TL;DR – Semantic clustering is the process of grouping data based on its semantic meaning or content similarity.
Natural Language Processing (NLP), an interdisciplinary domain nestled between linguistics and data science, continually seeks methods to structure and understand vast amounts of textual data. Among these methods, semantic clustering has emerged as an essential tool to organize and segment textual content based on meaning.
Table of Contents
Understanding Semantic Clustering
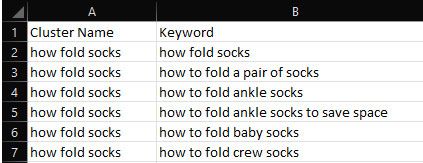
Semantic clustering, as the name suggests, revolves around grouping data based on its semantic similarity rather than just syntactic similarity. In essence, it brings together pieces of text with similar meaning, even if they don’t use the same words.
Why is it Important?
With the proliferation of datasets in NLP, there’s an increasing need to categorize this data efficiently. By using semantic clustering, machine learning models can better discern the intents behind user inputs or categorize full texts into different clusters based on their underlying themes, greatly enhancing data analysis.
How Does It Work?
- Embedding: The first step involves encoding the textual data into a numerical form. Advanced algorithms, especially transformer models like BERT, have facilitated creating rich embeddings that capture semantic content.
- Clustering Algorithm: Once encoded, clustering algorithms group the embeddings based on their semantic similarity. Common clustering methods include hierarchical and iterative techniques. The choice of the clustering approach often depends on the nature of the dataset and the desired number of clusters.
- Optimization & Validation: Determining the right number of clusters is pivotal. Metrics and validation strategies are employed to ensure the clusters formed are coherent and distinct.
Applications:
- Segmentation: Breaking down large texts or datasets into coherent segments based on their topics.
- Intent Classification: In chatbots, determining the underlying intent of user queries by grouping them into specific intent clusters.
Current State and Research:
State-of-the-art methods, often presented at international conferences like ACL and IEEE, are pushing the boundaries of semantic clustering. Open access platforms like arXiv and Google Scholar are teeming with research on optimizing clustering algorithms, knowledge-based approaches, and exploring new clustering metrics.
Researchers like Wang and Zhang have contributed significantly to the field, enhancing clustering algorithm efficiency and the precision of semantic similarity measures.
Conclusion
Semantic clustering, a cornerstone in NLP, is crucial for artificial intelligence and data science professionals working with large textual datasets. With continuous advancements and a deeper understanding of both the English language and other languages, it’s an area poised for significant growth and innovation.
As the world of NLP expands, tutorials, and knowledge-sharing on platforms like Google Scholar, combined with new research available on arXiv, will undoubtedly lead the way, ensuring the ever-evolving world of linguistics and artificial intelligence remains intertwined.
FAQ
What is Semantic Clustering?
What is Semantic Clustering in SEO?
Published on: 2022-03-28
Updated on: 2024-11-06