TL;DR – Part-of-speech (POS) tagging is a popular Natural Language Processing process that refers to categorizing words in a text (corpus) in correspondence with a particular part of speech, depending on the definition of the word and its context.
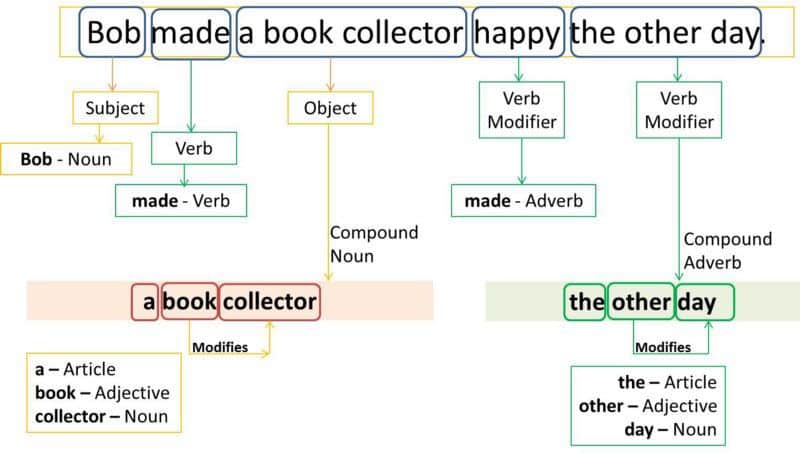
One of the foundational steps in Natural Language Processing (NLP) is understanding the grammatical structure of a sentence. This is where Part-of-Speech (POS) tagging comes into play, categorizing words into their respective grammatical categories.
Table of Contents
Introduction to POS Tagging
Part-of-speech tagging, often abbreviated as POS tagging, involves labeling each word in a sentence with its appropriate grammatical tag. Whether it’s distinguishing an adverb from an adjective or discerning between a proper noun and a determiner, POS tagging provides a glimpse into the syntactic and to some extent, the semantic structure of a sentence.
Why is it Important?
POS tagging is crucial in many NLP tasks:
- Parsing sentences to understand their structure.
- Lemmatization, where words are reduced to their base form.
- Disambiguation, ensuring that the correct meaning of a word is chosen based on context.
- Dependency analysis, which explores how words in sentences relate to one another.
Common POS Tags:
- Nouns (NNP, PRP): Represent entities, with NNP being a proper noun and PRP a personal pronoun.
- Verbs (VBP, VBN, VBD, VBZ): Denote actions or states. VBP stands for a verb in present tense, VBN for a past participle, VBD for past tense, and VBZ for a verb in the 3rd person.
- Adjectives (ADJ): Describe nouns or pronouns.
- Adverbs: Modify verbs, adjectives, or other adverbs.
- Prepositions: Indicate relationships between words.
- Interjections: Express strong feelings or sudden emotions.
- Determiners (WDT): Introduce nouns and provide context.
- Coordinating Conjunctions: Connect words or groups of words.
- Cardinal Numbers (NUM): Represent quantity.
Algorithms & Tools
Several algorithms have been employed for POS tagging:
- Stochastic Methods: Hidden Markov Model (HMM) is a popular method where the likelihood of a word being a specific tag depends on the previous tags and the given word.
- Rule-Based Methods: The Brill Tagger is a classic example, which uses an iterative method to refine its tags.
- Machine Learning Approaches: These include Decision Trees and Neural Networks, trained on corpora like the Penn Treebank.
For those delving into English NLP with Python, the Natural Language Toolkit (NLTK) offers tools for POS tagging. The ‘word_tokenize’ function can be used to split a sentence into individual words (or tokens), which can then be labeled using NLTK’s built-in part-of-speech tagger.
Challenges and the Way Forward
While significant progress has been made, challenges remain:
- Unknown Words: Words not present in the training set (often new or infrequent words) can be problematic.
- Ambiguity: A single word might have multiple tags depending on its role in different sentences.
- Granularity: The chosen tagset, whether coarse or fine-grained, can impact accuracy.
With advancements in machine learning and the availability of extensive datasets and tutorials, POS tagging’s accuracy continues to improve. Moreover, integrating stemming, lemmatization, and semantic analysis can further refine the process.
Conclusion
Part-of-Speech tagging remains a pivotal step in the NLP pipeline, paving the way for advanced linguistic and computational analyses. As technology and research advance, the efficiency and accuracy of POS taggers will only augment, reinforcing their integral role in language processing.
FAQ
What is Part-of-Speech tagging example?
What is Part-of-Speech tagging techniques?
Published on: 2022-03-28
Updated on: 2024-11-06