TL;DR - En NLP, le stemming réduit les mots à leur forme racine en supprimant les affixes, tandis que la lemmatisation réduit les mots à leur forme de base dans le dictionnaire, en tenant compte de leur contexte et de leur sens.
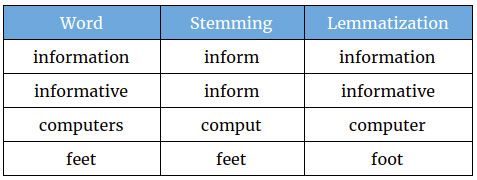
Table des matières
La segmentation et la lemmatisation dans le traitement des langues naturelles
Dans le domaine du traitement du langage naturel (NLP) et de l'analyse de texte, la normalisation du texte joue un rôle essentiel. Deux des techniques de normalisation les plus populaires utilisées dans les domaines de la science des données et de l'intelligence artificielle sont le stemming et la lemmatisation. Elles constituent des étapes de prétraitement essentielles pour diverses tâches telles que l'analyse des sentiments, la recherche d'informations, etc. Cet article se penche sur les subtilités de ces deux techniques, leurs algorithmes et leur importance dans le paysage actuel de l'apprentissage automatique.
La tige :
Définition et objectif : Le stemming est le processus de réduction d'un mot infléchi ou dérivé à sa forme de base ou racine. L'objectif premier est d'associer des mots apparentés à la même représentation afin de faciliter des tâches telles que recherche et l'analyse.
Exemple : Buy >> Acheter, Acheter, Acheté, Achète
Algorithme et outils : L'algorithme de troncature le plus populaire, en particulier pour la langue anglaise, est le troncatureur de Porter. Développé par Martin Porter, il supprime les suffixes (et dans certains cas les préfixes) des mots. Parmi les autres stemmers notables, on peut citer le stemmer Snowball, une approche plus agressive qui prend en charge plusieurs langues.
Utilisation en Python avec NLTK : Le Natural Language Toolkit (NLTK) de Python prend en charge le stemming grâce à la fonction nltk.stem module. Par exemple :
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem("running")))Il en résulterait "run", la forme racine du mot.
Inconvénients : L'éraflage peut parfois être imprécis. Sur-tirage se produit lorsque trop de mots sont coupés, ce qui risque d'en modifier le sens, tandis que l'on parle de sous-ensemble lorsque deux mots apparentés sont coupés pour obtenir des formes différentes.
Lemmatisation :
Définition et objectif : La lemmatisation est un processus plus sophistiqué que le stemming. Elle consiste à réduire un mot à sa forme de base ou forme dictionnaire, appelée lemme. Contrairement au stemming, la lemmatisation prend en compte le sens du mot, sa partie du discours et l'analyse morphologique pour parvenir à cette réduction.
Exemple : Acheter, Acheter, Acheter >> Acheter
Algorithme et outils : Le WordNetLemmatizer, disponible dans NLTK, est un outil couramment utilisé pour la lemmatisation de la langue anglaise. Il utilise la base de données WordNet pour rechercher des lemmes. D'autres outils, comme SpaCy, offrent également des capacités de lemmatisation, souvent utilisées dans des pipelines NLP plus avancés.
Utilisation en Python avec NLTK : Utilisation de l'outil WordNetLemmatizer de l'application nltk.stem module :
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("courir", pos="v"))Le résultat serait "run", la forme de base du mot "running" lorsqu'il est considéré comme un verbe.
Comparaison et cas d'utilisation :
- Précision : La lemmatisation, qui est un processus plus complexe, est généralement plus précise que le stemming, car elle prend en compte le sens du mot, en utilisant l'analyse morphologique et l'analyse de la langue. marquage des parties du discours.
- Vitesse : Le stemming est généralement plus rapide, car il s'agit d'une approche basée sur des règles qui supprime les affixes, ce qui le rend plus adapté à des applications telles que le moteurs de recherche où la rapidité est cruciale.
- Applications : Ces deux techniques sont répandues dans diverses PNL Le choix de l'une ou l'autre de ces méthodes dépend de l'ensemble de données, de la précision souhaitée et des contraintes de calcul. Le choix de l'un ou l'autre dépend de l'ensemble de données, de la précision souhaitée et des contraintes de calcul.
Défis :
Bien que le stemming et la lemmatisation soient d'une valeur inestimable pour la normalisation des textes, ils ne sont pas sans poser de problèmes. La précision de ces techniques varie d'une langue à l'autre, l'anglais disposant d'algorithmes relativement matures. Les formes flexionnelles, les nuances dans les parties du discours et l'ambiguïté inhérente au langage naturel rendent la tâche non triviale.
Conclusion :
Le stemming et la lemmatisation sont des techniques fondamentales dans le domaine de l'éducation. PNL. Au fur et à mesure que la technologie progresse et que des outils comme ChatGPT et d'autres deviennent plus sophistiqués, l'importance d'une compréhension et d'un traitement précis de l'information sur l'environnement devient de plus en plus évidente. sémantique L'essence des mots ne fera que croître. Que vous souhaitiez vous plonger dans l'analyse des sentiments ou développer la prochaine génération de chatbots, une bonne maîtrise de ces techniques de normalisation est indispensable.
FAQ
Qu'est-ce que le stemming et la lemmatisation ?
Quand utiliser le tronc commun et la lemmatisation ?
Publié le : 2022-03-28
Mise à jour le : 2024-07-30