对于技术搜索引擎优化而言,Screaming Frog SEO Spider 是一个必要的工具。它可以帮助识别网站错误以及网站搜索引擎优化的潜在改进领域。但它能抓取 JavaScript 吗?答案是肯定的!在本篇文章中,我们将介绍如何使用蜘蛛抓取 JavaScript 内容,以及在尝试抓取时可能出现的一些常见问题。让我们开始吧!

尖叫蛙可以爬行Javascript吗?
是的。 尖叫的青蛙 可以抓取Javascript网站。下面包括如何使用的详细说明。 尖叫蛙SEO蜘蛛抓取 JavaScript网站。
配置 >> 蜘蛛

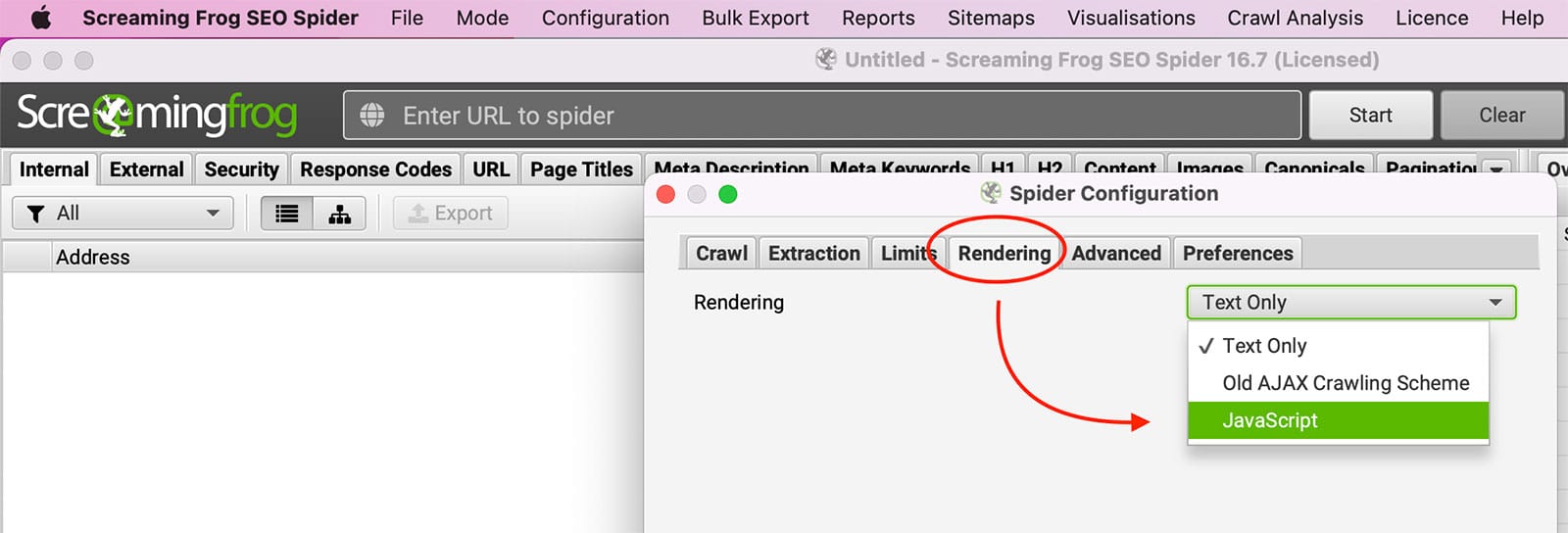
要抓取Javascript网站,您必须在Screaming Frog中启用Javascript渲染选项。
要启用JavaScript渲染,你需要点击 配置 在导航菜单中,点击 蜘蛛 选择。
蜘蛛配置窗口

一旦蜘蛛配置窗口打开,你将需要点击 渲染图 标签,然后选择 ǞǞǞ 在下拉菜单中。
总结
为了最大限度地利用你的Screaming Frog SEO Spider,必须了解如何使用它来抓取JavaScript网站。蜘蛛是任何SEO的重要工具,可以帮助识别你的网站上潜在的改进领域。
您是否尝试过使用Screaming Frog来抓取一个JavaScript网站?您的经验是怎样的? 请在下面的反馈中告诉我们.
常见问题
Screaming Frog 能否有效地抓取 JavaScript 以捕获渲染的 HTML?
发表于:2022-06-07
更新日期: 2024-04-10