Google’s Reasonable Surfer Model is a search engine algorithm that promotes transparency and fairness in the ranking of websites. This model provides more helpful information for searchers by considering content relevance, link quality, and user signals. This post will explore how Google uses these factors to rank websites in their search results pages.

Table of Contents
- What is the Reasonable surfer model?
- What is the Random surfer model?
- Why did the Reasonable Surfer Model replace the Random Surfer Model?
- How is the Reasonable Surfer Model different?
- PageRank under the Random Surfer Models
- How PageRank uses the Reasonable Surfer Model
- Did this article answer your questions?
What is the Reasonable surfer model?
The Reasonable Surfer Model is an updated algorithm to the initial Random Surfer Model. It looks at various click probabilities based on characteristics associated with those links.
What is the Random surfer model?
The Random Surfer Model is a graph model that describes a random user’s probability of clicking on a link to visit a web page.
Why did the Reasonable Surfer Model replace the Random Surfer Model?
The reasonable surfer model was more accurate at calculating the probability of link clicks.
How is the Reasonable Surfer Model different?
The Reasonable Surfer Model is a refreshed version of the initial Random Surfer Model.
The differences are that the Reasonable Surfer Model looks at:
- The probabilities involve the likelihood that a person might click upon specific links based on associated link features.
- These probabilities can determine how likely it might be that someone might click upon those links.
These updates are stated in the Patent continuation:
… a rank for a particular document, generating the rank including determining particular feature data associated with a link to the particular document, the particular feature data identifying one or more attributes of the link, determining a weight indicating a probability of the link being selected, the weight is determined based on the particular feature data and selection data, the selection data identifying user behavior relating to links to other documents … the weight indicating a higher probability of the link being selected when the particular feature data corresponds to feature data associated with the one or more links than when the particular feature data corresponds to feature data associated with the one or more other links … words in anchor text associated with the links, and a quantity of the words in the anchor text
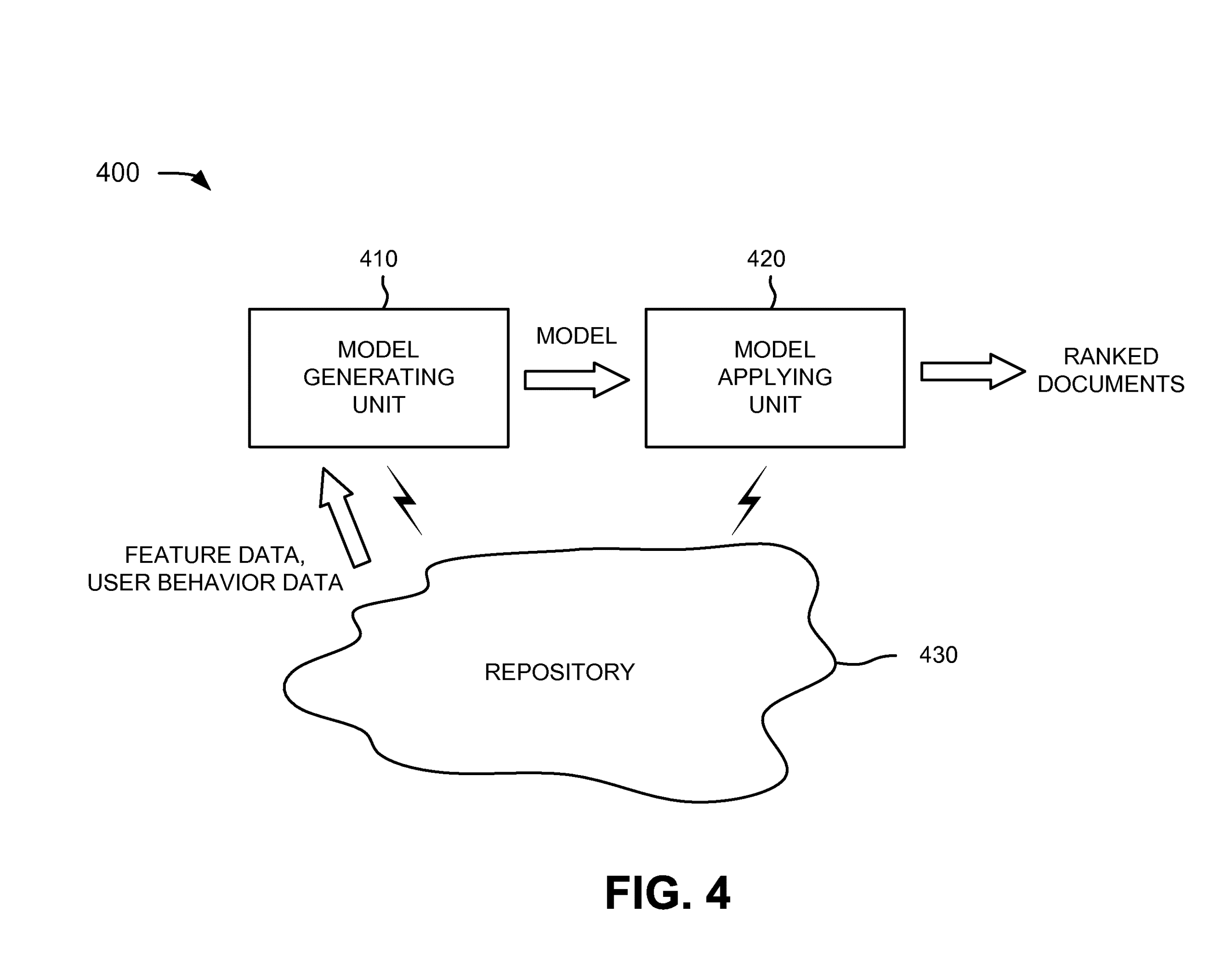
Ranking documents based on user behavior and/or feature data
You can see that featured data and anchor text play a significant role in the Reasonable Surfer Model.
The Reasonable Surfer Model looks at the probability of links being clicked based on link features. In contrast, the Random Surfer Model looked at the likelihood of random links clicked based on average traffic.
This means it’s no longer a “random” probability but now a “reasonable” probability of links being clicked.
PageRank under the Random Surfer Models
Google’s PageRank algorithm is based on the Random Surfer Model, where it ranks webpages on the probability that a user following website links (at random) might arrive on a specific page:
The page’s rank can be interpreted as the probability that a surfer will be at the page after following many forwarding links. The constant α in the formula is interpreted as the probability that the web surfer will jump randomly to any web page instead of following a forward link.
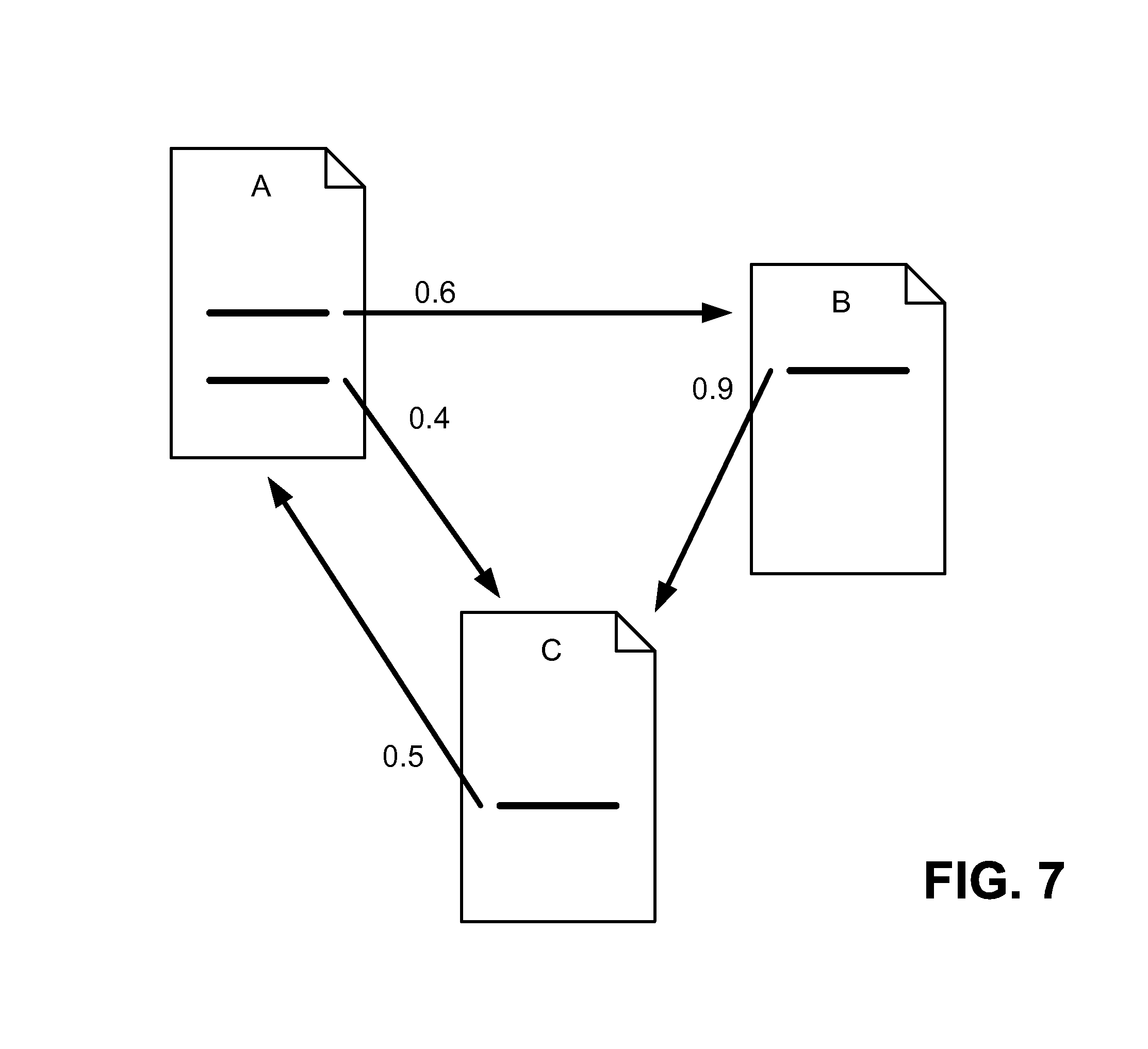
Systems and methods consistent with the principles of the invention may provide a reasonable surfer model that indicates that when a surfer accesses a document with a set of links, the surfer will follow some of the links with higher probability than others. This reasonable surfer model reflects that not all of the links associated with a document are equally likely to be followed. Examples of unlikely followed links may include “Terms of Service” links, banner advertisements, and links unrelated to the document.
Ranking documents based on user behavior and/or feature data
How PageRank uses the Reasonable Surfer Model
The Reasonable Surfer Model can be used to calculate the amount of PageRank a link might pass; based on whether or not a person will click on it.
Reasonable Surfer Model link features can include a wide range of factors, such as:
- Fonts, Colours, and Sizes that help the link stand out
- Captivating Anchor text
- Having the link in the content area of the page
- Other factors in attracting a user’s attention to click
Factors that might lower PageRank distribution:
- Link Placement low on the page (like in the footer of the page)
- Links with the same color as the text on the page
- Links with similar font type
- Unappealing Anchor Text
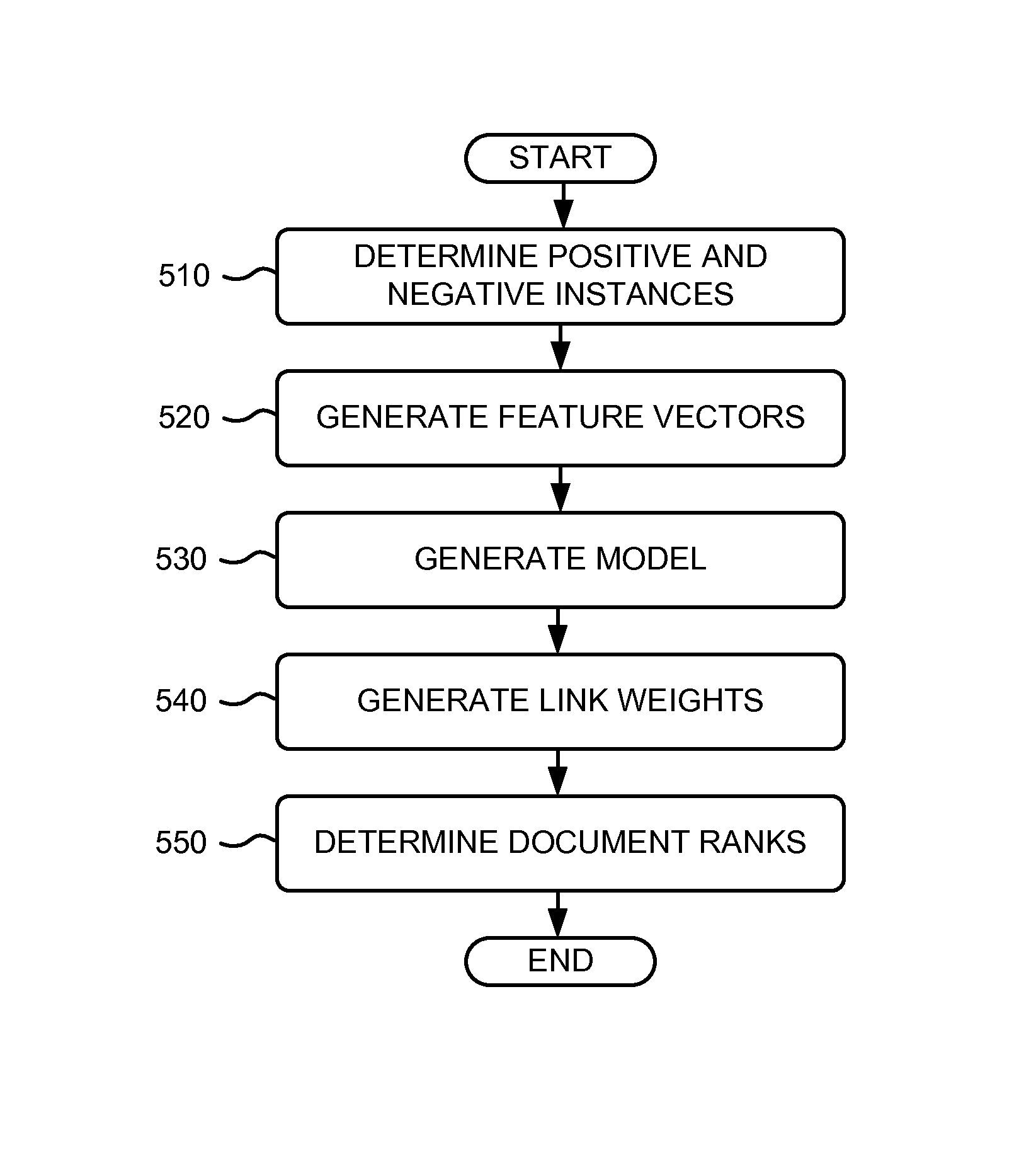
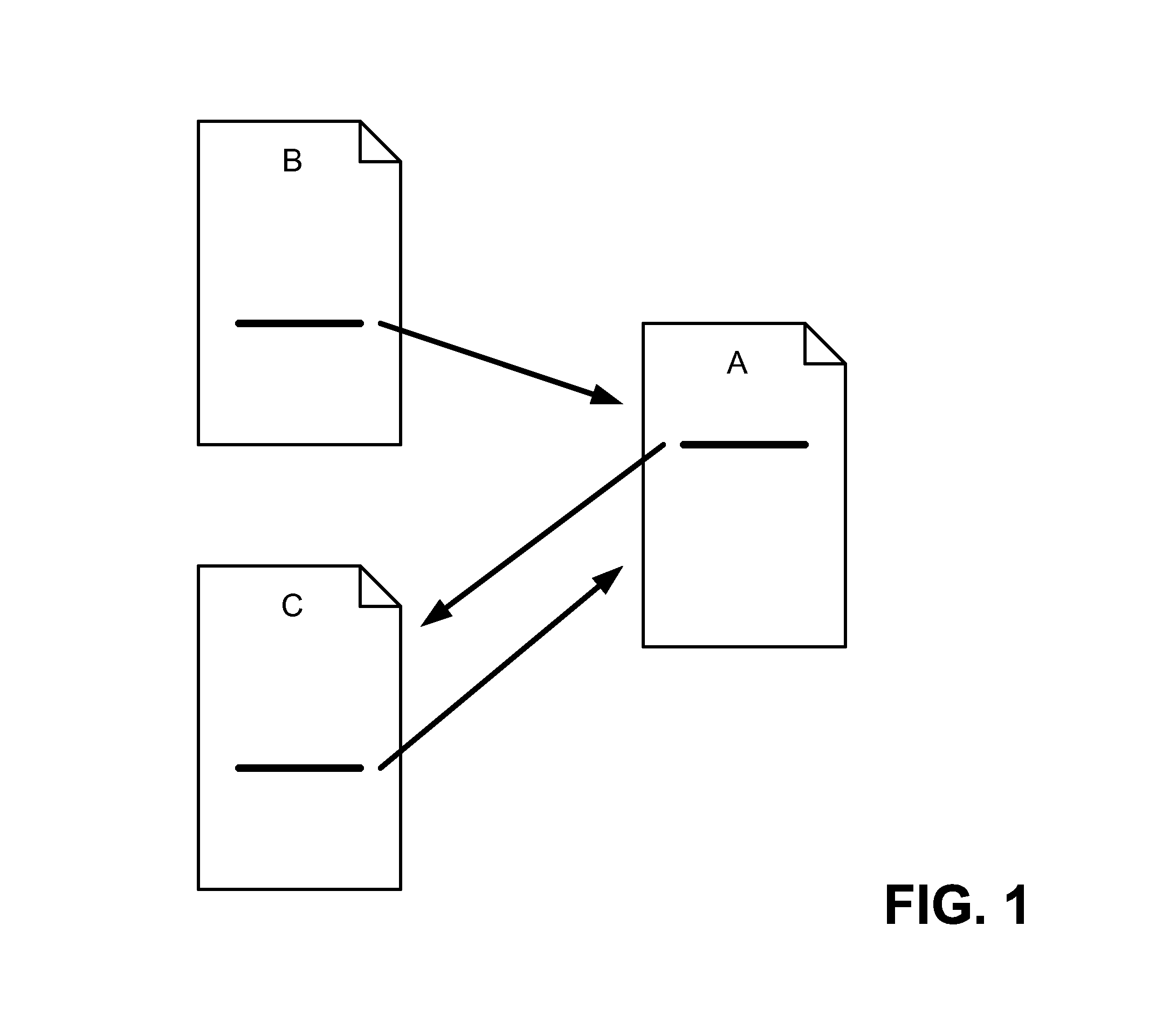
The updated “Reasonable Surfer Model” Patent can be found at:
Ranking documents based on user behavior and/or feature data
Inventors: Jeffrey A. Dean, Corin Anderson, and Alexis Battle
Assigned to: Google
US Patent 9,305,099
Granted April 5, 2016
Filed: January 10, 2012
Abstract
A system generates a model based on feature data relating to different features of a link from a linking document to a linked document and user behavior data relating to navigational actions associated with the link. The system also assigns a rank to a document based on the model.
Ranking documents based on user behavior and/or feature data
Credit must be given to Bill Slawski; I started reading his articles and found them too advanced, so I started re-writing them to understand the patents better. Please check out his blog for a more advanced understanding of these patents.
Published on: 2021-05-25
Updated on: 2022-10-28
