどのように見るかを指示するものです。検索エンジンがページをインデックスできないようにするmetaタグを作成することができます。これらの指示は、一般に、HTMページの先頭か、HTTPヘッダーのX-Robots-Tagに記述します。
ロボットのメタタグの違いについて学ぶ
Index/noindex。 これは、検索エンジンに、そのページをクロールするかどうかを指示するものです。
フォロー/ノーフロー これは、ボットがあなたのページ上にあるリンクをたどるべきかどうかを示しています。
ノーカーキブ これは、検索エンジンに特定のページのキャッシュコピーを保持しないように指示するものです。
metaディレクティブを使うと、ページのインデックス付けに影響を与えることができます。これらは、ページがクロールされる方法には影響を与えません。ディレクティブに従うには、クローラがページをクロールしてそれらを確認する必要があります。
X-robots-tag。 このタグは、URLのHTTPヘッダーに設置することで、検索エンジンをブロックすることができます。
検索エンジンはどのようにあなたのサイトのページをランク付けしているのか?
ランキングとは、検索エンジンの検索結果リストで、あなたのページがどれだけ上位に表示されているかを示すものです。ほとんどの人が最初の3つの結果をクリックするので、ランキングはサイト訪問者の数を決定します。検索エンジンは、情報の保存方法を決定するために数式とアルゴリズムを使用しています。これらの検索エンジンのアルゴリズムは、Googleが検索の質を向上させるために常に変化しています。
検索エンジンは、検索者の質問に対して最適な答えを提供したいと考えています。時が経つにつれて、検索エンジンはセマンティクスをよりよく理解できるようになりました。キーワードの詰め込みのような行為は検索エンジンを騙すために使われますが、検索エンジンは、ページが人為的にキーワードを詰め込んでいることを見分けることができるようになったのです。
リンクとSEO
リンクはSEOに不可欠です。検索エンジンは、あなたの内部リンクとインバウンドリンクを見ます。インバウンドリンクとは、他のウェブサイトからあなたのサイトへつながるリンクのことです。ある意味、オンライン版の口コミのようなものです。検索エンジンは、以前ほどこれらのリンクを頼りにしていませんが、それでも検索エンジンのランキングを決定する役割を担っています。 GoogleのPageRankアルゴリズム は、あなたのページに張られたすべてのリンクの量と質を分析します。
コンテンツとSEO
コンテンツは、検索エンジンのランキングを決定する際にも重要な役割を果たします。クローラーはあなたのコンテンツをスキャンして、あなたのページが何について書かれているかを判断します。そして、それぞれの検索クエリに対して、可能な限り関連性の高いコンテンツを見つけます。ユーザーの満足を得ることが主な目的なので、コンテンツをどれくらいの長さにすべきか、決まったルールはありません。
RankBrainとSEO
コンテンツ、リンク ランクブレイン は、Googleがあなたのサイトをどのようにランク付けするかを決定する主な要因である。RankBrainには機械学習が含まれている。RankBrainは観察結果をもとに、時間をかけて学習していく。常に改善されるため、検索結果も改善される。あるURLが検索ユーザーにとってより関連性が高ければ、そのURLはより良いランキングを得ることになる。つまり、あなたができる最善のことは、ユーザーエクスペリエンスを向上させ、コンテンツに関連性を持たせることなのです。
エンゲージメント指標は?
エンゲージメント指標は、ランキングが高いサイトほど高くなることが多いですが、これが因果関係によるものか相関関係によるものかについては、さまざまな議論があります。エンゲージメント指標には、検索結果でのリスティングのクリック数、直帰率、ページでの滞在時間などがあります。直帰率とは、閲覧者が1ページしかチェックせずに離脱したセッションの割合のことです。
Googleは、クリックデータを使ってSERPを調整すると言っています。もし、多くの人が1番目の結果ではなく2番目の結果をクリックすれば、Googleは最終的に結果の順番を入れ替えるでしょう。つまり、エンゲージメントメトリクスは、以下のようなファクトチェッカーとして機能しているのです。 検索エンジン.クローラーは、あるページが関連性があるかどうかを推測することができます。そして、実際の訪問者は、どのページが関連性があるのかをクリックすることでGoogleに示します。バウンス率が高いページは、おそらく検索者にとって関連性のないページです。
ローカライズ検索
グーグルは は、様々な検索で実験しました。 のフォーマットを時間経過とともに変更します。これは、ユーザーに最適なタイプのコンテンツを提供することで、ユーザー体験を向上させることを目的としています。ローカライズ検索では、Googleは関連性、距離、目立ちやすさを気にします。上位に表示されるように、Googleマイビジネス・リストを最適化する必要があります。
関連性とは、あなたのビジネスが検索者の求めるものと一致する必要があることを意味する。一方、距離には地理的位置が含まれます。オーガニック検索がこの事実を放送することはほとんどありませんが、一般的に検索者の位置情報に影響されます。最後に、Googleは現実世界で人気のある著名なビジネスに報いたいと考えている。Googleは、あなたが有名なビジネスをしているかどうかを、あなたの グーグル・レビュー や他のサイトでの引用を考慮します。さらにGoogleは、ローカライズされた検索におけるあなたのウェブサイトの位置を決定するために、あなたの他のSEO技術を考慮します。
よくあるご質問
検索エンジンの仕組みは?
クローリングとインデックス作成とは何ですか?
検索エンジンがウェブページを発見する最も一般的な方法は何でしょうか?
検索エンジンの主な目的は何ですか?
検索エンジンがトピックの違いを理解するのに役立ちそうなことは何でしょうか?
検索エンジンがその違いを理解するのに役立ちそうなことは何でしょうか?
検索エンジンはどのようにウェブサイトを巡回しているのですか?
検索エンジンは、貧弱なサイト構造にどう対処するのか?
Google Search Consoleでの平均的な位置づけは?
サイトマップとはどのようなものですか?
SEOにおけるクローリングとは?
最初に作られた検索エンジンは何ですか?
公開日: 2020-09-10
更新日: 2024-04-22