如何设置Screaming Frog只抓取一个子文件夹。
如何设置Screaming Frog只抓取一个子文件夹。
本博文将讨论如何使用尖叫青蛙仅抓取子文件夹。我们将介绍如何设置 Screaming Frog 并将其配置为抓取网站上的特定文件夹。这是审核特定网站部分或排除某些页面问题的绝佳工具。让我们开始吧!
如何在Screaming Frog中抓取一个子文件夹?
蜘蛛模式

将Screaming Frog设置为蜘蛛模式,并输入你希望抓取的网站URL。
套装包括

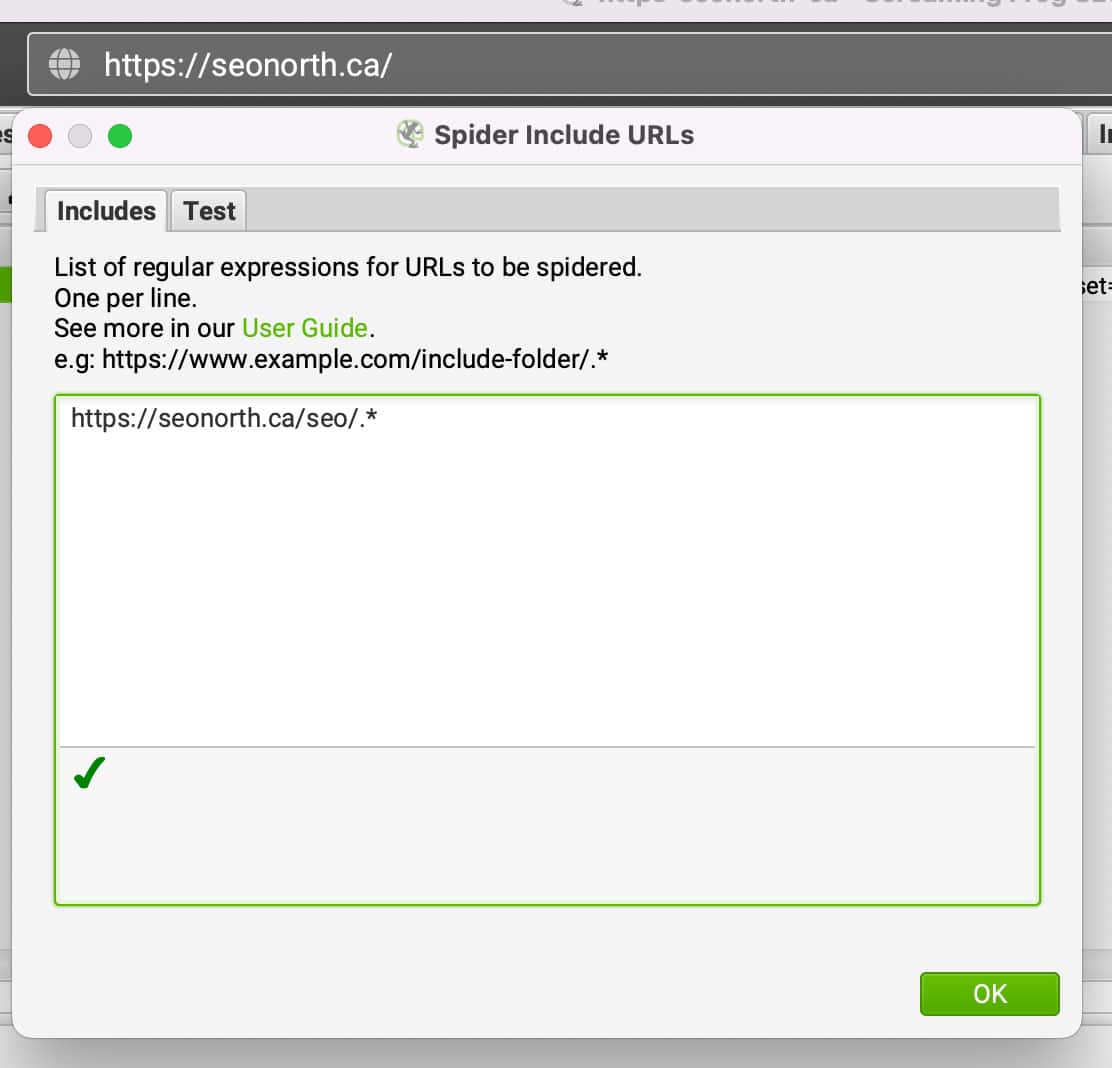
在顶部的导航菜单中,转到 配置 >>然后点击 包括 在下拉菜单中。
输入您希望抓取的子文件夹,后面是句号和星号,使Regex只抓取该文件夹。
如: https://seonorth.ca/seo/.*
如果URL是正确的,你会看到模式底部有一个复选标记符号。
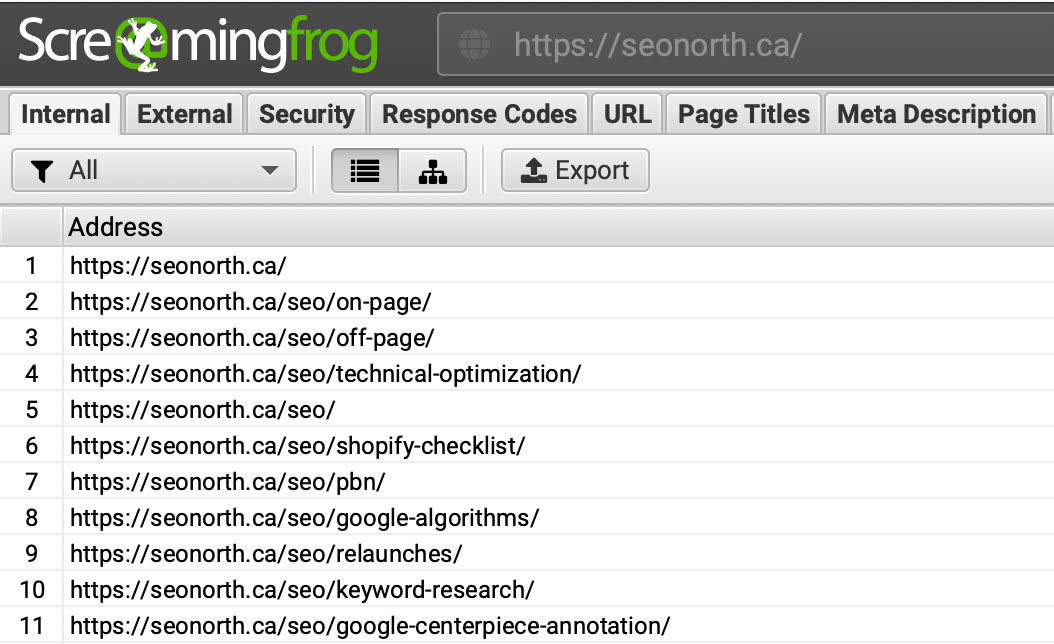
查看结果

在Screaming frog中按下启动键,观察它对网站的抓取;你可以监控抓取过程,看它是否只抓取了那个文件夹。
另外,你可以将尖叫蛙设置为 排除特定的子文件夹 通过前往 配置 >> 排除 在顶部导航中。
总结
现在你知道如何 爬行 子文件夹,将这些知识用于您的网站。Screaming Frog 对于任何搜索引擎优化工具包来说都是必不可少的,它可以帮助您发现网站的关键数据。利用从 Screaming Frog 收集到的信息来提高网站性能并提升搜索引擎排名。您还发现了哪些其他有用的方法?请在下面的评论中告诉我们。
常见问题
什么是 "尖叫蛙"?
Screaming Frog 是一款功能强大的网站爬虫工具,用于分析和审核网站的各种搜索引擎优化因素和技术问题。
Screaming Frog 如何处理 JavaScript?
Screaming Frog 现在可在抓取网站时渲染 JavaScript,从而可对依赖 JavaScript 实现内容或功能的网页进行更全面的分析。
Screaming Frog 可以检测断开的链接吗?
是的,Screaming Frog 可以在抓取过程中识别断开的链接(404 错误)、重定向链以及与网站链接相关的其他问题。
什么是内部链接,Screaming Frog 如何提供帮助?
内部链接是指同一网站内网页之间的链接。Screaming Frog 的 "内部 "选项卡可帮助用户深入了解网站的内部链接结构,帮助用户了解网页之间是如何相互连接的。
Screaming Frog 支持抓取子域吗?
是的,Screaming Frog 可以抓取子域,只要它们在同一个根域内。
在哪里可以找到使用 Screaming Frog 的教程?
Screaming Frog 在其官方网站上提供全面的教程和指南,涵盖工具的各种特性和功能。
什么是规范 URL,Screaming Frog 能识别它们吗?
规范 URL 用于表示网页的首选版本。Screaming Frog 可以检测规范标签并帮助识别规范化的潜在问题。
Screaming Frog 可以抓取 HTML 和 CSS 内容吗?
是的,Screaming Frog 可以抓取和分析网页上的 HTML 和 CSS 内容。
如何确保我的网站可被 Screaming Frog 索引?
Screaming Frog 可帮助用户深入了解元 robots 标签、noindex 指令等可索引性问题,确保网站被搜索引擎正确索引。您还可以将用户代理更改为 GoogleBot,查看 Google 抓取您网站的能力。
Screaming Frog 是否与 Ahrefs 或 Google Analytics 等其他工具集成?
虽然 Screaming Frog 没有与 Ahrefs 或 Google Analytics 等工具直接集成,但它提供了多种导出选项(如 CSV、Google Sheets),允许用户将多个来源的数据结合起来进行综合分析。
我可以使用 Screaming Frog API 自动执行任务吗?
是的,Screaming Frog 提供 API,允许用户自动执行任务、提取数据并将 Screaming Frog 与其他工具或脚本集成。
如何使用 Screaming Frog 在开始文件夹之外爬行?
Screaming Frog 允许用户通过调整 "配置 "部分的设置来指定自定义抓取配置,包括在初始启动文件夹之外进行抓取。
Screaming Frog 支持自定义提取数据吗?
是的,Screaming Frog 提供自定义搜索和提取功能,允许用户使用 XPath、CSS 路径或 Regex 对网页中的特定数据元素进行数据提取。
Screaming Frog 如何帮助识别重复内容?
Screaming Frog 的 "重复内容 "功能可识别内容相似或相同的页面,帮助用户解决可能对搜索引擎优化产生负面影响的重复内容问题。
Screaming Frog 可以分析 Google Analytics 数据吗?
虽然 Screaming Frog 不能直接分析 Google Analytics 数据,但它可以与 Google Analytics 结合使用,将网站分析数据与抓取过程中收集到的搜索引擎优化技术见解联系起来。
Screaming Frog 如何处理用于搜索引擎优化分析的 JavaScript 渲染?
Screaming Frog 的 JavaScript 渲染功能使其能够像现代浏览器一样渲染网页,让用户能够分析 JavaScript 生成的内容及其对搜索引擎优化的影响。
Screaming Frog 抓取的 URL 数量有限制吗?
Screaming Frog 可抓取的 URL 数量取决于许可证类型(如免费、付费)和用户机器上的可用资源。付费版本的 Screaming Frog 可提供更高的 URL 限制和附加功能。
Screaming Frog 如何在抓取过程中处理响应代码?
Screaming Frog 提供在抓取过程中遇到的 HTTP 响应代码的详细信息,帮助用户识别 404 错误、重定向和服务器错误等问题。
Screaming Frog 是否尊重 robots.txt 指令?
是的,Screaming Frog 默认尊重 robots.txt 指令,但用户可根据需要调整设置以忽略 robots.txt 规则。
如何在Screaming Frog中抓取一个特定的文件夹?
要让 Screaming Frog SEO Spider 在开始文件夹之外抓取:在 Screaming Frog 顶部的导航菜单中,转到配置 >> 然后点击下拉菜单中的 "包含"。输入您要抓取的子文件夹 URL。
发表于:2022-09-26
更新日期: 2024-04-05
Isaac Adams-Hands是SEO North公司的SEO总监,该公司提供搜索引擎优化服务。作为一名搜索引擎优化专家,Isaac在网页搜索引擎优化、非网页搜索引擎优化和技术性搜索引擎优化方面拥有相当丰富的专业知识,这使他在竞争中占据了优势。