TL;DR - NLPでは、ステミングは接辞を除去して単語を語根の形に切り詰める。一方、レマタイゼーションは、文脈と意味を考慮して、単語を辞書の基本形に切り詰める。
自然言語処理におけるステミングとレンマタイゼーション
自然言語処理(NLP)とテキスト分析の領域では、テキストの正規化が極めて重要な役割を果たす。データサイエンスや人工知能の領域で使用される最も一般的な正規化テクニックの2つは、ステミングとレマタイゼーションです。これらは、センチメント分析、情報検索など、さまざまなタスクに不可欠な前処理ステップとして機能します。この記事では、この2つのテクニックの複雑さ、アルゴリズム、そして今日の機械学習における意義について掘り下げます。
ステミング:
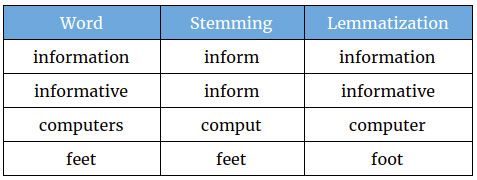
定義と目的: ステミングとは、屈折した単語や派生した単語を、その基本形または語根形に還元するプロセスのことである。主な目的は、関連する単語を同じ表現にマップして、次のようなタスクを支援することです。 探索 と分析する。
例 買う >> 買う、買われる、買われる
アルゴリズムとツール: 最も一般的なステミングアルゴリズム (特に英語) は、Porter stemmer です。マーティン・ポーターによって開発されたこのステム機能は、単語の接尾辞 (場合によっては接 頭辞) を切り捨てます。その他の注目すべきステム機能には、複数の言語をサポートする、より積極的なアプローチの Snowball ステム機能があります。
NLTKとPythonで使用する: Python の Natural Language Toolkit (NLTK) には、ステミングのサポートがあります。 nltk.stem モジュールを使用します。例えば
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem("running"))この場合、語源である「run」が出力される。
欠点もある: ステミングは時として不正確な場合がある。過剰ステミング 発生 ステミング不足とは、関連する 2 つの単語が異なる形にステミングされることです。
レマティゼーション:
定義と目的: レンマ化は、ステミングよりも高度な処理です。レンマ化では、単語を基本形または辞書形 (レンマと呼ばれる) に変換します。ステミングとは異なり、レンマタイゼーションでは、単語の意味、品詞、形態素解析を考慮して、この削減を行います。
例 買う、買われる、買う >> 買う
アルゴリズムとツール: NLTKで利用可能なWordNetLemmatizerは、英語のlemmatizationに使用される一般的なツールである。WordNetデータベースを使用してレマを検索します。SpaCyのような他のツールもlemmatization機能を提供しており、より高度なNLPパイプラインでよく使用される。
NLTKとPythonで使用する: のWordNetLemmatizerを使用する。 nltk.stem モジュールである:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("running", pos="v"))これは、動詞として考えた場合、「running」という単語の基本形である「run」を返すことになる。
比較と使用例:
- 正確さ: レムマタイゼーションは、より複雑なプロセスですが、形態素解析を使用して単語の意味を考慮するため、 一般的にステミングよりも正確です。 品詞タグ付け.
- スピードだ: ステミングは一般的に高速で、接辞をカットするルールベースのアプローチであるため、以下のような用途に適している。 検索エンジン スピードが重要なところ。
- アプリケーション どちらのテクニックも、さまざまな分野で普及している。 自然言語処理 チャットボット、センチメント分析、機械学習モデル用のテキスト前処理などのタスクを含む。これらの選択は、データセット、希望する精度、計算上の制約に依存する。
課題だ:
ステミングとレムマタイゼーションは、どちらもテキストの正規化において非常に重要ですが、課題が ないわけではありません。これらのテクニックの精度は言語によって異なり、英語のアルゴリズムは比較的成熟しています。屈折形、品詞のニュアンス、自然言語固有のあいまいさによって、このタスクは自明ではなくなります。
結論
ステミングとレンマタイゼーションは、この分野の基礎技術である。 自然言語処理.技術が進歩し、ChatGPTなどのツールがより洗練されるにつれて、正確に理解し、処理することの重要性が増しています。 セマンティック 言葉の本質は増える一方です。センチメント分析に深入りするにしても、次世代のチャットボットを開発するにしても、これらの正規化テクニックをきちんと把握することは不可欠です。
よくあるご質問
ステミングとレンマタイゼーションとは?
ステミングとレンマタイゼーションはいつ使うのか?
公開日: 2022-03-28
更新日: 2024-07-30