It can be very frustrating when you’re trying to crawl a website and suddenly see the timeout or 403 Forbidden error message. What do you do when you encounter the most common on-page messages on your screen: HTTP status code errors, bad requests, internal server errors, or HTTP response “no response” errors? How can you fix it? In this blog post, we’ll explain the 403 Forbidden error and provide some solutions to fix it. Stay tuned!

Table of Contents
What is a 403 Forbidden Error?
The 403 Forbidden status code is a server-side error indicating that the server refuses to fulfill the request. This can be due to several reasons, including but not limited to: the request is being made for a resource that does not exist, the user does not have sufficient permissions to access the requested resource or the server is configured to block requests from the user’s IP address.
Regardless of the reason, a 403 Forbidden error will prevent the user from accessing the requested resource. In some cases, the server may provide a redirect to another page or resource that can be accessed; in other cases, the user will need to contact the website owner or administrator to resolve the issue. Either way, a 403 Forbidden error frustrates any user who encounters it.
How to fix 403 forbidden status code error in Screaming Frog
The Page Doesn’t Exist / Broken Links / Canonical Mismatch

Plausible cause 1: The request is being made for a resource that does not exist.
Before troubleshooting server configurations or security settings, confirm the page actually exists. Open the URL directly in your browser — if you get a 404 or the page doesn’t load at all, the problem isn’t a 403 block. The resource simply isn’t there.
This is more common than you’d think. Screaming Frog discovers URLs from internal links, sitemaps, and redirects — including links to pages that have been deleted, moved, or never properly published. If the URL returns a 403 instead of a 404, the server may be configured to hide non-existent resources behind a generic forbidden response for security reasons (this is common with Apache and Nginx hardened configurations).
What to do:
– Open the exact URL from Screaming Frog in your browser to verify the page is accessible.
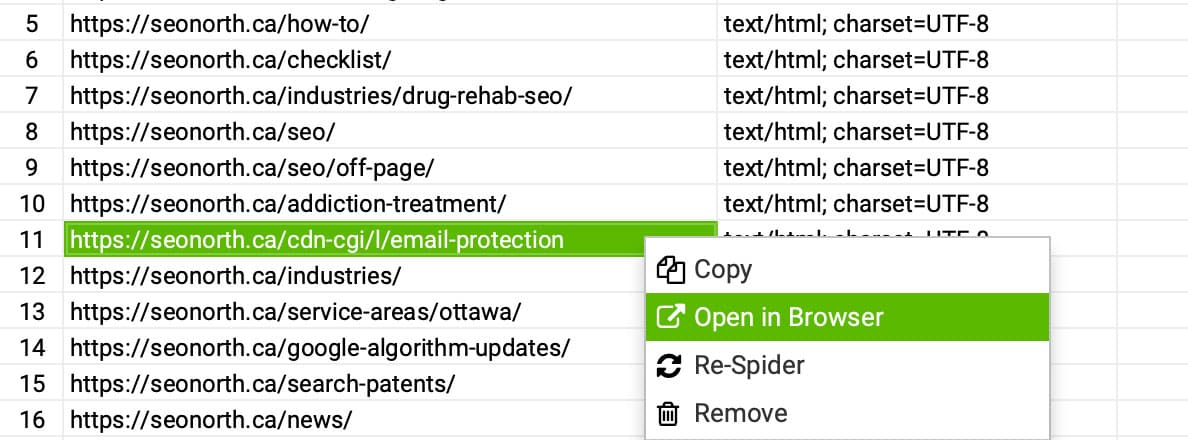
– If the page doesn’t exist, trace where Screaming Frog found the URL — check the Inlinks tab to see which pages are linking to it.
– Fix or remove the broken internal links pointing to the non-existent URL.
– If the page was intentionally removed, make sure it returns a proper 404 or 410 status code, or set up a 301 redirect to the most relevant replacement page.Authentication Required

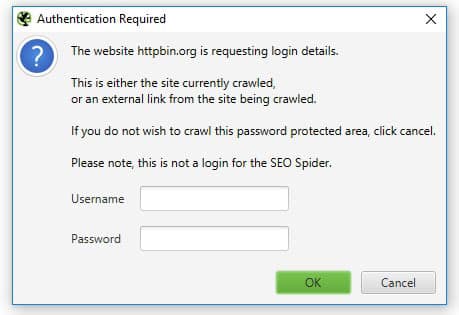
Plausible cause 2: The page requires authentication to access.
Some pages are behind a login wall — member areas, staging environments, client portals, robots.txt rule, or WordPress draft/preview pages. When Screaming Frog hits these URLs without the right credentials, the server returns a 403 because the crawler isn’t authenticated.
What to do:
– If the page is password-protected and you need to crawl it, go to Configuration > Authentication in Screaming Frog and enter the required credentials. Screaming Frog supports Basic, Digest, and NTLM authentication. For form-based logins (like a WordPress login page), you’ll need to use the Forms Based Authentication option under the same menu.
– If the protected pages don’t need to be crawled (staging environments, admin areas, draft content), exclude them from your crawl entirely. Go to Configuration > Exclude and add URL patterns like
/wp-admin/or/staging/to skip them.– For sites behind HTTP authentication (the browser popup that asks for username and password), enter those credentials in Screaming Frog’s authentication settings before starting the crawl.
The Server is blocking you

Plausible cause 3: The server is configured to block requests from the user’s IP address.
If the webpage is viewable on your computer using a browser, this means the website is blocking the bot (crawler) and is an isolated event.
Lower Crawl Speed

If the page loads in your browser but Screaming Frog gets a 403, the issue is almost always server-side security software blocking the crawler. This is the most common cause of 403 errors in Screaming Frog, and it’s worth understanding what’s actually happening before jumping to fixes.
Web application firewalls (WAFs) and security plugins are designed to detect and block automated traffic. They look at signals like request frequency, user-agent strings, missing cookies or JavaScript execution, and IP reputation. Screaming Frog triggers several of these signals simultaneously — it sends rapid requests, uses a known bot user-agent, doesn’t execute JavaScript by default, and doesn’t carry session cookies. From the server’s perspective, this looks a lot like an attack.
Common security layers that cause this:
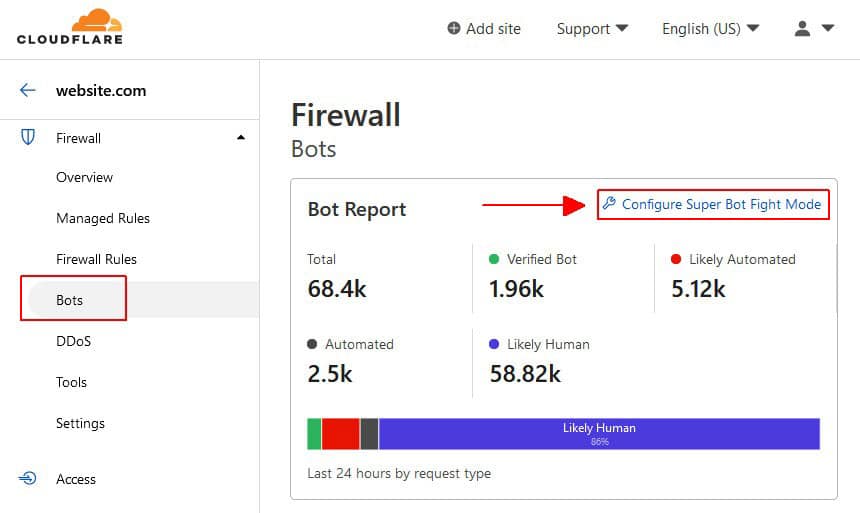
– Cloudflare — Bot management and rate limiting will block Screaming Frog if the site’s security level is set to medium or higher. Cloudflare’s “Under Attack Mode” will block virtually all automated crawlers.
– Wordfence — The rate limiting feature blocks IPs that exceed a threshold of requests per minute. Screaming Frog’s default crawl speed will often trip this.
– Sucuri — Similar to Cloudflare, Sucuri’s WAF blocks requests that don’t pass its bot detection checks.
– ModSecurity — Server-level WAF rules (common on cPanel/WHM servers) that block suspicious request patterns.
– Fail2Ban — Monitors server logs and automatically bans IPs that show suspicious patterns like rapid-fire requests.Understanding which layer is blocking you will determine the right fix. If you manage the server, check your security plugin and WAF logs first — they’ll usually tell you exactly what triggered the block.
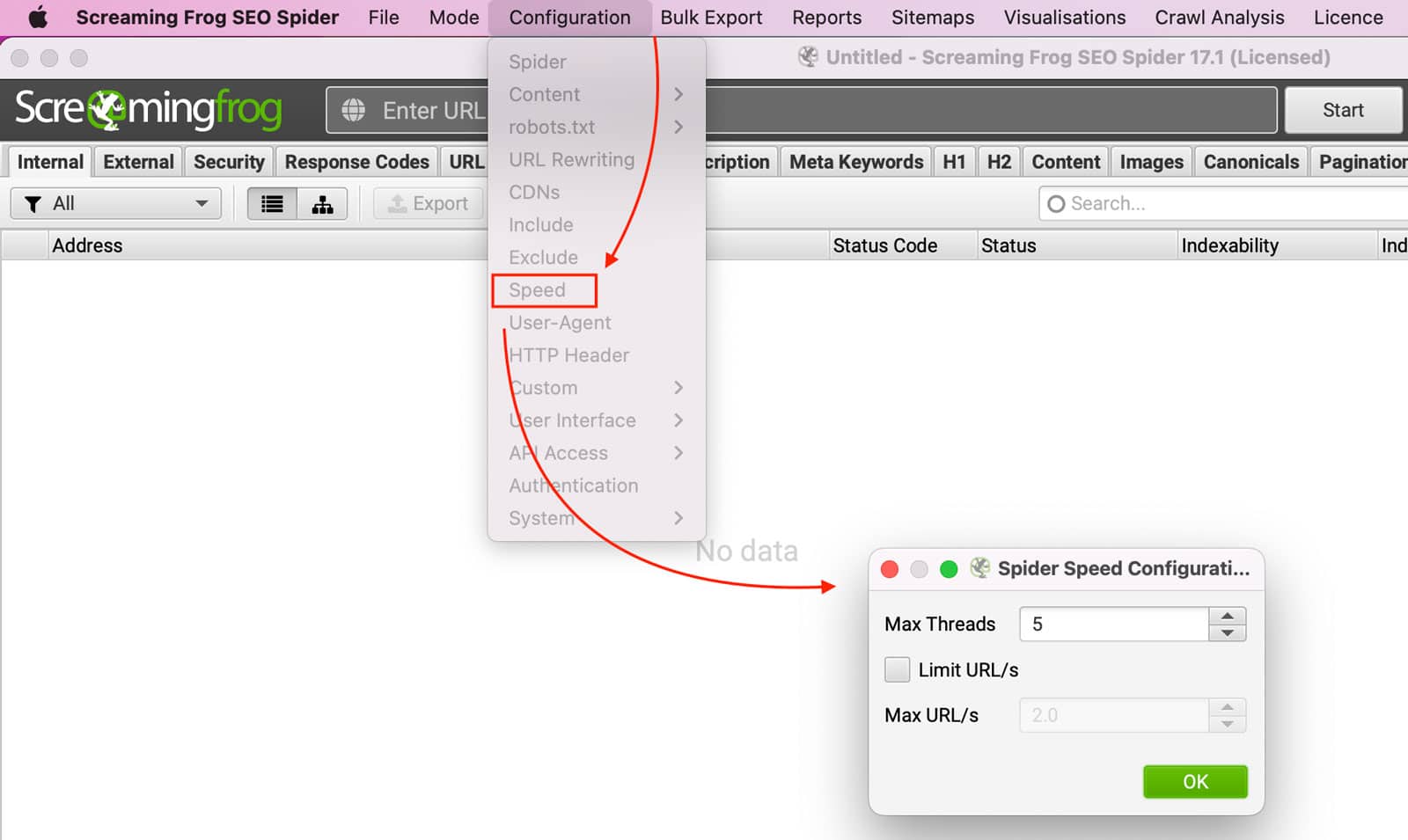
Solution 1: You might have the spider setup to crawl too fast and too aggressively.
To fix aggressive scans, you will need to lower the crawl rate:
Configuration >> Speed >> Spider Speed Configuration
Lowering your crawl rate will increase the time it takes to perform scans and reduce the server resources load.
Change the User-Agent

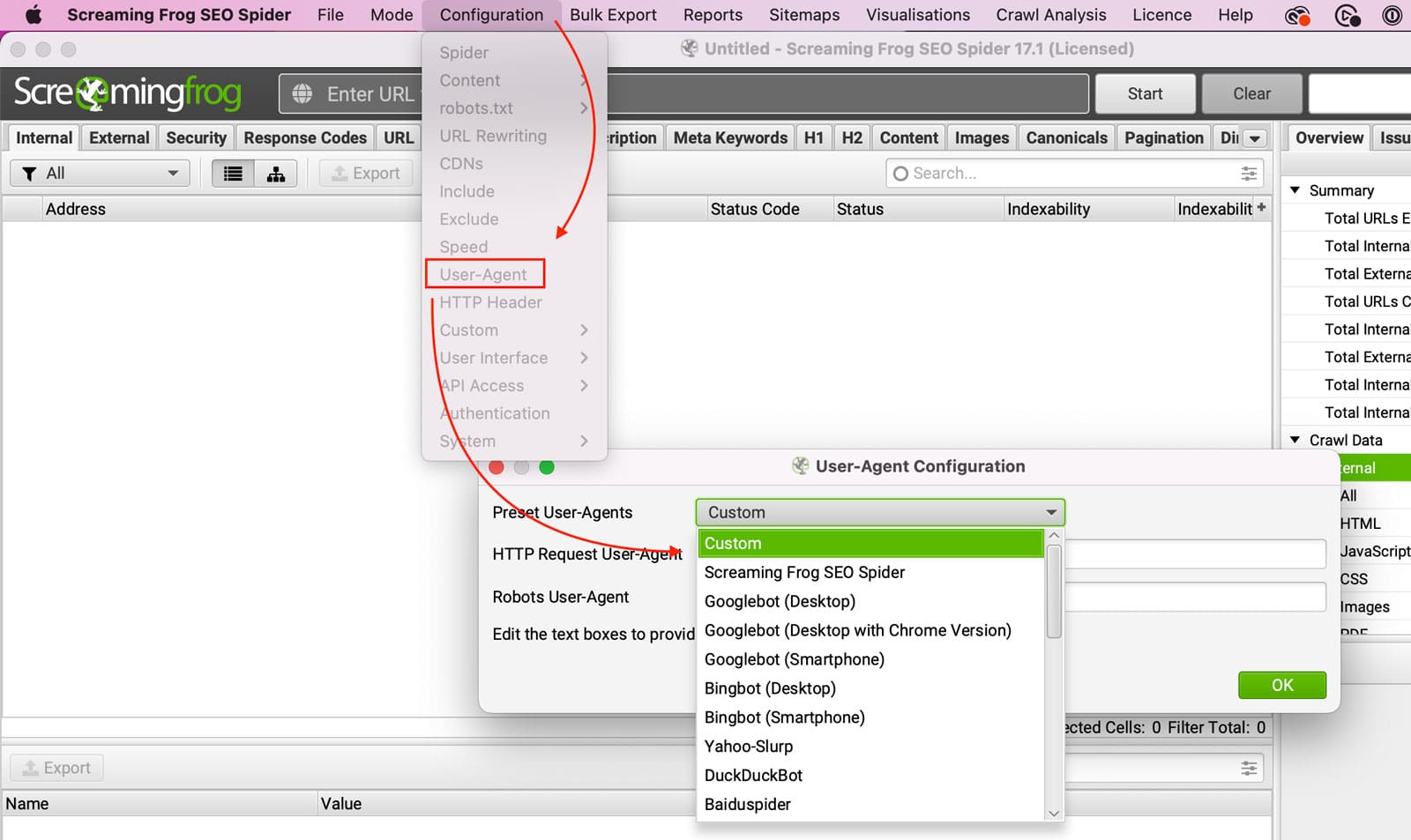
Solution 2: Change the User-Agent to mimic a real browser.
If the server is blocking the default Screaming Frog user-agent, switching to a browser user-agent often resolves the issue immediately. Go to Configuration > User-Agent and select a preset.
Recommended user-agents to try, in order:
1. Chrome — The safest option. Most servers and WAFs whitelist Chrome’s user-agent string since it represents the majority of real web traffic.
2. Googlebot — Most sites are configured to allow Googlebot access. However, some sophisticated WAFs verify Googlebot requests via reverse DNS lookup, so a fake Googlebot user-agent may still be blocked.
3. Custom — If neither works, you can set a fully custom user-agent string. Copy a current browser user-agent from your own browser’s developer tools (Network tab > request headers) for the most up-to-date string.Important: If switching to Googlebot solves the 403 but Chrome doesn’t, that tells you the server is specifically blocking non-search-engine bots. This is useful diagnostic information — it means the site’s SEO crawlability for actual search engines is fine, and the 403 is purely a Screaming Frog access issue.
Change your IP

Solution 3: Change your IP address
The server could be blocking your IP address, so trying the crawl from a different internet service provider is best.
Try the crawl from home if you are at work and want to change your IP address. If you are at home, try a coffee shop with good internet. If you can’t leave, try tethering your computer to your phone. Changing locations will help you troubleshoot and determine if your IP is blocked.
Whitelist your IP

Solution 4: Whitelist your IP address on the Server or Website
You can whitelist your IP address with the website, server, or DNS server where possible.
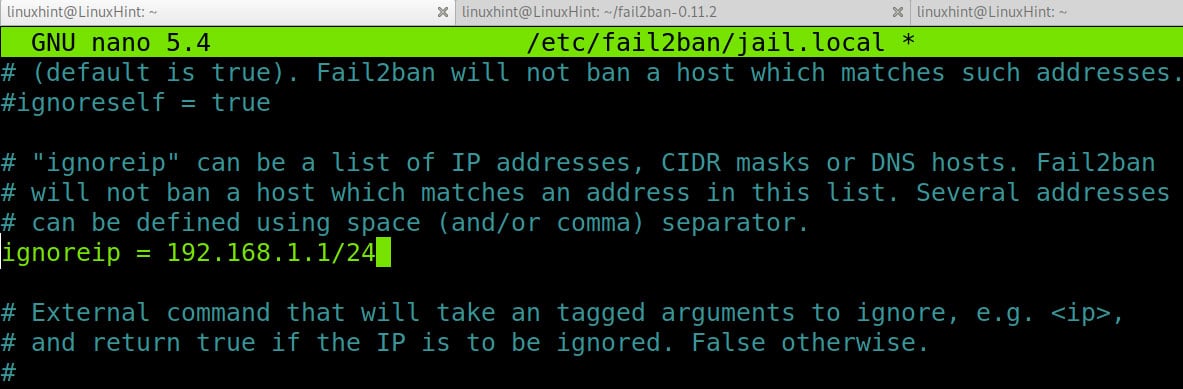
The options are endless, but a few security services blocking your crawl could be: Wordfence, CloudFlare, and Fail2Ban; if you are unaware of any security software running, it’s best to consult with your IT department.

Conclusion
A 403 Forbidden error in Screaming Frog usually isn’t an SEO emergency — it’s a crawler access issue. If the page loads in your browser and Google Search Console’s URL Inspection confirms Googlebot can reach it, your rankings aren’t at risk.
When troubleshooting, work through the solutions in order of effort: lower your crawl speed first, then try switching the user-agent to Chrome or Googlebot, and check whether a CDN like Cloudflare or a security plugin is blocking the crawler based on HTTP headers or request patterns. If you’re crawling a large site with subdomains or complex subfolder structures, you may need to whitelist your IP at the server level to avoid repeated blocks.
For a full picture of which URLs are returning 403s, use the Response Codes tab in Screaming Frog to filter by status code and bulk export the results. Cross-reference those URLs with your Inlinks report to identify any internal links pointing to blocked pages that need to be cleaned up. If you’re using JavaScript rendering mode and still seeing 403s, the server may be blocking the additional requests Screaming Frog makes to render the page — the same WAF and rate-limiting fixes apply.
Don’t hesitate to contact us if you’re still running into issues. We’re happy to help with your technical SEO.
FAQs
Are 403 errors bad for SEO?
Why does Screaming Frog get a 403 when my browser loads the page fine?
Will a 403 error in Screaming Frog affect my Google rankings?
Published on: 2022-09-01
Updated on: 2026-03-09