TL;DR – Word Sense Disambiguation provides the ability to determine which word meaning is activated by using a word in a particular context.
“The bank will not be accepting cash on Saturdays.”
“The river overflowed the bank.”
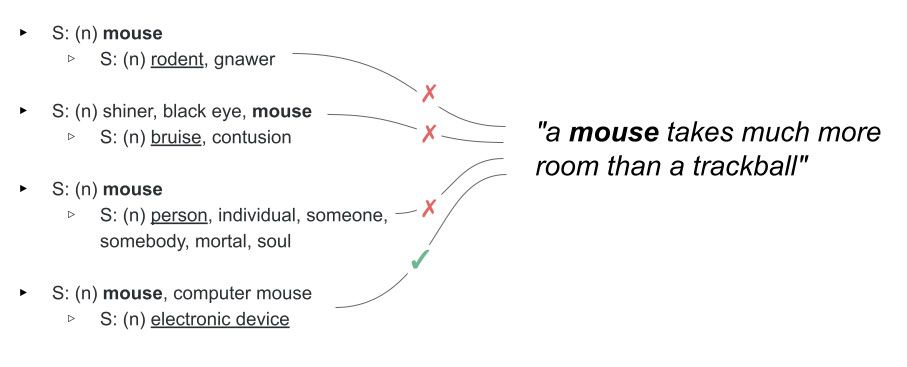
Table of Contents
Word Sense Disambiguation in Natural Language Processing
Word Sense Disambiguation (WSD) is a crucial area within natural language processing (NLP) that deals with the challenge of determining the correct sense of an ambiguous word within a given context. In the English language, many words have different senses or meanings, and selecting the right one based on the surrounding text is crucial for tasks such as information retrieval, machine translation, and information extraction.
Historical Background and Importance:
The importance of WSD in the field of computer science and artificial intelligence can be traced back to early works in lexical semantics and lexicography. Since words in the English language and other languages can be polysemous (having multiple meanings), resolving their correct sense in different contexts is crucial for maintaining semantic clarity.
Datasets and Tools:
Over the years, various corpora and datasets have been used for WSD tasks. Seminal datasets like Senseval-2 and Senseval-3 have provided annotated corpora for both lexical sample tasks, where a target word’s sense is identified, and all-words tasks, where every word’s sense in a text is determined. These datasets, along with other resources such as WordNet – a lexical database – and various knowledge bases, have formed the backbone for the development and evaluation of WSD systems.
Algorithms and Approaches:
There are primarily three approaches to WSD: supervised, unsupervised, and knowledge-based.
- Supervised Methods: These require annotated corpora (training data) to train a classifier, like support vector machine (SVM), using features derived from the context of the ambiguous word. The classifier then predicts the sense of the word based on the training set. The effectiveness of supervised systems often depends on the richness of the training corpus and the selection of relevant features.
- Unsupervised Methods: These do not rely on annotated data. Instead, methods like unsupervised word sense disambiguation or word sense induction exploit patterns in large corpora, using lexical semantics, semantic similarity, and relatedness to identify senses. The success of unsupervised methods, as observed by researchers like Agirre and Edmonds, often rests on the quality of the lexical resources and the parameters selected.
- Knowledge-based Methods: These leverage external knowledge sources, like thesauri or semantic networks. One of the foundational algorithms is the Lesk algorithm, which considers the overlap of dictionary definitions (or glosses) to disambiguate senses. The performance of such methods depends on the depth and breadth of the knowledge base used.
Evaluation and Current State of the Art:
WSD systems have been routinely evaluated in international conferences like the Association for Computational Linguistics (ACL) and COLING. SemEval-2007, for instance, was a notable event where different WSD methods were benchmarked. Current state-of-the-art approaches often combine machine learning with rich lexical resources and knowledge bases.
Researchers like Yarowsky, Navigli, Palmer, Miller, Mihalcea, Pedersen, Fellbaum, Véronis, Stevenson, and many others have made significant contributions to this field. Their combined efforts have progressively improved the baseline accuracy of WSD systems, advancing the boundary of human language technology.
Challenges and Future Directions:
Despite advancements, challenges remain. The frequent sense baseline, where the most common sense of a word is always selected, remains a tough competitor. This highlights the importance of incorporating more nuanced lexical semantics and dependency parsing to understand context better. Moreover, multilingual WSD and the use of WSD in machine translation are areas that promise significant research avenues.
Conclusion:
WSD is a testament to the intricate nature of human language. As we move towards a future where machines understand language nuances as well as humans, the field of WSD, rooted in the crossroads of computer science, artificial intelligence, and lexicography, will continue to be of paramount importance.
FAQ
What is Word Sense Disambiguation?
Published on: 2022-03-28
Updated on: 2024-05-07