TL;DR – N-Gram analysis in NLP refers to the study of contiguous sequences of n items (typically words or characters) from a given text to capture linguistic patterns, improve language models, and aid in tasks like text prediction and processing.
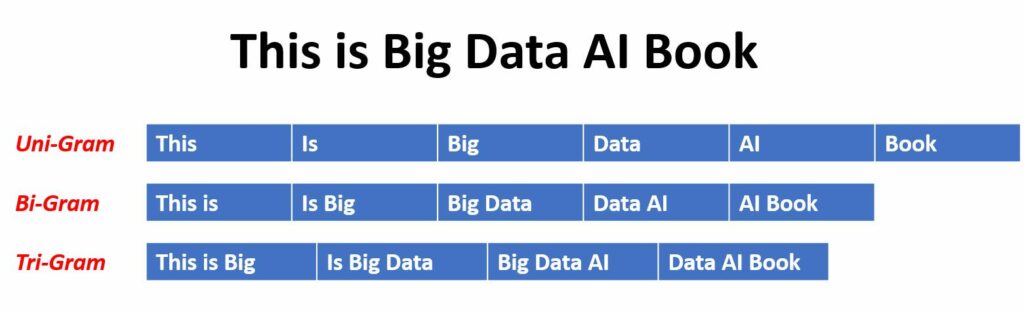
Table of Contents
N-Gram Analysis in SEO and Text Analytics
An n-gram, prevalent in the realms of data science and computer science, is a contiguous sequence of n items from a given sample of text or speech. It can consist of individual words, numbers, symbols, or punctuation. This means a unigram consists of a single word, a bigram involves two words, and a trigram comprises three words. The power of n-grams, whether they’re unigram, bigram, or trigram models, has been harnessed in various applications of text analytics, especially where sequences of words, like stopwords or keywords, are critical, such as in sentiment analysis, text classification, text mining, and even machine translation.
Applications
N-gram models serve as probabilistic language models, predicting the next word in a sequence based on the preceding words, essentially functioning as an (n − 1)–order Markov model. These models are indispensable in machine learning, computational linguistics, NLP, and deep learning tasks for tasks like speech recognition. Their wide applicability spans probability, communication theory, computational biology, and data compression. Their beauty lies in their simplicity and scalability. For instance, a trigram model, considering the previous two words, might predict the probability of the next word in a sequence, giving a more contextual and refined prediction.
Examples
Using the Google n-gram corpus, here are some examples of word-level 3-grams and 4-grams along with the number of times they appeared:
3-grams:
- ceramics collectibles collectibles (55)
- ceramics collectibles fine (130)
- ceramics collectible pottery (50)
4-grams:
- serve as the independent (794)
- serve as the indicator (120)
- serve as the incoming (92)
Text Mining and Conversions
In the context of SEO, n-grams are instrumental in understanding the frequency and relevance of keywords within web content. By analyzing the dataset of web pages using n-gram models, particularly bigram and trigram models, digital marketers can glean insights into which keyword combinations drive the most conversions. This can then inform keyword optimization strategies, enhancing the page’s visibility on search engines.
Conclusion
N-gram models, incorporating parameters like the number of words or the sequence of n words, are invaluable in text analytics. By employing tools like NLTK and other machine learning libraries, one can efficiently generate n-grams, delve into their metrics, and uncover deeper insights from text data. With the advent of tutorials, open-source tools, and platforms like Jupyter and GitHub, implementing n-gram analysis has never been more accessible for enthusiasts in artificial intelligence and NLP.
FAQs
How do you create N-Grams?
What is N-Gram analysis in SEO?
Published on: 2022-03-28
Updated on: 2023-10-08